Elasticsearch 3TB의 인덱스를 reindex 하는 방법
10억 문서 색인의 필요성
현재 다나와에서 가지고 있는 상품수는 10억건 이상입니다. (점점 더 증가하는 추세) 그만큼 검색 품질을 높이기 위한 방안도 수립중인데요. 특히 사전 변경 대한 적용과 Mapping 변경 시 이를 위해 매주 reindex를 수행하고 있습니다.
이 문서에서는 대용량 인덱스에 대한 reindex를 도입하면서 겪었던 이슈와 해결 방안, 현재 결과에 대해 다루고 있습니다. 추가적으로, 속도와 안정성을 높이기 위해 어떤 조치를 취해야할지 약간의 Tip을 제시합니다.
참고로 다나와 검색 시스템은 현재 약 3.X TB의 데이터를 레플리카를 포함하여 10 ~ 11시간에 걸쳐 색인하고 있습니다.
노드는 총 18개로 구성되어 있으며, 2개의 마스터 노드와 16개의 데이터 노드로 구성되어 있습니다.
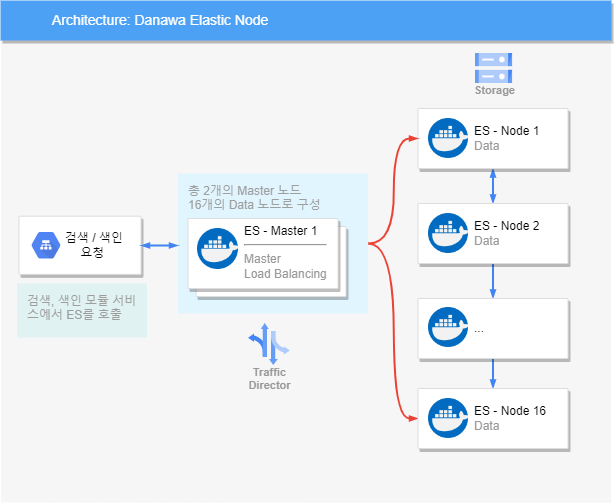
사용 버전은 7.8.1 기준으로 최신 버전과 결과가 약간 달라질 수 있습니다.
reindex 속도에 변화를 주는 요소들
1. replica는 reindex 완료 후에 생성하자
결과적으로 replica는 reindex시 포함하지 않는 것이 좋습니다. 만약 사본을 끼고 색인하게 되면 초기 IO가 높아져 굉장히 오랜 시간이 소요됩니다.
2. refresh_interval는 -1로 설정한다
인덱스의 refresh_interval은 인덱싱된 문서를 검색할 수 있는 시점에 대해 설정하는 옵션입니다.
reindex 중인 대상 인덱스에 대해 검색이 들어올 일이 없으므로 해당 옵션을 -1로 설정하여
새로 고침 프로세스를 OFF 합니다.
3. 배치 사이즈를 적절히 조정해본다
reindex는 기본적으로 search -> bulk 로 이뤄지는 구조입니다. reindex의 size 파라미터를 적절히 조절해서 색인 효율을 증가시킬 수 있습니다. 추천하는 방법은 색인 속도에 영향이 없을 때까지 수치를 증가시켜 최대 속도에 도달하는 지점을 찾아내는 방법입니다.
이 지점은 각 시스템의 환경에 따라 달라질 수 있는 부분이므로, 몇 번의 시도를 통해 알아내는 것을 추천드립니다.
POST _reindex
{
"source": {
"index": "source",
"size": 5000
},
"dest": {
"index": "dest"
}
}
설정하지 않았을때 기본값은 1,000 입니다.
4. 프라이머리 샤드 수에 변화를 준다
reindex 작업의 속도는 프라이머리 샤드 수에 비례합니다. 샤드 수가 올라가면 증가하고, 샤드 수가 낮으면 감소하는 식입니다. 색인을 하는 동안 문서 변경분에 대해 적용하기 힘들기 때문에 작업 속도는 빠르면 빠를 수록 좋지만, 작업 시 자원 사용량 또한 고려할 문제이기 때문에 이 역시 수치를 조정하면서 적용할 대상입니다.
트러블 슈팅
1. es_rejected_excutution_exception
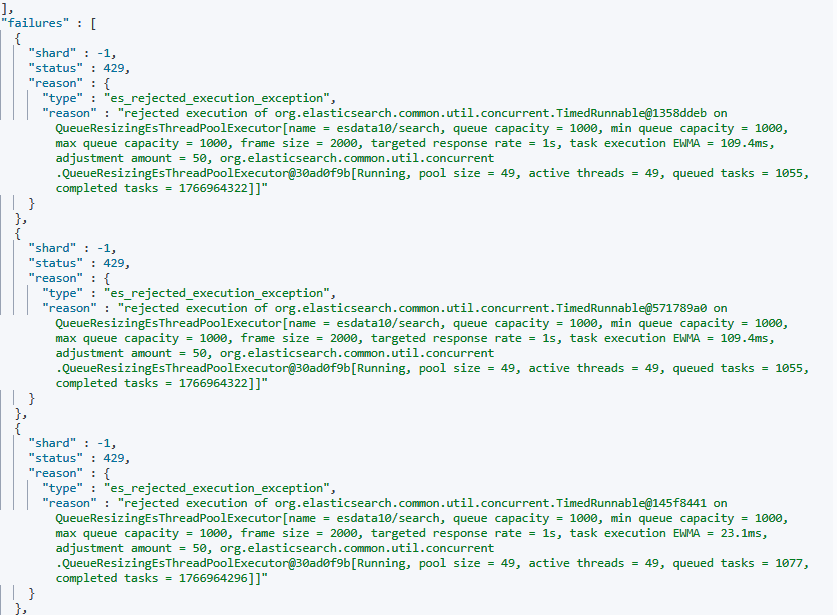
해당 메시지는 운영중 reindex를 진행하면서 실제 발생했던 메시지입니다. 결과적으로 reindex는 실패했고 많은 문서의 누락이 발생했습니다. A, B 두벌로 인덱스를 관리하고 있기 때문에 오색인된 인덱스로 변경되진 않았지만 결국 정상 색인되지 않았습니다.
이 로그는 기본적으로 검색 요청시 큐 자원이 부족하다는 뜻입니다. ES는 검색 요청이 들어오면 풀링을 통해 쓰레드 풀에서 쓰레드를 할당받아 사용하고 있는데, 최대로 설정된 1,000 이라는 큐 사이즈를 초과해서 발생한 것으로 볼 수 있습니다.
이를 해결하기 위해 다음과 같은 가정을 했습니다.
target_time = 1000 (기본 배치 사이즈) / 500 per second = 2 seconds
wait_time = target_time - write_time = 2 seconds - .5 seconds = 1.5 seconds
이 식은 reindex 시 쓰로틀링을 하는 산식으로 여기서 target_time을 조절해서 큐를 빨리 소진하도록 하는 wait_time을 증가시켜 사용량을 감소시켰습니다. 리사이징 이후 해당 현상은 감소하거나 발생하지 않게 되었습니다.
2. circuit_breaker_exception

ES 운영중에 종종 만나게 되는 circuit_breaker_exception 입니다. 메모리 사용량과 관련된 이슈로 작업 시간이 길다보니 중간 중간 검색, 색인 부하가 생기게 되면 발생할 수 있습니다. 이런 유형은 작업 시간대를 변경해보거나 옵션을 변경하면서 부하를 낮추도록 하는 방법이 있습니다.
reindex 종료 후 replica를 생성할 때도 해당 예외를 만날 수 있는데, 이때는 다음과 같이 replica를 생성하는 속도를 조금 늦춰보면 해결할 수 있습니다.
curl -XPUT localhost:9200/_cluster/settings -d '{
"persistent" : {
"indices.recovery.max_bytes_per_sec": "128mb"
}
}'
정리
대용량의 문서를 색인할 때 발생할 수 있는 문제점과 해결 방안을 정리해봤습니다. 설정값은 시스템 상황과 검색 / 색인 부하에 따라 각자 다르게 설정할 수 있겠습니다. 검색 상품은 로그나 모니터링 지표같은 데이터에 비해 필드 수도 많고 데이터도 방대하기 때문에 색인 시 큰 부하를 야기합니다. 이러한 대용량 색인 데이터를 가진 시스템을 구성할 때 참고하시면 좋겠습니다.