Elasticsearch Search After 성능 체크
개요
다나와 검색 상품 약 10억건 데이터 마이그레이션 방안으로 Search After 사용 가능 여부에 대한 성능 체크를 해보았습니다.
Pagination Search ?
엘라스틱서치의 경우 효율성을 위해 여러 샤드들에 데이터를 분산해 저장하고 있습니다.
10,000건의 정렬 데이터를 요청하면 각 샤드에서 10,000건씩 가져와 정렬한 뒤 10,000건을 반환합니다.
10,000건 이상을 조회하면 성능 혹은 메모리 문제가 발생할 수 있어 엘라스틱서치에서는 최대 검색 개수를 10,000개로 제한하고 있습니다.
엘라스틱서치에서는 모든 데이터를 조회할 수 있는 Scroll API와 Search After로 제공하고 있습니다.
Search After ?
Scroll API는 검색 결과를 묶어서 한 번에 가져오면서, 검색 결과를 스크롤 하는 기능을 제공합니다.
이 방식은 검색 결과를 기억하고 있어야 해서 메모리 부하가 생길 수 있습니다.
Search After는 Scroll API 방식과 달리 live coursor를 제공하면서 stateless이기 때문에 메모리 부하가 적습니다.
위와 같은 이유로 ES 공식 문서에서도 Scroll API 보다 Search After 사용 권장을 하고 있습니다.
Search After 사용 예시
1.
GET tcmpny_link/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
2.
GET tcmpny_link/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
# Search After + PIT + Sliced Scroll
GET tcmpny_link/_search
{
"size": 10000,
"slice": {
"id": 0,
"max": 10
},
"pit": {
"id" : "...",
"keep_alive": "1m"
},
"search_after": [10000],
"sort": ["_doc"]
}
Search After는 정렬 값을 이용하여 다음 결과를 가져옵니다.
정렬이 필요 없는 경우 _doc으로 정렬 시 성능이 가장 빠릅니다.
PIT (Point In Time) 란?
Elasticsearch 7.10 버전부터 사용 가능합니다.
인덱스의 특정 시점의 데이터 상태를 캡처하여 복원할 수 있는 기능입니다.
Search After 요청 사이에 인덱스 변경사항이 일어나면 결과 데이터가 일관되지 않을 수 있어 데이터 일관성을 맞추기 위해 PIT와 같이 사용합니다.
Sliced Scroll 란?
Scroll의 병렬 처리라고 생각하시면 됩니다.
Scroll Search와 PIT 에서만 사용 가능하며 인덱스의 샤드와 동일한 수의 슬라이스를 선택해야 성능이 좋습니다.
Scroll Search와 PIT에서만 사용 가능, [slice] can only be used with [scroll] or [point-in-time] requests
테스트 환경
엘라스틱서치
- 버전 : 7.8.1
- 노드 : 3(클러스터), 서버 3대
- 힙 메모리 : 57GB/95GB
문서
- 인덱스의 문서 수 (상품의 개수) : 약 6억 건
- 컬럼 개수 : 57개
- 샤드 개수 : 20개
- 레플리카 개수 : 1개
상품 1만개씩 가져오도록 설정 (size)
테스트 내용
case1)
| no | 검색 방식 | 병렬 처리 개수 | 가져온 상품 수 | 소요 시간 (초) | 시작 시간 | 종료 시간 |
|---|---|---|---|---|---|---|
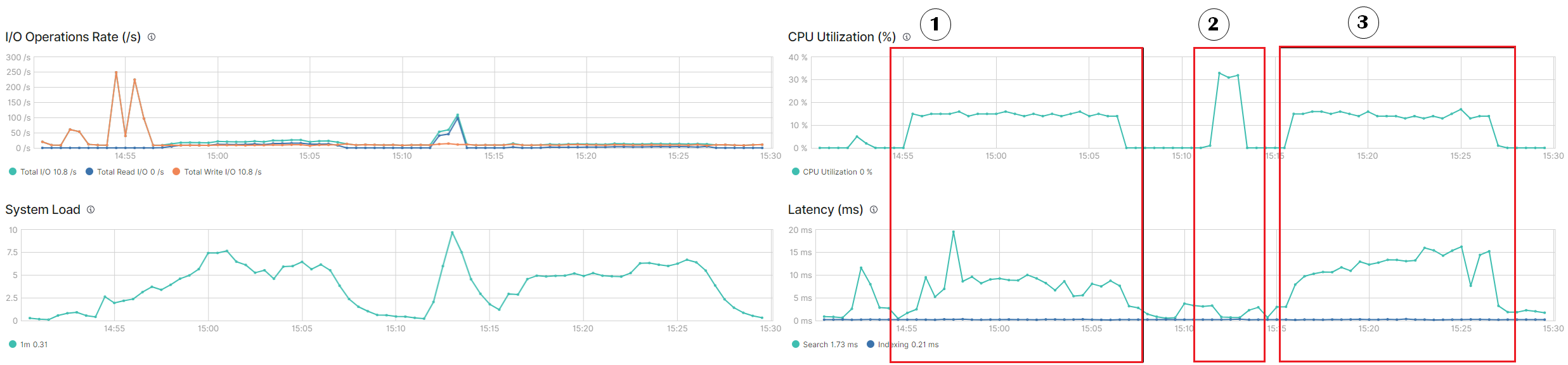
| 1 | Scroll API | 1 | 10,000,000 | 647 | 14:55:42 | 15:06:29 |
| 2 | Sliced Scroll | 20 | 10,000,000 | 66 | 15:12:12 | 15:13:18 |
| 3 | Search After | 1 | 10,000,000 | 657 | 15:15:55 | 15:26:53 |
case1 스택 모니터링 cpu그래프
테스트 환경
엘라스틱서치
- 버전 : 7.17.1
- 노드 : 3(클러스터), 서버 1대
- 힙메모리 : 2GB/6GB
문서
- 인덱스의 문서 수 (상품의 개수) : 약 2천만 건
- 컬럼 개수 : 57개
- 샤드 개수 : 10개
- 레플리카 개수 : 1개
상품 1만개씩 가져오도록 설정 (size)
case2)
| no | 검색 방식 | 병렬 처리 개수 | 가져온 상품 수 | 소요 시간 (초) | 소요 시간 (초) | 시작 시간 | 종료 시간 |
|---|---|---|---|---|---|---|---|
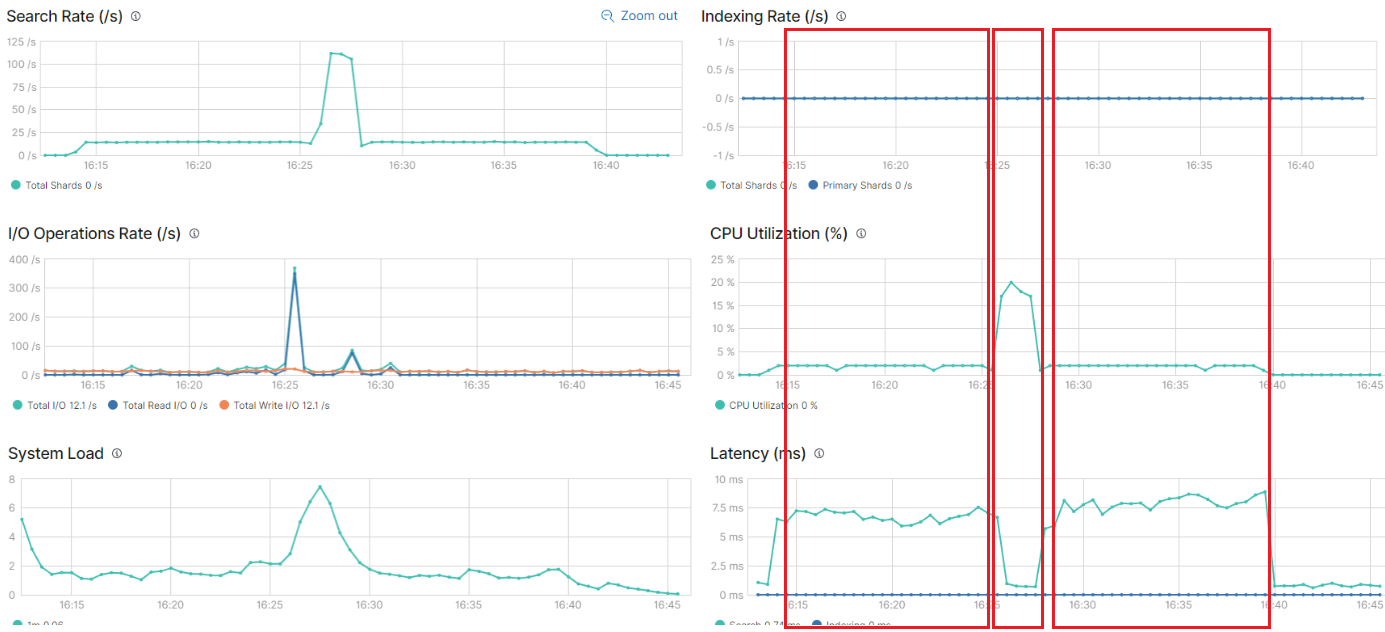
| 1 | Scroll API | 1 | 10,000,000 | 693 | 3% | 16:14:13 | 16:25:46 |
| 2 | Scroll API + Sliced Scroll | 10 | 10,000,000 | 91 | 20% | 16:26:11 | 16:27:42 |
| 3 | Search After | 1 | 10,000,000 | 692 | 3% | 16:27:59 | 16:39:32 |
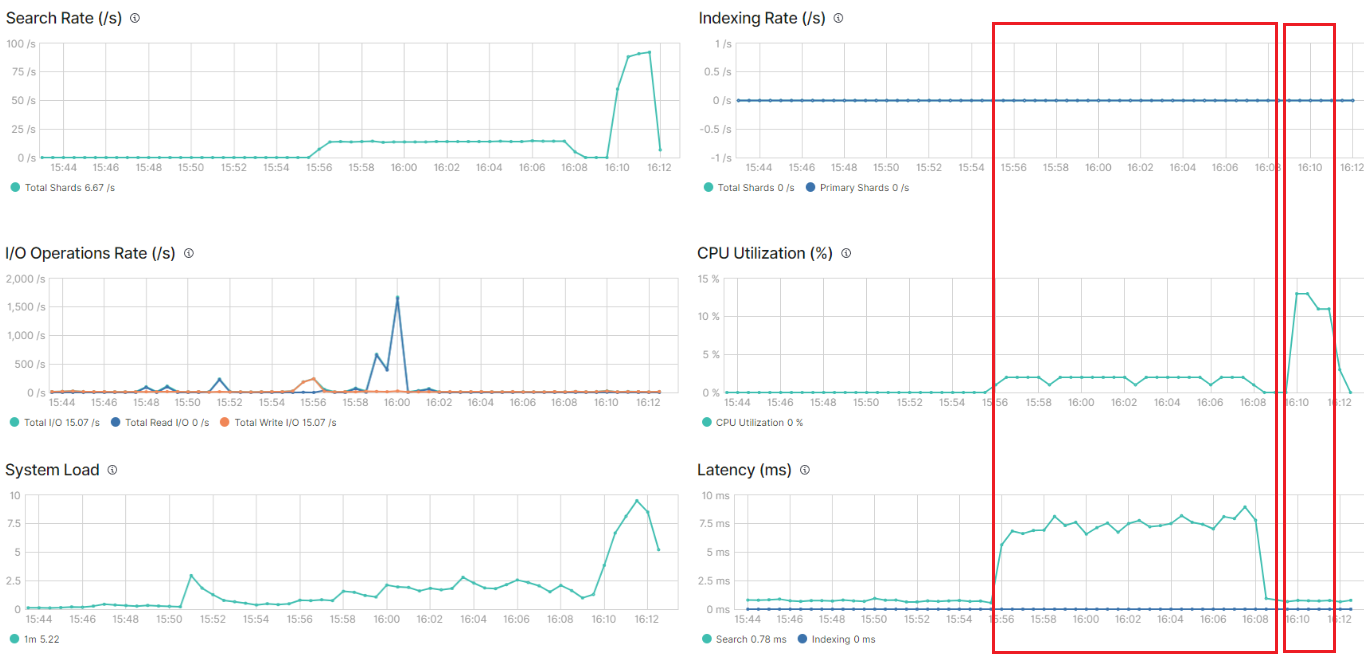
| 4 | Search After + PIT | 1 | 10,000,000 | 714 | 3% | 15:56:05 | 16:08:00 |
| 5 | Search After + PIT + Sliced Scroll | 10 | 10,000,000 | 112 | 15% | 16:10:00 | 16:11:52 |
case2 no1, 2, 3 스택 모니터링 cpu, search rate 그래프
case2 no4, 5 스택 모니터링 cpu, search rate 그래프
테스트 결과
위 테스트 2, 5번 케이스를 비교해 보면 아래와 같은 내용을 확인할 수 있습니다.
- Scroll API는 상대적으로 빠르고 효율적이지만 메모리에서 스크롤 컨텍스트를 추적해야 하므로 5번 케이스보다 CPU 사용량이 34% 정도 높았습니다.
- Search After는 정렬 값으로 표시되는 커서를 지정하여 메모리 오버헤드는 낮았으나 2번 케이스보다 속도가 23% 정도 느렸습니다.
두 가지다 장점과 단점이 있어 각각에 맞는 환경에 사용하시면 좋을 거 같습니다.
참고 자료
- https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html#search-after
- https://www.elastic.co/guide/en/elasticsearch/reference/current/sort-search-results.html#sort-search-results
- https://www.elastic.co/guide/en/elasticsearch/reference/current/point-in-time-api.html#point-in-time-api
- https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html#slice-scroll