다나와의 상품 색인 파이프라인
상품 색인 파이프라인 소개
안녕하세요. 다나와에서 검색 서비스를 개발하고 있는 곽명환 입니다.
오늘은 검색 개발팀에서 사용하고 있는 동적 색인 서비스의 흐름과 해당 서비스의 문제점, 해결 방안을 소개해 보도록 하겠습니다.
다나와에서는 약 11억건의 상품 데이터를 보유하고 있습니다.
대용량 데이터를 실시간에 가까운 속도로 처리하고, 전문 검색 등이 가능할 수 있도록 RDBMS 대신 엘라스틱 서치를 채택해 검색 엔진으로 사용하고 있습니다.
상품 데이터의 동적인 추가 및 업데이트에 대응하기 위한 파이프라인이 사진과 같이 구성되어 있습니다.
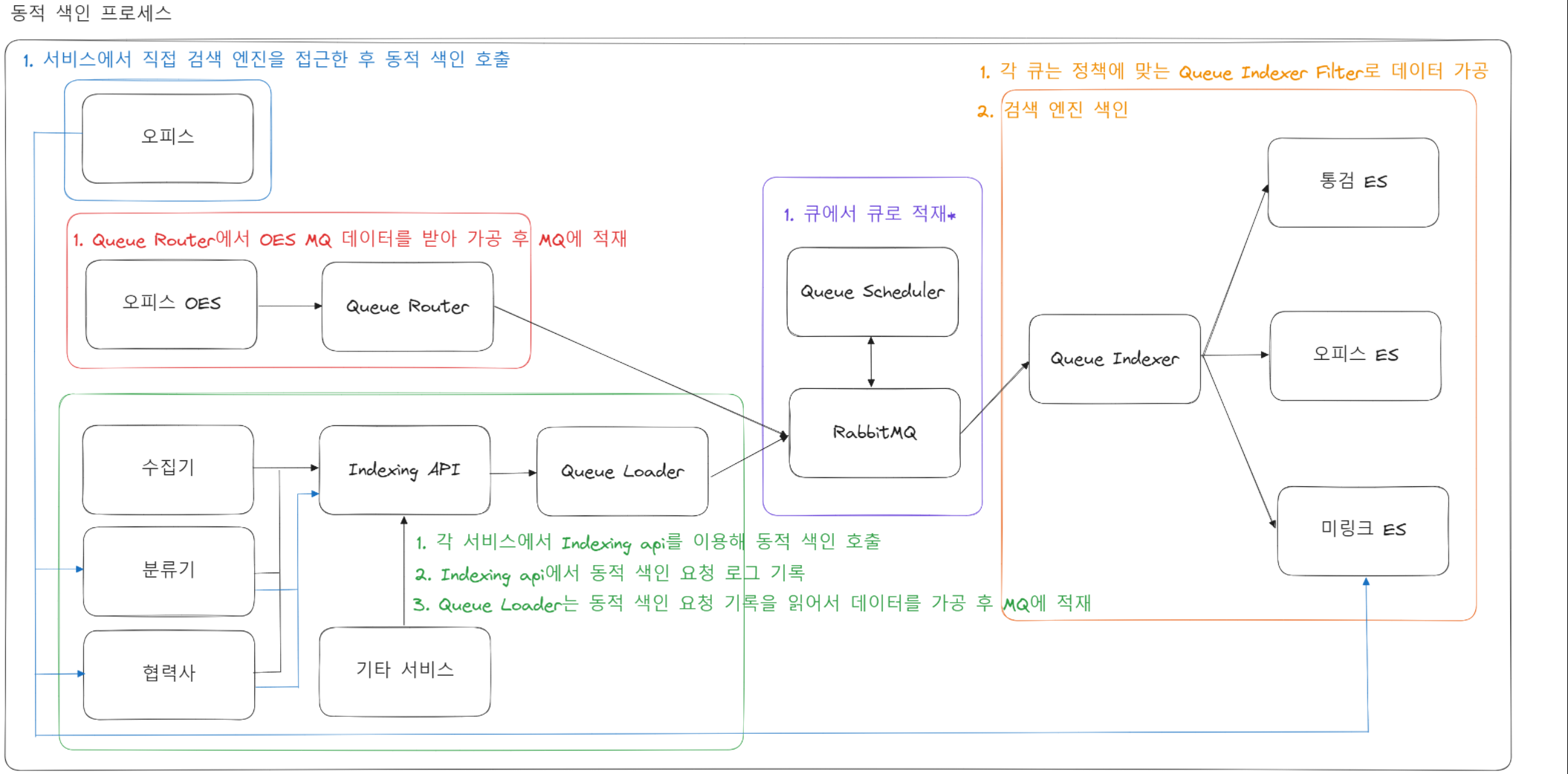
데이터 파이프라인으로 운용 중인 서비스들이 특정 외부 서비스(RabbitMQ)에 지나치게 의존적이고 내구성과 안정성이 떨어진다고 판단되어 제 주도하에 구조 개선을 진행하고 있습니다.
기능 요약
- Indexing API에서는 유입되는 데이터를 1분 간격으로 로그파일로 저장합니다.
- Queue Loader에서는 로그파일을 실시간으로 읽어 전처리 후 MQ로 보내줍니다.
- 컨슈머 서비스인 Queue Indexer에서 데이터를 처리한 후 ES로 색인합니다.
문제점
현 파이프라인의 문제점은 다음과 같습니다.
서비스 마이그레이션의 어려움
Queue Loader는 자바로 생성된 프로젝트라서 보일러 플레이트 코드가 많습니다. 또한, SOLID 원칙이 지켜지지 않아 유지보수가 어렵습니다.
위의 이유로 Message Queue에 매우 의존적인 형태로 기능을 수행 중입니다. 만약 다른 서비스로 마이그레이션 하게 된다면 Message Queue와 관련된 모든 코드를 수정해야 할 뿐만 아니라, 사이드 이팩트가 커질 확률이 매우 높습니다.
끊임없는 유지보수
정책이 바뀐다면 코드를 수정해야 합니다. 복잡하게 짜여져 있는 코드를 유지보수하기 위한 비용 소모가 큽니다.
성능과 안정성의 부재
데이터 유실에 대한 방어책이 미비합니다.
요지는 서비스의 이관으로 발생하는 소모 비용을 최소화하고, 성능과 안정성을 최대한 끌어올려 문제를 해결하는 것입니다.
개선 방안에 대해 곰곰이 생각해 본 결과, logstash를 사용하자는 결론에 도달하게 되었습니다.
logstash란?
- Logstash는 형식이나 복잡성과 관계없이 데이터를 동적으로 수집, 전환, 전송합니다.
- grok을 이용해 비구조적 데이터에서 구조를 도출하여 IP 주소에서 위치 정보 좌표를 해독하고, 민감한 필드를 익명화하거나 제외시키며, 전반적인 처리를 손쉽게 해줍니다.
logstash를 선택한 이유
기존 서비스를 logstash로 대체했을 때의 장점은 다음과 같습니다.
logstash의 output 파라미터만 변경해 주면 MQ 서비스를 손쉽게 이관할 수 있습니다.
- 기존 서비스를 그대로 사용한다면 수백, 수천줄의 코드를 바꿔야 할 것이 단 몇줄의 설정을 바꾸는 것으로 해결됩니다.
기존 서비스에서 해주는 역할을 logstash에서 대체할 수 있습니다.
- 로그 파일을 마지막으로 읽은 시점을 기록하는 sincedb
- 데이터 파이프라인을 구축할 수 있는 filter 기능
- MQ로 데이터를 send 해주는 output 기능
- 서버에 장애 발생 시, dead letter queue를 사용해 대응 가능
자체적으로 관리해야 할 서비스의 수가 줄어들기 때문에, 핵심 비즈니스 로직에 집중할 수 있습니다.
- 정책 하나를 수정하기 위해서는 기존 서비스의 흐름을 항시 파악하고 있어야 합니다. 관리하는 서비스가 한두 개가 아닌 이상 힘든 일입니다.
Queue loader 뿐만 아니라, 다른 MQ에 의존적인 서비스들 또한 점진적으로 개선해 나갈 수 있습니다.
- 예를 들어서, Queue Router 서비스의 경우에도 멀티 파이프라인을 구성한다면 쉽게 마이그레이션 할 수 있습니다.
현실적으로 RabbitMQ에 존재하는 모든 queue들을 한 번에 교체할 수는 없고, 전처리 과정을 순차적으로 마이그레이션 해 완전히 대체하는 것을 목표로 하고 있습니다.
logstash 모듈형 파이프라인
MQ에서 관리하는 queue가 수십 개가 되는데, 아무래도 하나의 파이프라인 파일을 사용해서 filter에서 분기 처리를 하게 된다면 유지관리, 재사용이 굉장히 힘들 것입니다.
그래서 저는 모듈형 파이프라인을 구성해서 분기 처리를 해주었는데요, pipeline.yml 파일에서 수정할 수 있습니다.

위 사진과 같이 glob 표현식을 사용해 다음과 같이 원하는 구성 요소로 파이프라인을 정의할 수 있습니다.

이런 식으로 각 정책에 맞게끔 필터를 구성해 주면 유지보수가 굉장히 손쉬워지겠죠?
성능 테스트

테스트에 사용할 로그는 실제 사용처에서 1분간 다나와로 들어온 요청을 쌓아놓은 1G의 txt 파일입니다.
기존 서비스에서 처리하는 속도와, logstash에서 처리하는 속도를 비교해 보도록 하겠습니다.
메모리, CPU 사용량 같은 매트릭 데이터는 추후에 grafana 같은 모니터링 툴을 사용해서 비교해 보도록 하고, 이 글에서는 txt 파일을 처리하는 데 걸리는 시간을 비교하여 성능을 테스트해 보도록 하겠습니다.
logstash 같은 경우 로그 파일을 처리하는 데 걸리는 시간을 측정하는 게 용이하지 않기 때문에, 파일의 첫 라인(startTime)과 마지막 라인(endTime)을 처리하는 데 걸리는 시간의 차이를 계산해서 측정하겠습니다.
테스트 환경을 동일하게 맞추기 위해, wsl2 Ubuntu 환경에서 힙 메모리를 4G로 제한 후에 실행합니다.
java -Xmx4g -jar queue-loader.jar
기존 서비스를 사용한 테스트 결과는 다음과 같습니다.

기존 서비스는 약 25초 정도가 걸렸습니다.
# docker-compose.yml
version: '3'
services:
logstash:
container_name: logstash
hostname: logstash
image: docker.elastic.co/logstash/logstash:7.9.1
network_mode: "host"
volumes:
- ./config/logstash.yml:/usr/share/logstash/config/logstash.yml:ro,Z
- ./pipeline:/usr/share/logstash/pipeline:ro,Z
- ./input_data:/usr/share/logstash/input_data
- ./sincedb:/usr/share/logstash/sincedb
environment:
LS_JAVA_OPTS: "-Xms4g -Xmx4g"
~
logstash도 마찬가지로 힙 메모리를 4G로 제한하고 실행해보겠습니다.

첫 메세지, 마지막 메세지를 MQ에 보냈을 때의 @timestamp 로그입니다. timestamp의 차이를 계산해보면 약 5초 정도가 걸렸다는 것을 알 수 있는데요, 정확한 테스트는 아니지만 대략적으로 80% 이상의 성능이 개선된 것을 확인할 수 있습니다.
정확성 테스트
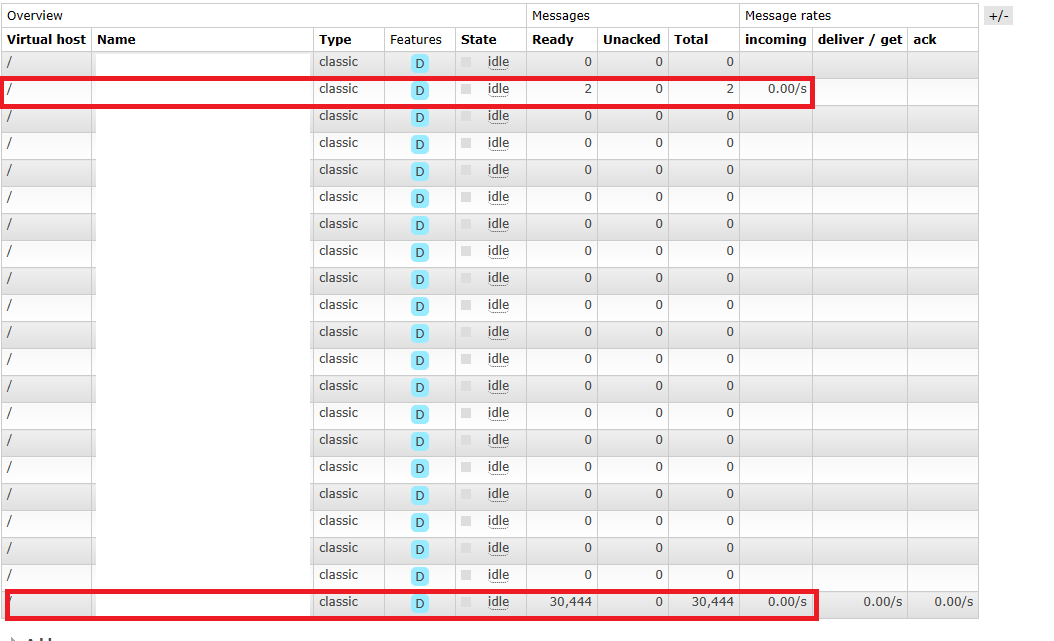
Message Queue에 데이터가 정확하게 전송되었는지 확인해보겠습니다.
logstash
Queue Loader
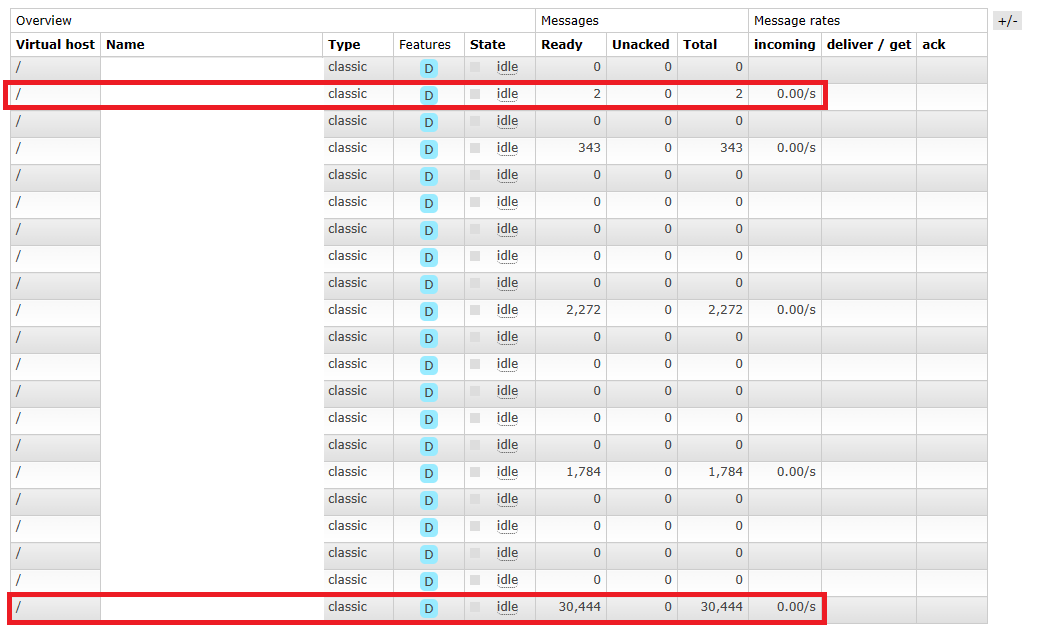
붉은 색 박스로 표시 된 부분을 보면 queue에 정확하게 데이터가 들어간 것을 확인할 수 있습니다.
요약
logstash로 서비스를 이관하면서 유지보수가 훨씬 쉬워졌고, 성능 또한 개선된 것을 확인할 수 있었습니다.
이상으로 기존 다나와의 데이터 파이프라인 서비스를 교체하기 위한 방안을 소개해보았습니다.
참고문서
https://www.elastic.co/kr/logstash
https://www.elastic.co/kr/blog/how-to-create-maintainable-and-reusable-logstash-pipelines