다나와 검색의 색인 최적화 사례
다나와 검색의 동적 색인 최적화 사례
안녕하세요, 커넥트웨이브 다나와 검색Backend팀 곽명환입니다.
다나와 검색은 각 상품 쇼핑몰 협력사로부터 제공받은 상품 데이터를 다나와의 기준 상품과 매칭하여 최저가를 비교하는 서비스를 제공합니다.
협력사가 많은 만큼 데이터의 양도 방대하며, 현재 약 10억 개이상의 상품 데이터를 운영 중입니다.
이러한 상품들의 재고 및 상태는 매 분, 매 초 단위로 변화하기 때문에 실시간 데이터 최신화가 필수적입니다.
이를 위해 다나와에서는 동적 색인이라는 과정을 수행하고 있습니다.
문제 상황
검색엔진으로 Elasticsearch(이하 ES)를 사용 중이며, 협력사로부터 매 1분 단위로 대량의 데이터(수 GB, 일일 수억 개)가 유입됩니다.
최근 까지는 큰 문제 없이 운영 되었으나, 에누리와의 통합 이후 상품의 유입이 급증하며 다음과 같은 문제들이 발생했습니다.
1. CPU 부하 급증 및 힙 메모리 사용량 증가
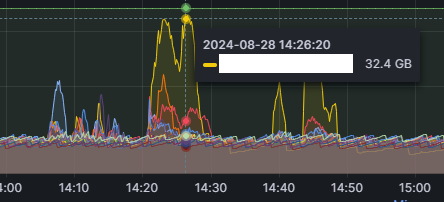
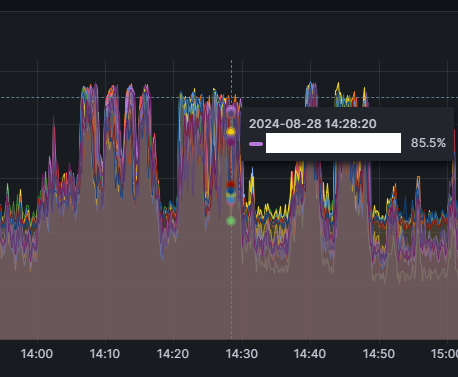
좌우 각각 ES 클러스터 내 노드들의 힙 메모리, CPU 사용량 입니다.
특정 데이터 노드의 힙 메모리가 설정된 최대 크기에 근접하는 경우가 간혹 발생하며, 협력사의 이벤트 등으로 인해 업데이트가 급증하면 ES의 CPU 사용률이 100%에 가깝게 도달하는 문제가 빈번히 발생했습니다.
2. 잦은 샤드 이동 및 미할당 문제
CPU와 메모리 부하로 인해 노드가 다운되거나 샤드가 재분배되는 상황이 발생하기도 했습니다.
3. 색인 요청 거절로 인한 데이터 불일치
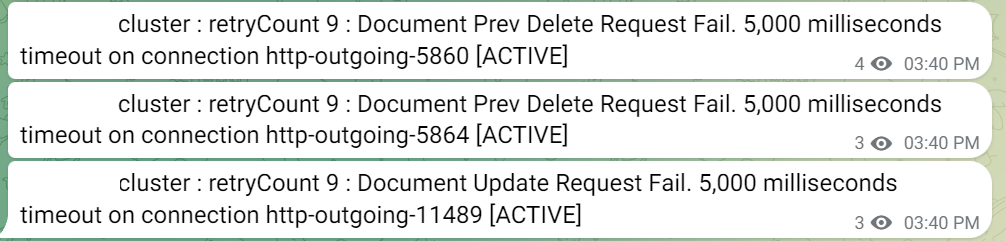
ES의 Writer Thread Pool이 가득 차거나 타임아웃 등의 문제로 색인 요청이 거절되었고, 그로 인해 원본 DB와 ES 간 데이터 정합성 문제가 발생했습니다.
4. 검색 API 응답 속도 지연
CPU, 메모리 부하로 인해 발생한 ES 응답 지연으로 검색 서비스의 성능이 저하되어 사용자 경험에 악영향을 미쳤습니다.
원인 분석
1. 과도한 세그먼트 생성 및 Disk I/O 증가
동적 색인으로 인해 ES에서 세그먼트 생성 작업이 빈번히 발생하면서 Disk I/O와 CPU 사용량이 급증했습니다.
2. 색인 서버의 비효율적 버퍼 사용
현재 색인 서버는 MQ에서 메시지를 소비한 후 해당 데이터를 Bulk API를 통해 즉시 ES로 색인 요청을 보내는 구조입니다.
이는 Bulk API의 장점을 제대로 활용하지 못하며, 단건 Request 방식과 크게 다르지 않습니다.
단건 Request VS Bulk Request
`To optimize insert speed, combine many small operations into a single large operation. Ideally, you make a single connection, send the data for many new rows at once, and delay all index updates and consistency checking until the very end.` - insert 성능을 높이기 위해서는 작은 여러 연산을 큰 하나의 연산으로 만들어라. 라는 말을 위의 mysql doc에서 볼 수 있듯이 그렇게 배웠고 그렇게 개발을 진행했었습니다. 출처 : https://techblog.woowahan.com/2718/3. 백프레셔 로직 부재
ES의 CPU 상태를 고려하지 않고 색인 요청을 보내는 방식으로 인해 색인 집중 시간대에 CPU 사용률 100% 상황이 빈번히 발생했습니다.
이로 인해 검색 API 응답 지연 및 색인 요청 실패가 발생했습니다.
4. 코디네이터 노드의 부재
기존 다나와 검색팀에서는 엘라스틱 서치 클러스터를 코디네이터 노드 없이 마스터, 데이터 노드로만 운영중이었습니다. 색인 서버의 ES 엔드포인트로 데이터 노드 몇 개가 대표로 지정되어있는데, 이 노드들이 색인 + 타 노드로 요청을 라우팅을 동시에 수행하다 보니 해당 노드들의 부하가 가중되고 힙 메모리가 집중적으로 상승하는 현상이 발생했습니다.
이 문제는 추가적인 서버를 확보 후 코디네이터 노드를 띄워 해결했습니다.
해결 방안
1. BulkProcessor API 활용
BulkProcessor API는 내부적으로 데이터를 모아 효율적으로 색인 요청을 처리하는 기능을 제공합니다.
이 API를 사용하여 기존의 비효율적인 건 바이 건 색인 방식을 개선했습니다.
RestHighLevelClient에서 지원해주는 BulkProcessor API는 색인 전, 후에 대한 동작을 콜백 방식으로 정의합니다.
@Bean
public BulkProcessor bulkProcessor(@Qualifier("elasticsearchClient") RestHighLevelClient client) {
return BulkProcessor.builder(
(request, bulkListener) -> client.bulkAsync(request, RequestOptions.DEFAULT, bulkListener),
new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId, BulkRequest request) {
// 색인 전 동작을 정의
}
@Override
public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
// 색인(성공) 후 동작을 정의
}
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
// 색인(실패) 후 동작을 정의
}
}
)
.setBulkActions(bulkActionsSize)
.setBulkSize(new ByteSizeValue(10, ByteSizeUnit.MB))
.setFlushInterval(TimeValue.timeValueSeconds(bulkBackOffFlushInterval))
.setConcurrentRequests(bulkConcurrentSize)
.setBackoffPolicy(
BackoffPolicy.exponentialBackoff(TimeValue.timeValueMillis(100), bulkBackOffPolicySize)
)
.build();
}
BulkProcessor를 빈으로 등록하는데, bulkListener 인터페이스의 콜백 메서드 구현에 들어오는 BulkRequest의 경우 튜닝하기가 조금 까다로운 면이 있었습니다.
BulkRequest는 DocWriteRequest를 담는 List인데, 서비스의 특성상 각 요청의 호출처(host)와 타겟 인덱스를 추적 할 수 있어야 해 다음과 같이 커스텀하게 구현해 사용했습니다.
public interface CustomRequest<T> {
T hostName(String hostName);
String getHostName();
String getOperationType();
}
public class CustomUpdateRequest extends UpdateRequest implements CustomRequest<CustomUpdateRequest> {
private String hostName;
private static final String OPERATION_TYPE = "UPDATE";
@Override
public String getOperationType() {
return OPERATION_TYPE;
}
public CustomUpdateRequest() {
super();
}
@Override
public CustomUpdateRequest hostName(String hostName) {
this.hostName = hostName;
return this;
}
@Override
public String getHostName() {
return hostName;
}
@Override
public CustomUpdateRequest retryOnConflict(int retryOnConflict) {
super.retryOnConflict(retryOnConflict);
return this;
}
@Override
public CustomUpdateRequest doc(Map<String, Object> source) {
super.doc(source);
return this;
}
public CustomUpdateRequest setIndex(String index) {
super.index = index;
return this;
}
}
bulk 색인 이후에 실행 될 afterBulk 메서드는 다음과 같이 구현되어 호출처를 추적할 수 있었습니다.
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
String hostName = getHostName(request);
Map<String, Long> operationCounts = request.requests().stream()
.filter(r -> r instanceof CustomRequest)
.map(r -> ((CustomRequest<?>) r).getOperationType())
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
StringBuilder operationsInfo = new StringBuilder();
operationCounts.forEach((key, value) ->
operationsInfo.append(key).append(": ").append(value).append(", ")
);
if (operationsInfo.length() > 0) {
operationsInfo.setLength(operationsInfo.length() - 2);
}
logger.error("[executionId:{}][max retry count:{}][Host:{}][Info:{}][Reason:Document Request Fail:{}][operationsInfo:{}]",
executionId, bulkBackOffPolicySize, hostName, request.getDescription(), failure.getMessage(), operationsInfo);
NoticeHandler.send(
String.format("%s : retryCount %d : Document Request Fail. %s OperationsInfo: %s",
clusterName, bulkBackOffPolicySize, failure.getMessage(), operationsInfo)
);
}
private String getHostName(BulkRequest request) {
return request.requests().stream()
.findAny()
.map(r -> ((CustomRequest<?>) r).getHostName())
.orElse("");
}
위 코드는 색인 요청 실패에 대한 afterBulk 메서드이고, 아래 쪽 로그는 요청 성공 이후 실행되는 afterBulk 메서드입니다.
다음과 같이 로그를 통해 호출처와 타겟 인덱스를 추적할 수 있고, Total Size, 실제 색인 된 사이즈 또한 추적 할 수 있게 구현했습니다.

2. 백프레셔 로직 도입
ES의 CPU 상태에 따라 색인 속도를 동적으로 조절하는 로직을 추가했습니다.
구현 방식
- CPU 상태 모니터링
- 스케줄러를 통해 0.2초 간격으로 ES 노드의 CPU 상태를 조회.
- 모니터링 결과에 따라 색인 요청을 조절(배포 프로세스 없이 동적으로 조절 가능).
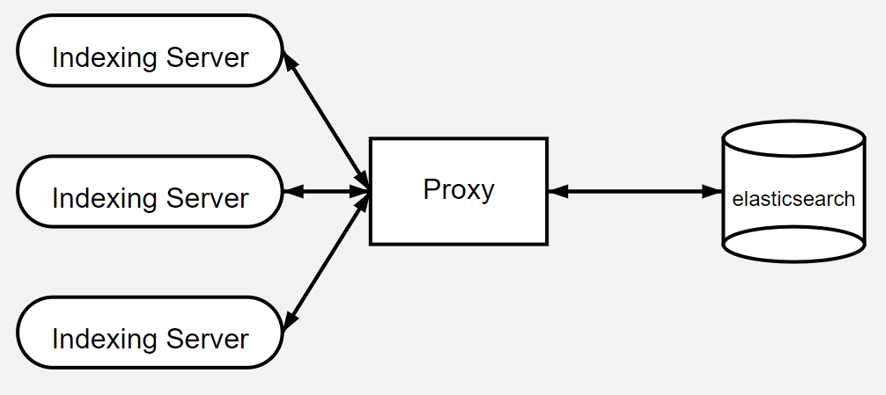
- 프록시 서버 추가
- 각 색인 서버(12개)가 개별적으로 ES 상태를 조회하는 비효율을 줄이기 위해 Express 프록시 서버를 도입.
- 색인 서버는 프록시 서버로 REST API 요청을 보내고, 프록시 서버는 스케쥴링으로 주기적으로 ES의 CPU 상태를 확인 후 상태 값을 반환.
- 구조는 다음과 같습니다.
- busy-waiting 기반의 색인 속도 조절 로직 구현
@Override public Boolean call() throws Exception { while(true) { try { // CPU Overload 상태일 경우 색인을 하지 않는다. if (searchEngineCpuStatusHolder.isCpuOverload()) { continue; } // BlockingQueue에서 데이터를 폴링 List<Delivery<?>> deliveries = getDeliveries(); if (deliveries.size() > 0) { indexing(deliveries); } } catch (Throwable t) { ... } finally { ... } } return true; }- CPU 코어 수 만큼 병렬로 기용 가능한 스레드를 busy-waiting 기반의 로직으로 구현
- 서버의 자원 상태에 여유가 있는 것을 확인 후, 컨텍스트 스위칭 비용 절약으로 색인 속도 증가, 상품 데이터의 실시간성 ↑
기대 효과
- CPU 사용률 80%에 도달하기 전 색인 속도를 제어하여 시스템 안정성 확보.
- 검색 API의 응답 속도와 데이터 정합성 문제 개선.
테스트
1. 개발 서버
- 테스트는 개발 서버 환경에서 진행
2. Elasticsearch 클러스터 구성
- 노드 수: 12개
- 물리적 서버: 3대
- 각 노드의 메모리 할당: 4GB
3. Consumer 서버 설정
- RabbitMQ prefetchCount: 250
- 힙 메모리: 8GB
- 싱글 프로세스
테스트 조건은 실제 운영 환경의 극단적 상황을 시뮬레이션하여, 시스템의 성능과 안정성을 평가하기 위함입니다.
기존 방식
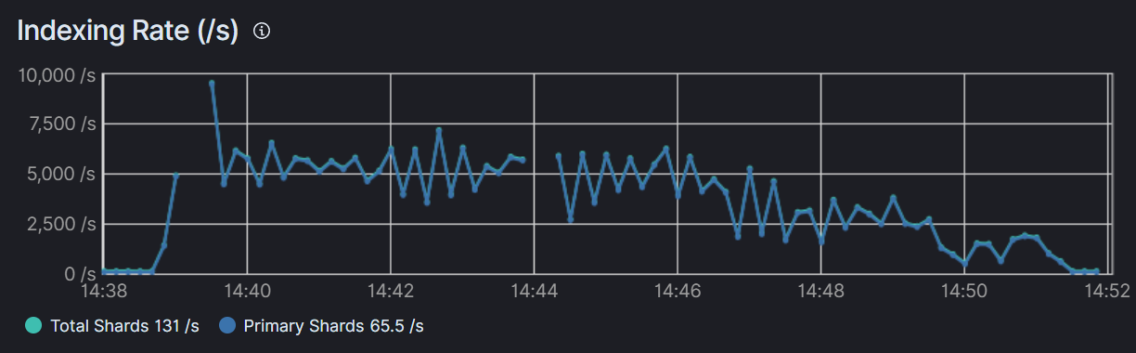
- Indexing Rate의 불안정성:
- 색인 속도가 일정하지 않고 변동이 큼
- 중간중간 연결 끊김 현상 발생(노드가 다운 된 적도 있음)
- 색인 성능 저하:
- 시간이 지남에 따라 색인 속도가 점진적으로 감소하는 추세를 보임
- 총 소요 시간:
- 1,000만 건의 데이터 처리에 약 14분 소요
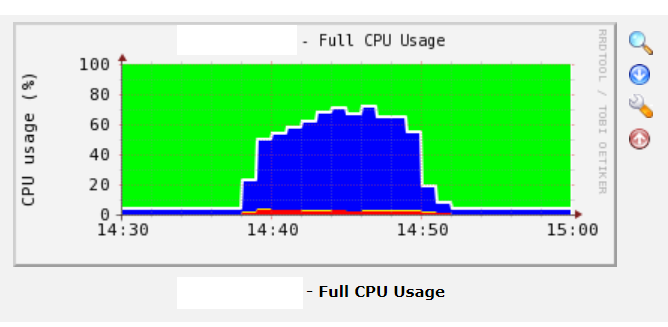
해당 시간대에 서버 CPU의 사용량(피크일 때 약 70%)
변경된 방식
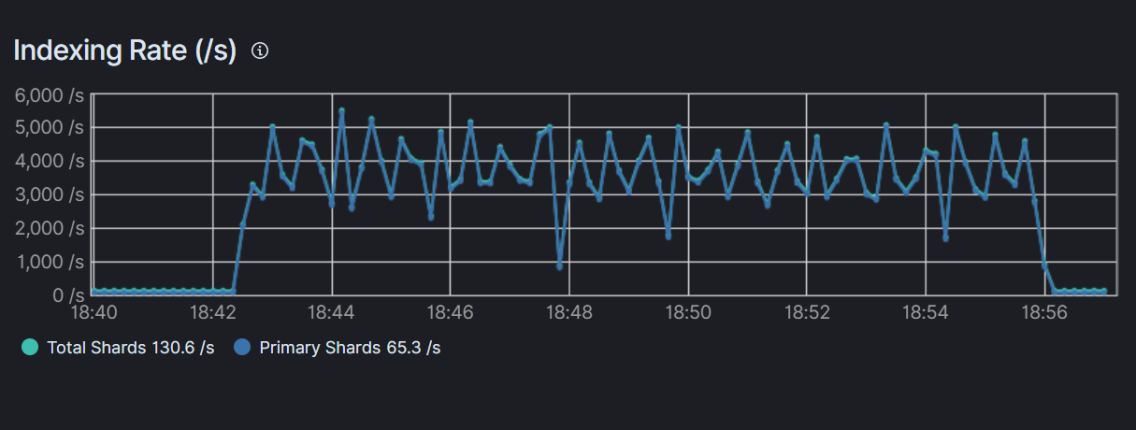
- Indexing Rate의 안정성:
- 기존 방식에 비해 색인 속도가 상대적으로 일정함
- 연결 끊김 현상이 관찰되지 않음
- 색인 성능 저하:
- 색인 과정 전반에 걸쳐 안정적인 처리 속도 유지
- 총 소요 시간:
- 1,000만 건의 데이터 처리에 약 14분 소요
- 기존 방식과 유사한 총 처리 시간
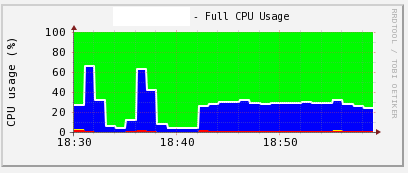
해당 시간대에 서버 CPU 사용량(30%대 유지)
테스트 결과
- 개선된 방식이 데이터 처리의 안정성과 일관성 측면에서 상당한 향상을 보였음을 확인할 수 있었습니다.
- 특히, 연결 끊김 현상의 해소는 시스템의 신뢰성 증가를 의미합니다.
- 또한, 총 처리 시간이 유사하다는 점은 성능 저하 없이 안정성이 개선되었음을 시사합니다.
성과

운영 서버에서 일주일 분의 모니터링 로그를 확인한 결과, 동적 색인이 많이 몰리는 시간에도 전체 노드의 CPU 사용량이 80%를 넘지않는 것을 확인할 수 있었습니다.
결론
개선 전/후 CPU 사용량과 색인 성능을 비교한 결과, CPU 부하와 응답 지연이 현저히 감소했습니다.
BulkProcessor와 백프레셔 로직 도입으로 시스템의 전반적인 안정성과 성능을 확보할 수 있었습니다.
다나와 검색은 앞으로도 협력사와 사용자 모두에게 더 나은 서비스를 제공하기 위해 최선을 다하겠습니다.
감사합니다.