Mecab과 Nori, Fastcat 플러그인 색인 성능 비교
 Photo by Joanna Wallace on coralogix
Photo by Joanna Wallace on coralogix
어떤 한국어 분석기를 사용할까 ?
다나와에서는 현재 Fastcat 기반의 상품명 분석기를 이용해서 검색과 색인을 처리하고 있습니다.
하지만 효율적인 유지보수 측면과 커뮤니티를 통한 지속적인 기능 향상이 어려워 신규 한국어 분석기를 탐색하게 되었습니다.
Mecab-ko는 오픈소스 한글 형태소 분석기로, Mecab 이라고 하는 일본어 형태소 분석기를 차용하여 한글 특성을 반영한 분석기입니다.
Nori는 엘라스틱서치에서 공식 지원하는 한글 형태소 분석기로, 역시 루씬 기반이며, 개발하는 커미터가 존재합니다.
분석기별 설정 방법
현재 검색 엔진에서 사용되는 엘라스틱서치 버전은 7.8.1 버전을 사용하고 있습니다.
Mecab-Ko
Mecab-Ko 초기 설정 방법은 아래를 참고해주세요. 여기서는 은전한닢에서 제공되는 가장 최신 버전을 사용합니다.
https://danawalab.github.io/common/2022/12/19/Mecab-Ko.html
Nori
Nori는 엘라스틱서치에서 다음과 같이 입력 및 재시작합니다. 또는 사용하는 버전의 엘라스틱서치 코드를 받아 직접 빌드하여 커스터마이징할 수 있습니다.
elasticsearch-plugin install analysis-nori
다나와 상품명 분석기
상품명 분석기는 private로 개발되어 있기 때문에 코드 오픈없이 진행하겠습니다. 사용 방법은 다른 플러그인과 유사하게 엘라스틱서치 기동 시 도커 볼륨으로 호스트와 연결해주겠습니다.
벤치 마크
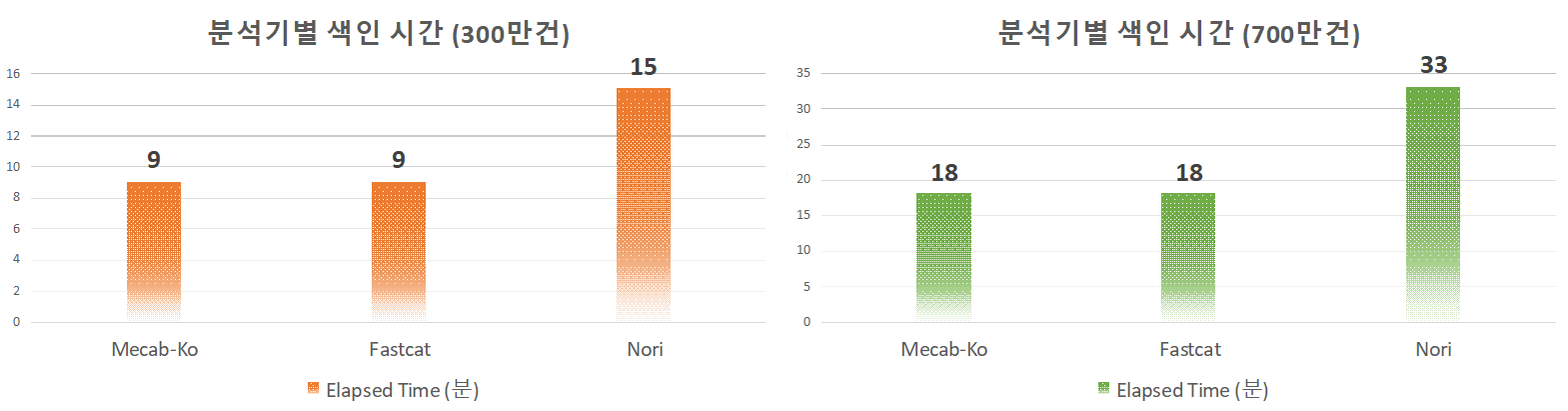
성능 비교를 위해 각각 300만, 700만 건 문서 수의 인덱스를 플러그인별로 색인해보았습니다.
현재 플러그인에는 색인 속도 향상을 위한 아무 옵션도 설정하지 않은 상태입니다. 결과를 보면 Mecab-Ko와 Fastcat의 성능이 동일하고, Nori는 다른 분석기들보다 속도가 열위인것으로 보입니다. 자료만 보았을 때 엘라스틱에서 공식으로 지원하는 플러그인치고 성능이 그렇게 뛰어나다고 볼 수는 없습니다.
또한 이 결과를 통해 알 수 있는 사실은 현재 다나와 시스템에서 Nori는 사용하기 적합하지 않은 것으로 보입니다. 다만 추가적으로 생각해보아야 할 점은 사전입니다. 사전이 많을 수록 색인할 때 후보군이 늘어나 색인시 필요한 사전만 컴파일해서 색인하는 테스트를 추가적으로 진행합니다.
~/mecab-ko-dic-2.1.1-20180720$ wc -l *.csv
148 CoinedWord.csv
2547 EC.csv
1820 EF.csv
51 EP.csv
133 ETM.csv
14 ETN.csv
11690 Foreign.csv
3176 Group.csv
125750 Hanja.csv
1305 IC.csv
44820 Inflect.csv
416 J.csv
14242 MAG.csv
240 MAJ.csv
453 MM.csv
140 NNB.csv
677 NNBC.csv
208524 NNG.csv
2371 NNP.csv
342 NP.csv
482 NR.csv
3 NorthKorea.csv
99230 Person-actor.csv
196459 Person.csv
19301 Place-address.csv
1145 Place-station.csv
30303 Place.csv
5 Preanalysis.csv
16 Symbol.csv
2360 VA.csv
7 VCN.csv
9 VCP.csv
7331 VV.csv
125 VX.csv
36762 Wikipedia.csv
83 XPN.csv
3637 XR.csv
19 XSA.csv
124 XSN.csv
23 XSV.csv
2 user-nnp.csv
1 user-person.csv
2 user-place.csv
816288 total
현재 약 81만개의 단어를 가지고 색인을 진행하고 있습니다. (최신 버전에는 더 추가되었을 수도 있습니다)
다나와는 주로 상품에 대한 검색 결과를 제공하고 있기 때문에 동사, 형용사, 인명, 지명, 북한사전(?) 등을 제거하여 다시 색인을 진행하겠습니다.
~/mecab-ko-dic-2.1.1-20180720$ wc -l *.csv
140 NNB.csv
677 NNBC.csv
205269 NNG.csv
2371 NNP.csv
342 NP.csv
482 NR.csv
5 Preanalysis.csv
209286 total
불필요한 사전을 정리해서 약 20만개까지 줄였습니다.
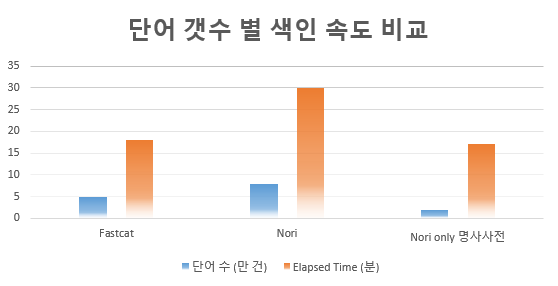
모두 700만건의 문서 수를 가진 인덱스의 색인 결과입니다. 위의 데이터를 보면 사전 갯수의 제거에 따라 색인 소요 시간(Elapsed Time)이 감소하는 것으로 나타났습니다. 따라서 다음과 같이 유추할 수 있습니다.
색인 시 사전이 적을수록 색인 성능이 좋아진다.
정리
기존에 사용하던 형태소 분석기외에 다른 분석기를 통해 색인을 하면 어떤 결과가 나올지 궁금증이 있었는데 이번 포스팅을 작성하면서 확실히 정리할 수 있었습니다. 성능 테스트 결과 기존 패스트캣 분석기 역시 다른 분석기와 동일한 성능을 보이고 있으므로 기존 코드를 리팩토링하여 효율적으로 유지보수하는 방안을 검토하고 있습니다.
참고 자료
공식 한국어 분석 플러그인 “노리” : https://www.elastic.co/kr/blog/nori-the-official-elasticsearch-plugin-for-korean-language-analysis