Elasticsearch Update_By_Query 적용 과정
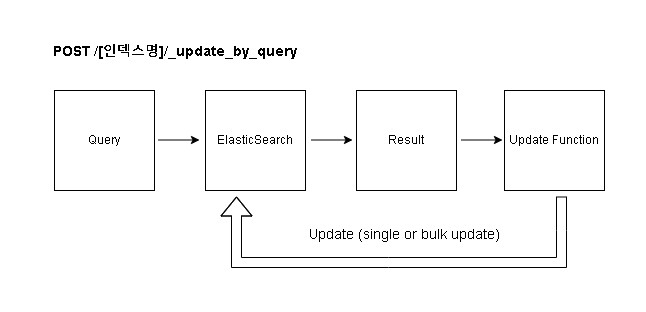
Update_by_query 진행 과정
소개 : Update_By_Query ?
Elasticsearch(이하 es)에서 기존에 색인된 내용을 변경하고자 할 때, Update_By_Query 기능을 사용할 수 있습니다. 이 기능은 단순히 업데이트를 수행하는것 뿐만 아니라 쿼리를 통한 질의 후에 해당하는 조건에 맞는 필드를 탐색하여 업데이트를 진행합니다.
취급하는 데이터의 양이 많다보니 일괄적으로 값을 변경해주는 기능이 필요했고, 기존 데이터 업데이트시 bulk api를 사용하고 있었지만 id를 통해 업데이트되는 방식이었습니다. 그래서 es에서 제공하는 Update_By_Query기능을 사용하게 되었습니다.
도입 시작
다나와에서는 하루에도 무수히 많은 상품 데이터를 분석, 수집, 처리하고 있습니다. 이렇게 많은 양의 데이터를 처리하는 동안에도 특정 필드의 값을 업데이트하는 로직을 정상적으로 수행 할 수 있어야 했습니다. 우선 7.8.1 버전의 기준에서 제공하는 HighLevelClient를 사용하여 Update_By_Query를 호출하는 방법을 검토했습니다.
작성한 내용은 다음과 같습니다. 1) 우선 UpdateByQueryRequest의 요청을 생성합니다.
UpdateByQueryRequest updateRequest = new UpdateByQueryRequest(index);
Map<String, Object> params = new HashMap<>();
params.put(targetField, targetValue);
updateRequest.setQuery(QueryBuilders.matchQuery(queryField, queryValue));
updateRequest.setScript(new Script(
ScriptType.INLINE,
"ctx._source."+ targetField +" = params." + targetField +";",
params));
업데이트하고자 하는 필드와 질의하고자하는 쿼리의 필드와 값을 각각 작성합니다. 기타 옵션값은 기본값을 사용했으며 검색 조건에 일치하는 데이터에 대해 업데이트를 요청합니다.
2) 요청을 실행합니다. HighLevelClient의 updateByQuery()
@Async
...
// `Update_By_Query`
BulkByScrollResponse response = restHighLevelClient.updateByQuery(updateRequest, RequestOptions.DEFAULT);
// Listen to Response
if(response.getBulkFailures().size() > 0){
for(BulkItemResponse.Failure fail : response.getBulkFailures()){
logger.error(queryField + " : " + queryValue + " " + fail.getMessage());
}
} else {
logger.info(queryField + " : " + queryValue + ", " + response.getUpdated() + " UPDATED");
}
updateByQuery() 메소드를 사용했습니다. request와 마찬가지로 디폴트 옵션을 사용했으며 결과 값을 리턴받으면 실패한 건에 대해 로그를 남기고, 몇 건이 업데이트되었는지 확인합니다.
요청 후 처리 결과를 살펴보겠습니다. 테스트 데이터는 es에서 기본으로 가지고 있는 Sample_flight_data 인덱스를 사용합니다.
weather : sunny, 4631 UPDATED
로컬 환경에서 구성된 처리 로직을 실행해보니 정상적으로 처리되었음을 결과를 통해 확인할 수 있었습니다.
진행 중 문제 발생
다음으로 테스트 서버 배포 후에 기능 테스트를 진행했습니다. 테스트 서버는 로컬 환경과 다르게 데이터의 취급 양이 보다 많기 때문에 실시간으로 많은 내용의 데이터가 업데이트 되는 것을 확인할 수 있습니다.
그런데 실행해보니, 다음과 같은 오류가 발생했습니다.
java.net.SocketTimeoutException: 5,000 milliseconds timeout on connection http-outgoing-95 [ACTIVE]
처음에는 단순히 동시에 처리되고 있는 작업량이 많아서 발생한 오류라고 생각했으나 다른 작업을 멈추고 실행했을때도 같은 현상이 발생했습니다.
이유는 데이터 양이 적은(약 4천건) 로컬 테스트 환경과 달리 실제 작업시 약 32만건의 데이터를 업데이트하는데 이 작업을 동기식으로 진행하고 있었습니다.
정해진 스케쥴의 시간동안 비동기식으로 진행해야하는 작업이었기에 @Async 어노테이션을 붙여주거나 updateByQueryAsync라는 다른 메소드를 사용하여 비동기식으로 호출하는 방법을 테스트해 보았습니다만, 어째선지 모두 같은 이유로 동기식으로 작동하고 있었습니다.
TroubleShooting
wait_for_completion 설정은 7.10 버전부터 가능
원인을 찾기 위해 elastic의 변경사항을 찾아봤습니다. 사실 필요한 부분은 wait_for_completion 설정 방법이었습니다. updateByQuery는 해당 옵션을 통해 작업이 완전히 완료될때까지 대기하도록 하는 옵션입니다. 그런데 7.8.1 기준으로는 이 값을 false로 설정할 수 있는 방법이 없었습니다.
따라서 HighLevelClient에서 자체적으로 제공하는 updateByQuery는 메소드를 사용하기에 제한되는 부분이었고, 이를 해결하기 위해 저수준의 클라이언트에서 직접 API호출을 통해 수행하는 방식을 검토했습니다.
RestClient restClient = restHighLevelClient.getLowLevelClient();
Request request = new Request(
"POST",
"/" + index + "/_`Update_By_Query`");
request.addParameter("wait_for_completion", "false");
request.addParameter("scroll_size", "100");
request.addParameter("timeout", "3m");
request.addParameter("slices", "10");
String entity = "{\n" +
" \"query\": {\n" +
" \"match\": {\n" +
" \""+ queryField+ "\": \"" + queryValue + "\"\n" +
" }\n" +
" }, \n" +
" \"script\": {\n" +
" \"source\": \"ctx._source." + targetField + "=params."+ targetField + "\"\n,"+
" \"lang\": \"painless\",\n" +
" \"params\": {\n" +
" \""+ targetField + "\": \"" + targetValue + "\"\n" +
" }\n" +
" }\n" +
"}";
request.setJsonEntity(entity);
Response response = restClient.performRequest(request);
다음과 같이 LowLevelClient를 사용한다면 wait_for_completion 옵션을 설정하여 백그라운드에서 비동기로 작업을 수행할 수 있고, 작업 코드를 받아 스케줄링을 통해 정기적으로 구독해서 작업 상태를 가져올 수 있을것이라고 생각했습니다.
코드를 작성한 후 이제 실행해 보겠습니다.
{"completed":true,"task":{"node":"SMKd7-zTQ_S-yrrp3iADZg","id":47667865,"type":"transport","action":"indices:data/write/update/byquery","status":{"total":324158,"updated":324158,"created":0,"deleted":0,"batches":3244,"version_conflicts":0,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1.0,"throttled_until_millis":0, ... more text
약 324,158건의 데이터가 정상적으로 업데이트 된것을 확인할 수 있었습니다. 하지만 시간이 약 5분정도 소요되었고, 처리 방식은 어떻게 되는지 파악하지 못했습니다. 이어서 작업시간을 줄일 방법과 작업 수행방식에 대해 알아보겠습니다.
Update_By_Query의 특이 사항
(1) 작업 중간에 실패하더라도 이미 UPDATE된 내용은 롤백하지 않는다.
RDBMS의 경우 업데이트시 중간에 오류가 발생하면 업데이트 되던 내용은 모두 롤백됩니다. 하지만 ES의 경우 오류가 발생하면 업데이트된 내용은 남겨둡니다. 이어서 작업을 즉시 중지하고 이후의 작업도 중지됩니다.
(2) CONFLICTS
es의 conflicts란 업데이트 진행시 대상 Document의 버전이 다른 작업의 진행으로 인해 업데이트 전 버전과 달라져서 발생합니다.
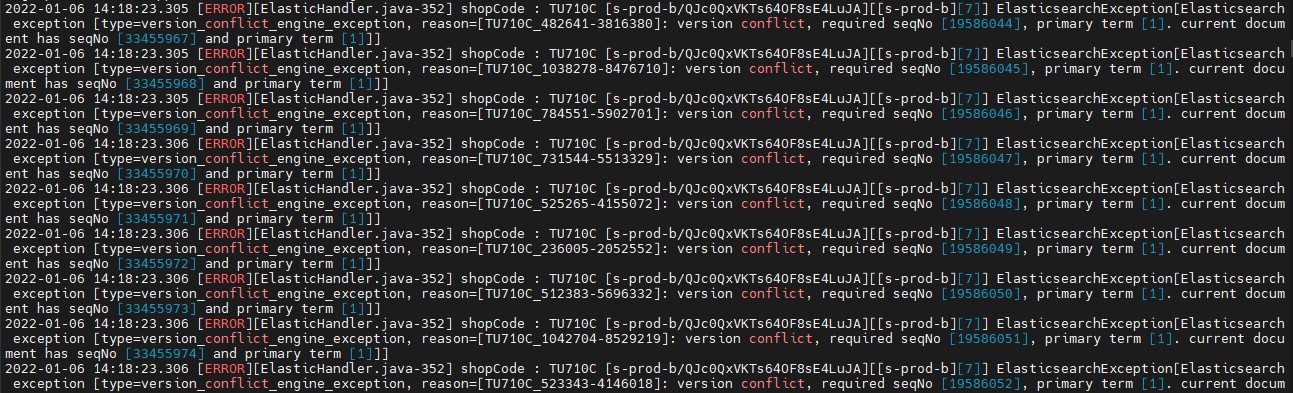
conflict 발생
Update_By_Query의 request 파라미터인 conflicts 옵션은 디폴트 값은 ‘abort’로 충돌이 발생시 그 상태에서 중지하게 되고, ‘proceed’로 옵션을 설정하면 충돌이 발생 시 멈추지 않고 변경하려는 내용으로 업데이트하게 됩니다.
(3) SLICES
Update_By_Query의 request 파라미터인 slices 옵션은 작업을 분할하여 처리하는 것을 의미합니다. 공식문서에서는 최적의 갯수로 샤드의 갯수 만큼을 추천하고 있습니다.
테스트 환경인 3개의 노드로 구성되어 10개의 샤드가 있는 인덱스에 대해 Update_By_Query 작업을 처리할 때, slice 갯수에 따라 업데이트 속도가 빨라지는 것을 확인할 수 있었습니다. 사용자 환경마다 다르겠지만 테스트 수행 시 10개의 slice 처리시 약 41초동안 32만건의 데이터를 처리했습니다.
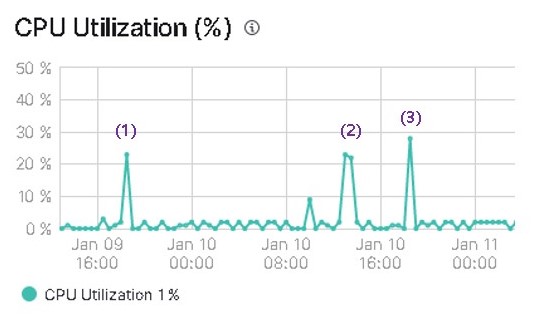
업데이트 수행시 CPU 사용량
업데이트 시 CPU 사용량입니다. (1)은 slice 설정없이 기본값으로 사용했을때 결과입니다. (2), (3)은 모두 slice를 10으로 설정했을때 결과입니다. 모두 20~30% 사이의 CPU 사용률을 보여주고 있습니다.
정리
작업 초기에 es 7.8.1 버전의 HighLevelClient를 사용하여 Update-by-query 기능을 사용하는 것이 설정하기도 간단하고 효율적일것이라고 생각했으나, 특정 설정으로 인해 사용할 수 없었던 문제가 있었습니다.
이 내용은 LowLevelClient를 사용해서 해결했으나, 업데이트 시에 slides, conflicts와 같은 옵션들도 확인해 볼 점이 필요했습니다. 다양한 테스트를 통해 최적화된 Update-by-query 처리를 시도해봐야할 것으로 보입니다.
참고 자료
- https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-update-by-query.html