다나와 데브옵스 OJT 진행과정
소개 : OJT(On the Job Training)
이전과 다른 새로운 환경에서 시작할 때가 있습니다. 처음부터 변화된 환경에서 수월하게 적응한다면 이상적이겠지만 낯선 곳에서 출발해서 궤도에 이르기까지 어느정도 시간이 필요할 것입니다. 따라서 현장에선 채용 후 바로 실무에 투입하는 것이 아닌 구성원의 이해와 적응을 돕도록 OJT를 실시하고 있습니다.
OJT란 직무중에 실시하는 일련의 교육 과정을 의미합니다. 다나와에서는 입사 후 세 달에 걸쳐 직무 교육을 실시하고 있는데요. 오늘 다뤄볼 주제는 어떻게 OJT가 진행되고, 어떤 과정이 있는지, 각 과정의 목표와 의미에 중점을 두어 설명하는 내용을 다뤄보겠습니다.
진행 일정(Devops)
| Week | Course | Contents |
|---|---|---|
| Week 1 | 적응 기간 | 회사 소개 구성원 소개 사원증 발급 |
| Week 2 | 적응 기간 | EIP 사용법 가이드 OJT 진행일정 수립 개발 준비 Docker, ELK stack 실습 |
| Week 3 | DEV 1차 | 개발환경 셋팅 IDE 프로젝트 개발 코드 리뷰 |
| Week 4 | DEV 1차 | IDE 프로젝트 개발 단위 테스트 코드 및 프로젝트 리뷰 |
| Week 5 | OPS 1차 | AWS, elasticsearch 활용 ES Cluster 구성 검색 서버 구축 |
| Week 6 | OPS 1차 | Rabbit MQ 구축 데이터 색인 진행 검색페이지 개발 준비 코드 및 프로젝트 리뷰 |
| Week 7 | DEV 2차 | 검색 페이지 개발 검색 API 다루기 검색 조건 구현 |
| Week 8 | DEV 2차 | 검색 페이지 개발 정렬, 부스팅, 어그리게이션 적용 코드 및 프로젝트 리뷰 |
| Week 9 | DEV 3차 | IDE 프로젝트 고도화 Reverse froxy 적용 사용자별 환경설정 셋팅 구현 |
| Week 10 | DEV 3차 | IDE 프로젝트 고도화 cypress E2E test 진행 프로젝트 개선 코드 및 프로젝트 리뷰 |
| Week 11 | OPS 2차 | Grafana, Prometheus 활용 모니터링 시스템 구축 커스텀 메트릭 작성 OJT Project 연동 |
| Week 12 | OPS 2차 | InfluxDB 활용 로그 수집 및 분석 대시보드 구성 프로젝트 리뷰 및 마무리 |
주요 과정 설명과 목표
OJT는 총 12주차에 걸쳐 진행됩니다. 이 기간동안 실제로 실무에서 다루고 있는 언어와 기술 스택을 활용하여 개발을 진행합니다. 진행시 지도자와 책임자가 함께 구성이 되어 각 과정마다 설명과 리뷰를 진행하며 개발 시 이슈사항이나 코드들을 점검하며 평가가 이뤄집니다.
데브옵스의 경우 DEV 과정과 OPS 과정 두 가지로 이원화하여 격주로 진행되는데요. DEV 과정에서는 직접 실무와 관련된 프로젝트를 구현해보면서 자연스럽게 기술을 이해할 수 있도록 돕습니다. 혼자 힘으로 해결하면 좋겠지만 중간중간 도움이 필요할 경우 지도자에게 도움을 요청하여 함께 해결하는 방법도 좋습니다.
OPS 과정의 경우 검색 시스템과 모니터링 시스템을 구축하는 것이 주된 목표입니다. 다른 곳에서는 이런 기술에 대해 접해볼 기회가 많이 없기 때문에 새로운 스택을 직접 구축해보면서 시스템이 어떻게 동작하고 있는지 파악할 수 있는 과정입니다. 이렇게 DEV 과정과 OPS 과정을 완료하면 OJT 과정이 종료됩니다.
OJT Devtools

OJT 참가자는 OJT를 진행하면서 여러 기술을 접하게 됩니다. 어쩌면 이미 다뤄보거나 접해봤던 기술일수도 있겠습니다. 이 내용들을 OJT 기간동안 접해보면서 시스템의 설계부터 테스트, CI/CD까지 진행하게 됩니다. 프론트엔드의 경우 react를 주로 사용하고 백엔드 개발 시에는 node를 사용하거나 필요한 언어를 하나 선택해서 개발하게 됩니다. 또 유용한 라이브러리를 사용할 수도 있습니다.
검색 시스템 구축에선 elk stack, 모니터링에서는 prometeus, grafana와 같은 도구를 사용합니다. 이외에도 aws, docker와 같은 기술을 활용하면서 실무에 필요한 것들을 직/간접적으로 익히면서 접근하는 과정이 진행됩니다. 그리고 과정이 종료될 때마다 피드백이 이뤄지면서 보완해야할 사항이나 개선점들을 파악하면서 각 단계가 완료됩니다.
OJT 프로젝트 개발 샘플 자료
실제 OJT 과정에서 개발했던 내용들을 정리했습니다. 작성 코드는 팀 깃허브에 공유되어 있습니다. 아래의 내용을 참고하여 OJT 기간동안 어떤 내용이 다뤄지고 있는지 참고하면 좋겠습니다.
(1) OJT IDE
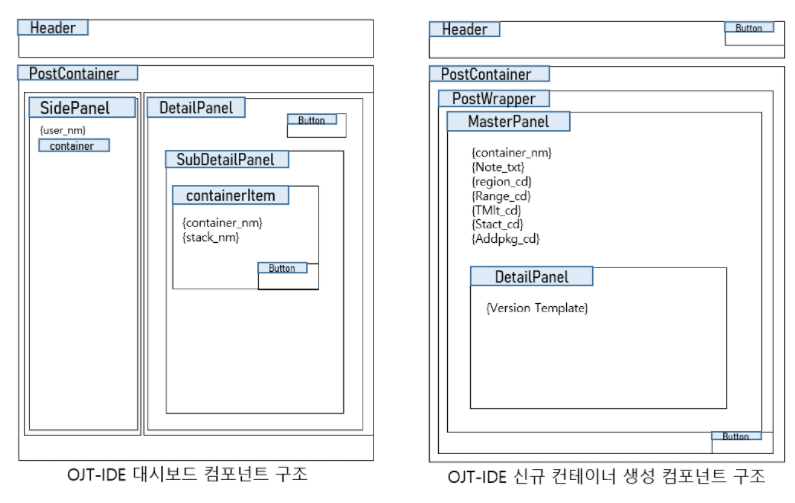
OJT-IDE의 화면 레이아웃은 다음과 같습니다. 이 페이지에서는 기존 생성된 컨테이너를 선택해 IDE 터미널에 접속할 수 있습니다. 또한 컨테이너를 삭제하거나 생성 페이지로 이동하여 새로운 가상환경을 만들 수 있습니다. 신규 컨테이너 생성 화면은 컨테이너에 필요한 이름, 내용, 리전의 위치, 템플릿, 소프트웨어 스택과 같은 다양한 값을 입력하는 화면으로 구성됩니다.
React의 특징중 하나는 컴포넌트를 통해 구현된다는 점입니다. 상위 컴포넌트가 하위 컴포넌트에 인자를 전달하여 기능이 수행됩니다. OJT IDE는 이 구조를 충족하기 위해 각각 페이지가 PostContainer라는 상위 계층에서 각각의 하위 계층에게 데이터를 전달하도록 설계했습니다. 데이터의 통신 방향은 단방향 통신으로 이루어집니다.
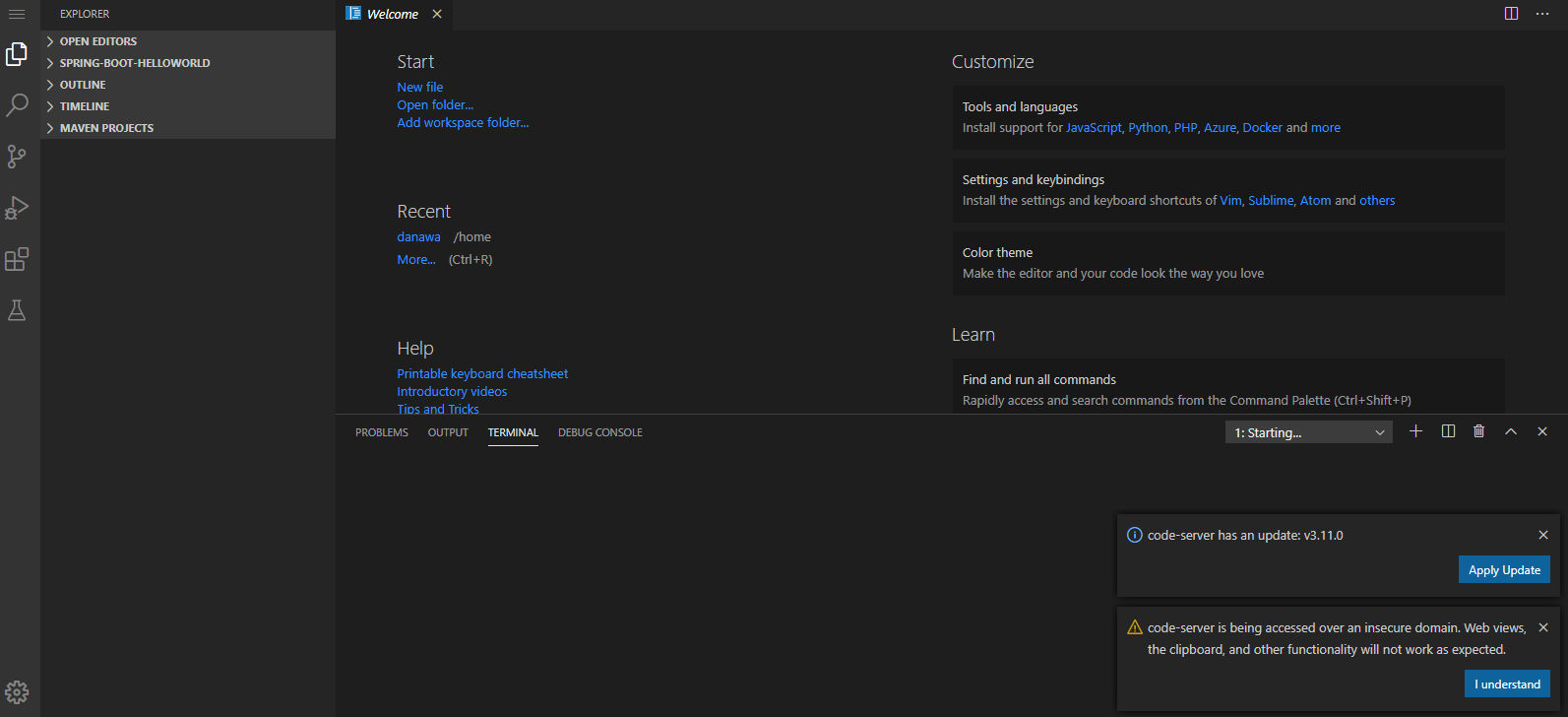
IDE는 별도의 가상 공간을 제공하여 개발자가 언제 어디서든 개발할 수 있도록 가상의 컨테이너를 제공합니다. 터미널을 실행하면 작업 환경에 코드서버가 설치되어 있고 내 로컬 컴퓨터와 독립된 가상환경에서 코드를 작성할 수 있습니다.
기본적으로 로그인 & 회원가입, 컨테이너 생성, 정지, 시작, 삭제와 같은 컨테이너 기능을 제공합니다. 기본 동작은 다음과 같이 진행됩니다. 사용자가 UI를 통해 특정 기능을 호출하면 서버쪽에서 이를 수신해서 Express를 사용해 DB와 연결합니다.
또한 도커와도 연결하는데, 이는 컨테이너를 통해 터미널 기능인 Code-Server(CDR)를 사용하기 때문입니다. 이렇게 생성된 컨테이너의 ID를 전달받아서 컨테이너 정보 테이블에 저장하거나 터미널을 오픈할때 Docker를 통해 할당받은 포트로 접속하게 됩니다.
터미널 오픈 시 브라우저를 통해 터미널이 오픈되고 GIT 프로젝트를 클론하거나, 새로 파일을 만들어서 프로젝트를 시작할 수 있습니다. 컨테이너를 사용하다가 정지를 하더라도 삭제하지 않는 이상 내용은 보존됩니다. 만약 작성한 코드를 실행해보고 싶다면, 생성시 최대 4개 까지 컨테이너와 연결된 포트를 추가 제공하고 있어서 해당 포트를 이용하여 결과를 확인할 수 있습니다.
(2) OJT SEARCH PAGE
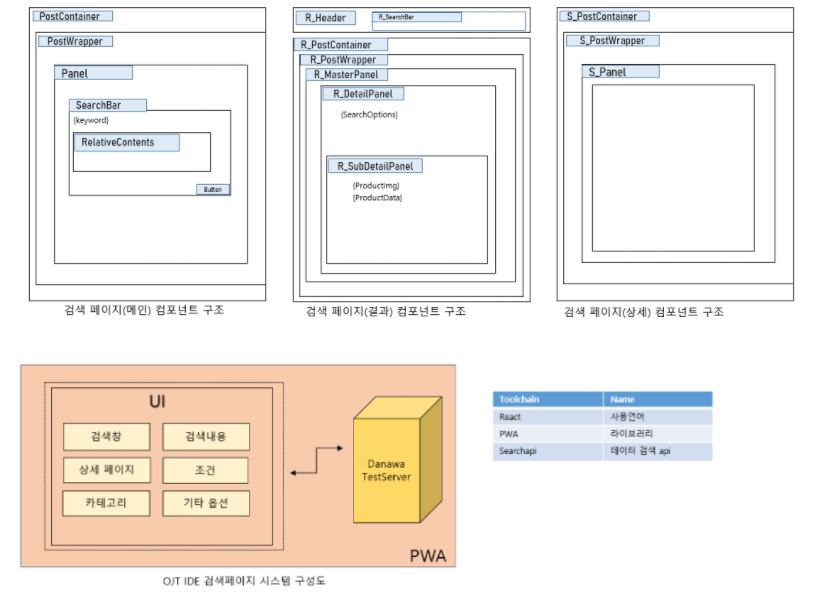
검색페이지 시스템은 다음과 같이 구성됩니다. 검색창을 통해 검색되는 내용이 각 페이지의 사이즈에 맞게 표시됩니다. searchApi를 통해 색인된 데이터에 접근하여 각 필드에 해당하는 데이터를 가져오며 가져온 데이터를 적절히 파싱하여 원하는 결과값이 도출됩니다.
모바일 디바이스에서는 PWA라고하는 라이브러리를 적용하여 마치 하나의 앱처럼 동작할 수 있도록 합니다. 이를 통해 웹과 앱 두가지 방식으로 검색페이지 서비스를 제공합니다.
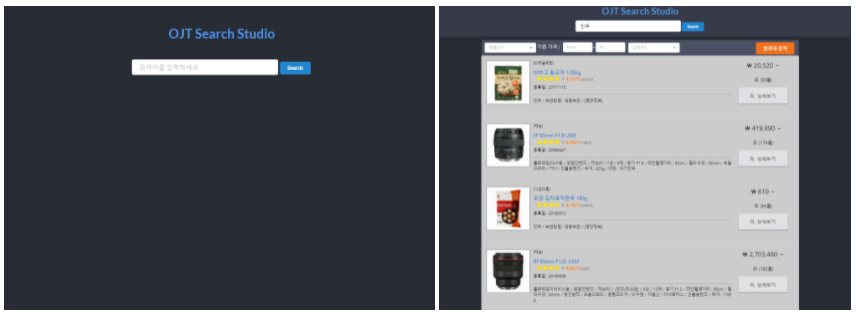
상품 조회 api인 searchapi를 활용하여 제작한 검색 페이지입니다. 검색 시 기본적인 상품정보(최저가격, 평점, 리뷰수, 등록일, 상세정보)등을 제공합니다. 이 때 데이터는 검색 조건에 따라 정렬순, 기준가격, 검색갯수, 결과내 검색과 같은 조건에 부합하는 데이터가 조회됩니다.
상세보기 클릭시 제품의 상세 정보와 내용이 표기되며 구매 시 다나와 페이지로 이동되는 특징이 있습니다. UI 오픈소스 라이브러리인 simantic ui react를 사용해서 개발을 진행했습니다. 이미 컴포넌트들이 완성되어 있어서 필요시 관련 컴포넌트를 호출하여 데이터를 셋팅하는 방식으로 개발되었습니다.
(3) OJT monitor
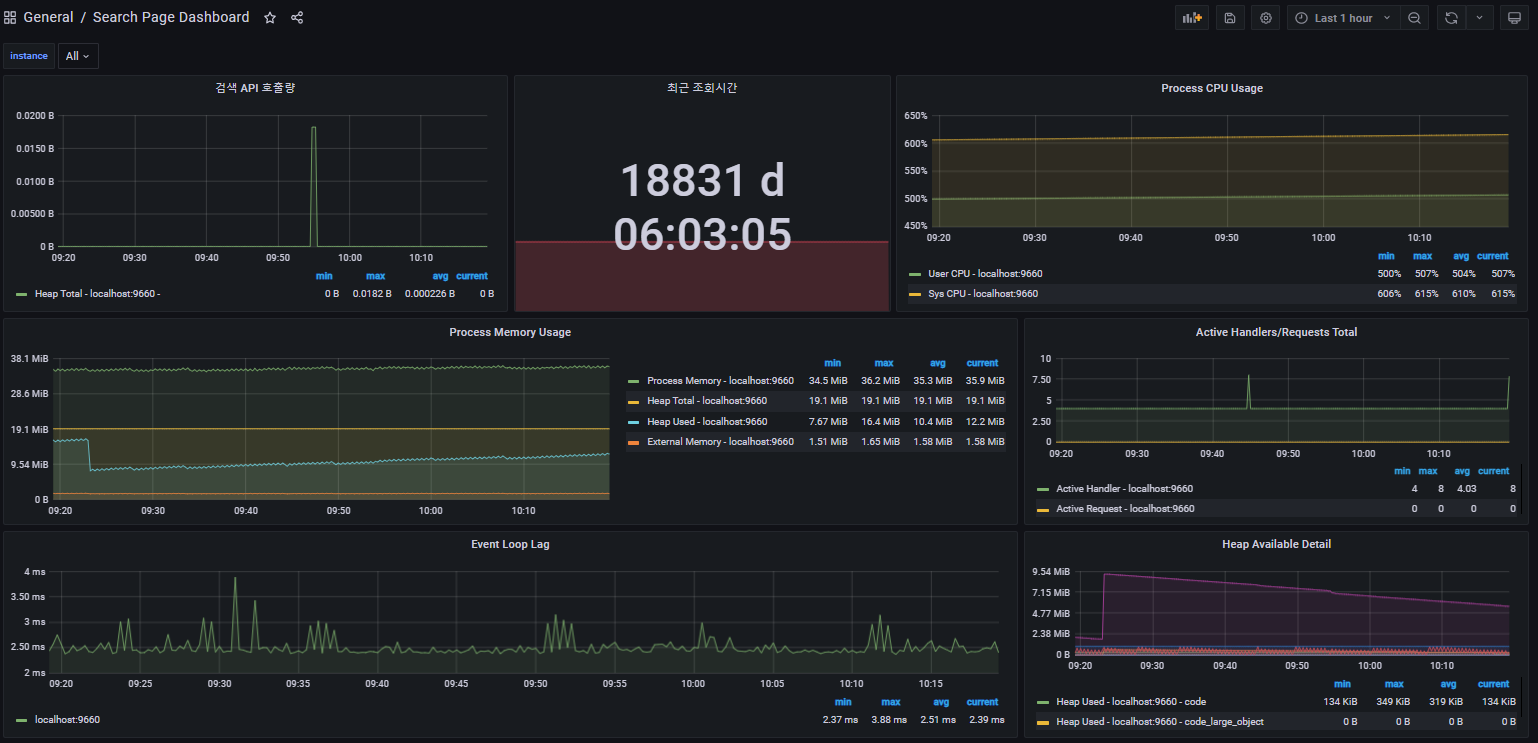
그라파나, 프로메테우스는 시스템의 현재 상태를 모니터링하는 도구입니다. OJT 동안 개발했던 시스템을 모니터링하기 위해 도입했습니다. 이를 이용하여 실시간으로 시스템의 상태를 파악할 수 있습니다.
이를 위해 익스포터를 통해 시스템에서 프로메테우스로 매트릭을 노출했고프로메테우스에서는 매트릭을 가공, 처리, 저장하여 그라파나에 전달됩니다. 그리고 전달된 내용은 다시 대시보드를 통해 시각화됩니다.
(4) OJT indexing
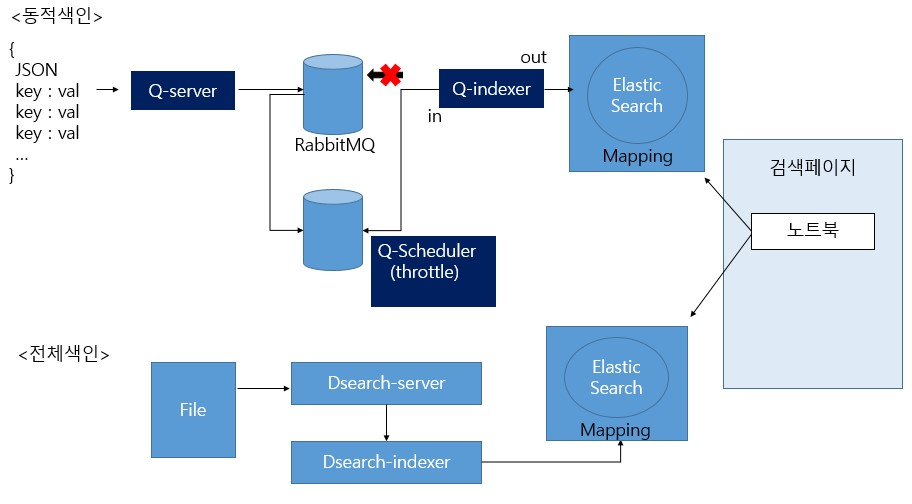
전체색인은 입력된 파일을 인덱싱하는 과정으로 ELK스택과 도커를 사용하여 현재 운영되고 있는 시스템을 모의로 구축해봤습니다. 프로세스를 살펴보면 1.2gb 정도되는 검색 데이터 파일을 전달받아 서버에서 인덱서로 전달하고 ES에 색인 내용을 매핑합니다. 매핑된 데이터는 searchApi를 통해 다룰 수 있으며 검색할 수 있습니다.
동적색인은 색인된 데이터를 수정하거나 새로 색인을 추가할때 사용합니다. JSON 형식으로 Q시리즈에 요청합니다. Q시리즈에는 서버, 스케쥴러, 인덱서가 존재합니다. rabbitMq는 통신의 중간에 메시지를 전달해주는 메시지 브로커 역할을 하고 여기서 적재된 내용이 쌓여서 Q스케쥴러에 전달됩니다. 스케줄러의 역할은 지정한 단위만큼 인덱서에 전달하는 쓰로틀(throttle) 기능을 가지고 있습니다. 큐 인덱서에서는 전체색인과 마찬가지로 ES에 색인 내용을 매핑합니다.
마무리
OJT를 진행하면서 있었던 내용들을 정리했습니다. 1~12주차 동안 다양한 내용을 접할 수 있었습니다. 처음에는 새로운 환경에서 새로운 기술들을 다뤄 보면서 낯설기도 했지만, 많은 분들의 도움으로 OJT 과정을 무사히 마칠수 있었습니다. 다음 OJT를 진행할 분에게도 작성한 내용이 많은 도움이 되었으면 좋겠습니다.
참고 자료 & 이미지 출처
- https://media.vlpt.us/images/nari120/post/b14b4105-a561-4cc3-bc9f-87a5ee4eb1b6/aws.png
- https://soobinnn.github.io/assets//img/logo/react-logo.png
- https://img1.gratispng.com/20180802/rxf/kisspng-kibana-elasticsearch-scalable-vector-graphics-logo-elastic-kibana-logo-svg-vector-amp-png-transpare-5b62e40d548557.8161086615332075653462.jpg
- https://upload.wikimedia.org/wikipedia/commons/thumb/c/c6/Influxdb_logo.svg/1200px-Influxdb_logo.svg.png
- https://fenixara.com/content/images/2020/04/prometheusPostImage-830x370.png
- https://ncube.net/wp-content/uploads/2020/11/vertical-logo-monochromatic.png