DACON을 통한 코드 실습 - FIFA 선수 이적료 예측
이현우
2022.12.05.
DACON의 분류와 회귀 문제를 실제로 다뤄보며 머신러닝에 대한 코드 실습을 진행해 보겠습니다.
FIFA 선수 이적료 예측
선수 이적료 예측은 주어진 특성으로 부터 선수의 이적 시장 가격을 예측하는 회귀 문제입니다.
1. 데이터 Set
- id : 선수 고유의 아이디
- name : 이름
- age : 나이
- continent : 선수들의 국적이 포함되어 있는 대륙입니다
- contract_until : 선수의 계약기간이 언제까지인지 나타내어 줍니다
- position : 선수가 선호하는 포지션입니다. ex) 공격수, 수비수 등
- prefer_foot : 선수가 선호하는 발입니다. ex) 오른발
- reputation : 선수가 유명한 정도입니다. ex) 높은 수치일 수록 유명한 선수
- stat_overall : 선수의 현재 능력치 입니다.
- stat_potential : 선수가 경험 및 노력을 통해 발전할 수 있는 정도입니다.
- stat_skill_moves : 선수의 개인기 능력치 입니다.
- value : FIFA가 선정한 선수의 이적 시장 가격 (단위 : 유로) 입니다
2 데이터 분석
2.1 데이터 구조 및 내용 파악
기본적인 데이터프레임 메서드를 통해 주어진 데이터의 형태와 구조 내용을 파악해보겠습니다.
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
pd.set_option('display.max_columns', None) # 열 출력할 때 생략 없이 전체 출력 옵션 설정
data = pd.read_csv('FIFA_train.csv') # csv 파일 데이터프레임으로 읽기
# 데이터 구조 확인 - 8932개의 행과 12개의 열
print(data.shape) # (8932, 12)
데이터 확인
print(data.head)

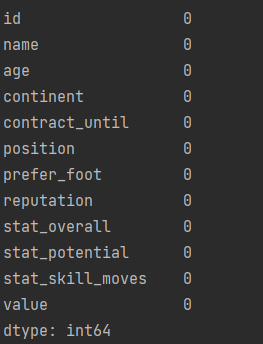
결측치 확인
print(data.isnull().sum())
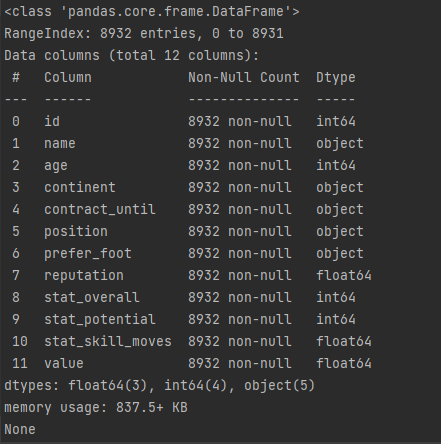
컬럼들의 자료형 확인
print(data.info())
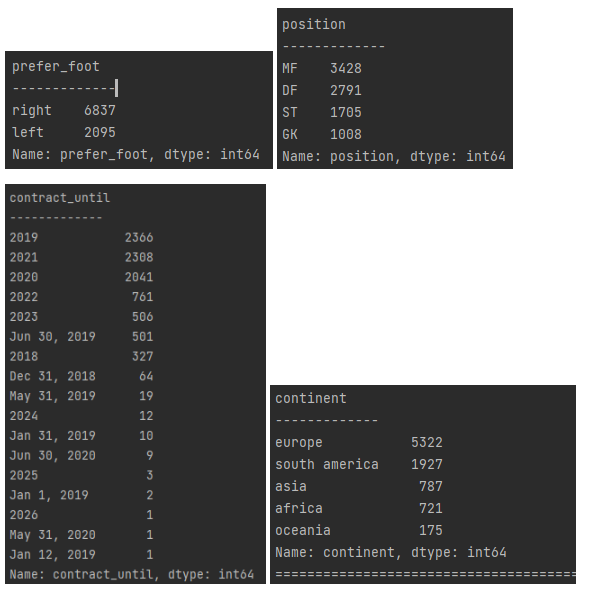
숫자 이외의 자료형의 value 종류 및 value 카운트 확인
for col in ["continent", "position", "prefer_foot", "contract_until"]:
print(col)
print('-------------')
print(data[col].value_counts())
정리
데이터 : FIFA에서 제공하는 데이터들을 통해, 선수들의 시장 가격과 능력치 사이의 상관 정도를 확인합니다.
자료형 소개
- 숫자 / 연속 자료형
- id: 선수의 ID (삭제 예정)
- age : 연령
- stat_overall : 선수의 현재 능력치
- stat_potential : 선수의 잠재력
- 범주 자료형
- name: 이름 (삭제 예정)
- continent : 국적
- contract_until : 계약 기간
- position : 포지션
- prefer_foot : 주로사용하는 발
- reputation : 선수의 유명한 정도
- stat_skill_moves : 선수의 개인기 능력치
- 삭제 예정인 데이터는 상관 관계에 도움이 되지 않는 데이터를 미리 선정하였습니다.
1.2 데이터 분포 확인
Python의 matplotlib의 pyplot을 통해 각 컬럼별 분포도를 작성해보겠습니다.
from matplotlib import pyplot as plt
class DataAnalyzer:
def __init__(self, data):
self.data = data
self.continous_col = ['age', 'stat_overall', 'stat_potential']
self.nomial_col = ['continent', 'contract_until', 'position', 'prefer_foot', 'reputation', 'stat_skill_moves']
# 연속 자료형 분포도
def continous_data_distribution(self):
# self.data.hist(bins=100)
# plt.show()
f, axes = plt.subplots(1, len(self.continous_col), figsize=(15, 5))
axes = axes.flatten()
for col, ax in zip(self.continous_col, axes):
sns.histplot(data=self.data, x=col, ax=ax)
plt.show()
# 명목형(범주형) 자료형 분포도
def nomial_data_distribution(self):
f, axes = plt.subplots(1, len(self.nomial_col), figsize=(20, 5))
axes = axes.flatten()
for col, ax in zip(self.nomial_col, axes):
print(ax)
sns.countplot(data=self.data, x=col, ax=ax)
plt.show()
if __name__ == '__main__':
# id와 name은 삭제 - 상관 관계를 살펴볼 때 불필요한 데이터
data.drop(['id', 'name'], axis=1, inplace=True)
analyzer = DataAnalyzer(data=data)
analyzer.continous_data_distribution() # 연속적 데이터 분포도
analyzer.nomial_data_distribution() # 범주형 데이터 분포도
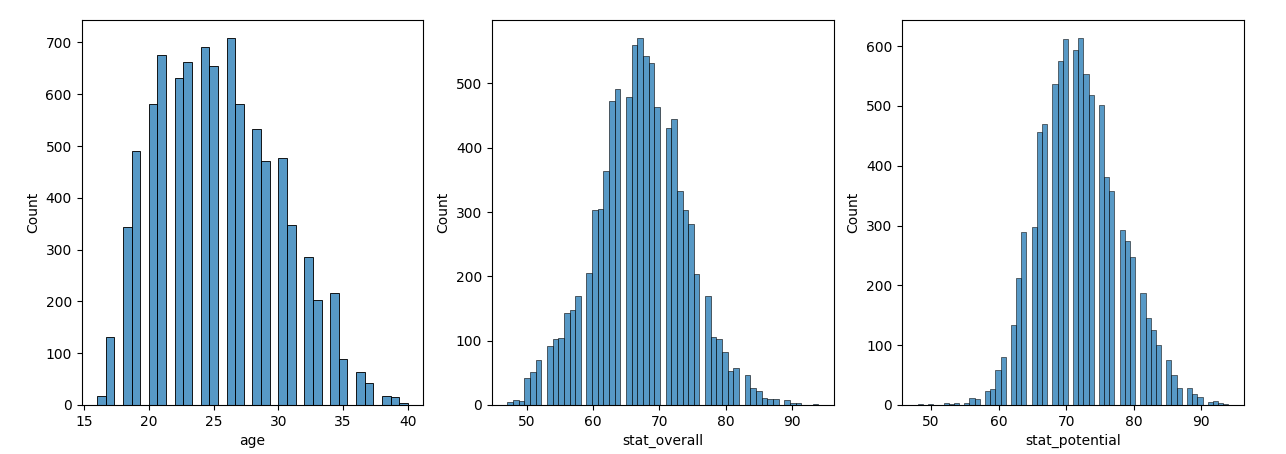
연속 자료형 분포도
명목형(범주형) 자료 분포도
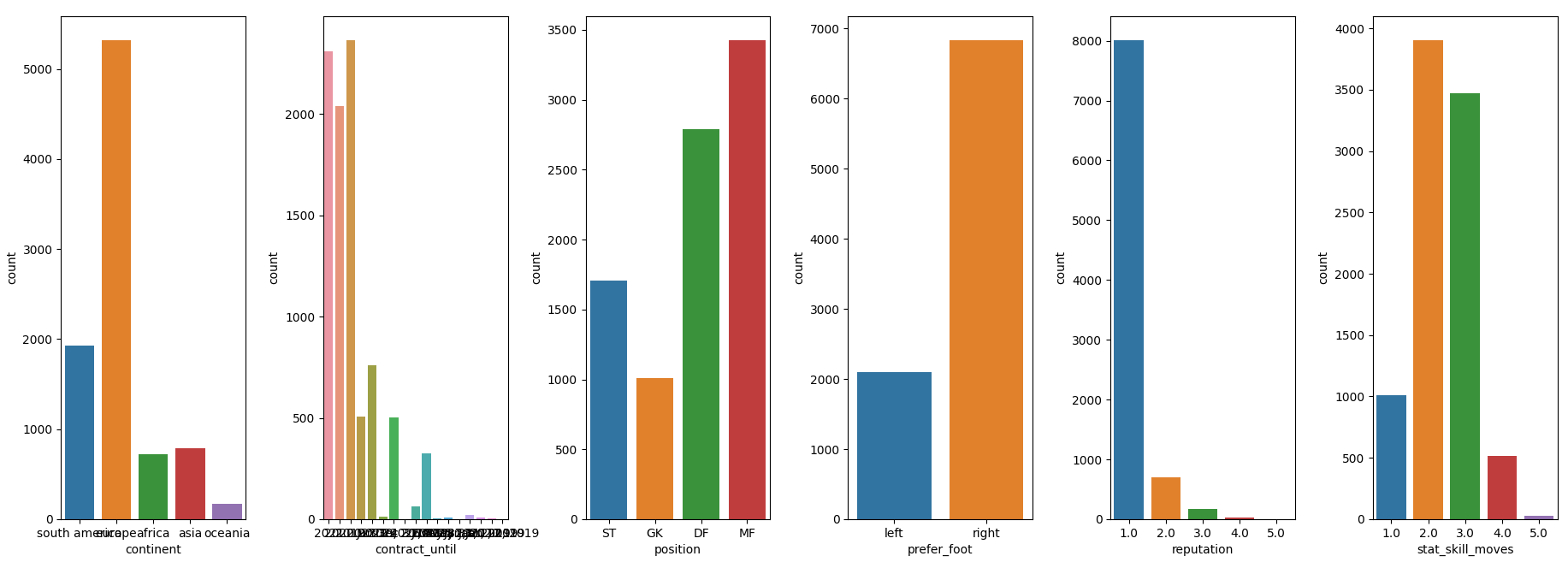
1.3 기술 통계량 확인
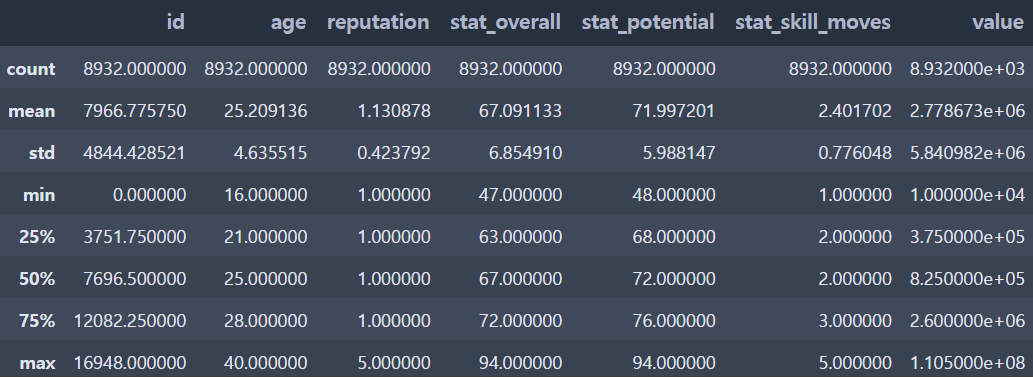
숫자 자료형 확인
print(data.describe())
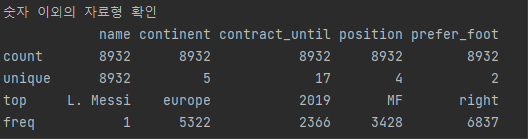
숫자 이외의 자료형 확인
print(data.describe(include="object"))
1.4 속성간 상관 관계 분석
각 속성간 상관관계에 대한 내용을 seaborn 라이브러리를 통해 시각화 해보겠습니다.
import seaborn as sns
sns.heatmap(data=self.data.corr(), annot=True, vmax=1, vmin=-1)
plt.show()
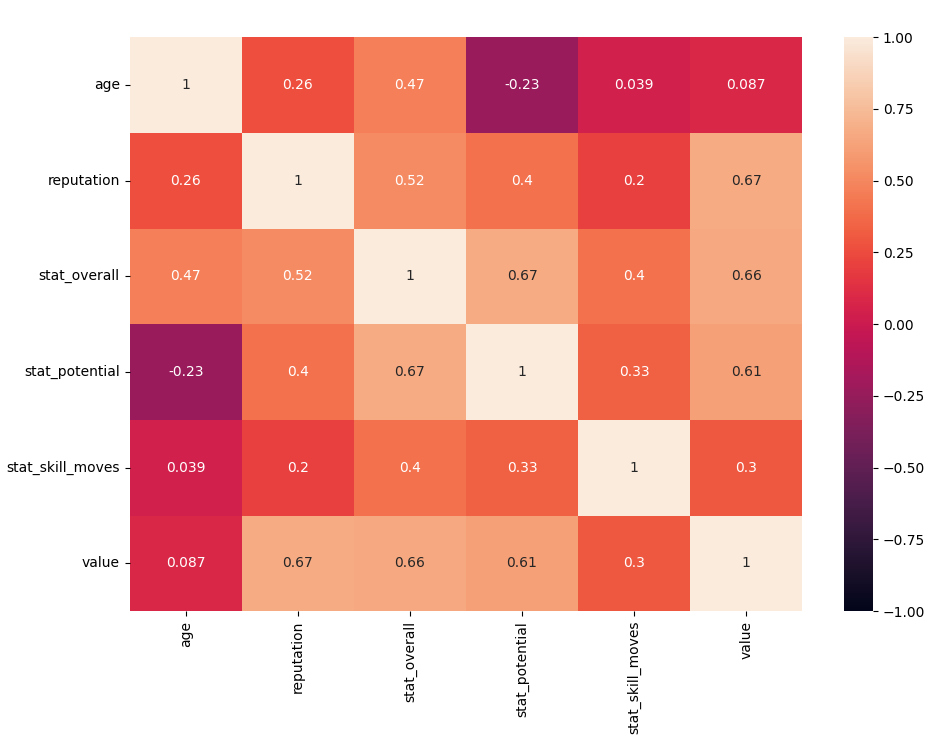
Value와 reputation, stat_overall, stat_potential은 높은 양의 관계이며, stat_skill_moves와는 낮은 양의 관계, age와는 매우 낮은 양의 관계로 보입니다.
2. 전처리
이적 시기의 형태는 년도만 남기도록 하였습니다.
- 대부분 년도 형식이지만 Jun 30, 2019와 같이 월 일, 년도의 형식이 존재하기에 형식을 통일하였습니다.
continent, position, prefer_foot에 대해선 라벨 인코딩을 진행하였습니다.
age, stat_potential, value는 log 함수를 적용하였습니다.
- value의 값이 크기 때문에 차이를 줄여주기 위해서 log를 적용하였습니다.
class PreProcessor:
def __init__(self, train, test):
self.train = train
self.test = test
def convert_contract_until(self):
# contract_until : 이적 시기
def dis(x):
splited= x.split()
return int(splited[-1])
self.train['contract_until'] = self.train.contract_until.apply(dis)
self.test['contract_until'] = self.test.contract_until.apply(dis)
def label_encoding(self, column):
encoder = LabelEncoder()
self.train[column] = encoder.fit_transform(self.train[column].values)
self.test[column] = encoder.transform(self.test[column].values)
def set_log(self):
self.train[['age', 'stat_potential', 'value']] = np.log1p(self.train[['age', 'stat_potential', 'value']])
self.test[['age', 'stat_potential']] = np.log1p(self.test[['age', 'stat_potential']])
def make_data(self, feature_list):
# train_input, train_target, test_input 데이터 만들기
train_target = self.train['value']
train_input = self.train[feature_list]
test_input = self.test[feature_list]
return train_input, train_target, test_input
3. 모델
모델은 RMSE 평가 산식에서 XGBoost나 LightBoost보다 성능이 조금 더 좋은 NGBoost를 사용했습니다.
또한 교차 검증을 사용하기 위해 scikit-learn의 KFold 모듈을 사용하였습니다.
- 교차검증 → 검증 세트를 떼어 내어 평가하는 과정을 여러(k) 번 반복합니다.
- 그 다음 이 점수를 평균하여 최종 검증 점수를 얻습니다.
- 몇(k) 번 반복하는지에 따라 K-겹 교차 검증이라고도 부릅니다.
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from ngboost import NGBRegressor
class ModelFactory:
def __init__(self, train_input, train_target, test_input):
self.train_input = train_input
self.train_target = train_target
self.test_input = test_input
def ngboost(self):
kf = KFold(n_splits=10, random_state=521, shuffle=True)
ngb = NGBRegressor(random_state=521, verbose=500, n_estimators=500)
ngb_pred = np.zeros((self.test_input.shape[0]))
rmse_list = []
for tr_idx, val_idx in kf.split(self.train_input, self.train_target):
tr_x, tr_y = self.train_input.iloc[tr_idx], self.train_target.iloc[tr_idx]
val_x, val_y = self.train_input.iloc[val_idx], self.train_target.iloc[val_idx]
ngb.fit(tr_x, tr_y)
pred = np.expm1([0 if x < 0 else x for x in ngb.predict(val_x)])
rmse = np.sqrt(mean_squared_error(np.expm1(val_y), pred))
rmse_list.append(rmse)
sub_pred = np.expm1([0 if x < 0 else x for x in ngb.predict(self.test_input)]) / 10
ngb_pred += sub_pred
print(f'{ngb.__class__.__name__}의 10fold 평균 RMSE는 {np.mean(rmse_list)}')
return ngb_pred, rmse_list, ngb
4. 기록
모델링 개선을 통해 점수를 더 높일 수 있을거라 생각합니다.
5. 참고 자료
- DACON - https://dacon.io/
- FIFA 선수 이적료 예측 - https://dacon.io/competitions/open/235538/overview/description