엘라스틱 서치에서 색인된 문서의 사전 분석 내용 업데이트 하는 방법
소개
Elasticsearch는 이미 색인된 문서에 대해서는 사전에 관련 단어를 업데이트 하더라도 적용이 되지 않았습니다.
따라서, 이를 해결하기 위해서는 아래의 방법들을 사용해야 합니다.
- 1) 새 인덱스를 만들어 색인
- 2) reindex
- 3) update_by_query
이 포스팅에서는 update_by_query를 사용하는 방법과 update_by_query를 사용하여 사전 업데이트를 진행하는 방법을 상세히 설명해보겠습니다.
이번에 포스팅할 내용은 다음과 같습니다.
- 쿼리로 매칭된 문서 업데이트
- 이미 색인된 문서의 분석 내용 업데이트
쿼리로 매칭된 문서 업데이트
update-by-query는 쿼리로 매칭된 문서를 업데이트 할 수 있습니다.
elasticsearch에서 제공하는 한개의 문서를 업데이트 하는 기능 만으로는 충분하지 않을 때 사용할 수 있습니다.
아래와 같이 사용할 수 있습니다.
POST accounts-a/_update_by_query
{
// 업데이트를 할 내용을 명시하는 필드 입니다.
// 보통 ctx._source로 접근하여 필드들을 업데이트 합니다.
"script": {
"source": "ctx._source.count++",
"lang": "painless"
},
// 찾을 문서들을 쿼리로 검색합니다.
"query": {
"match_all": {
}
}
}
이번에 사용할 데이터는 엘라스틱서치에서 제공하는 샘플데이터 중 accounts 를 이용해보겠습니다. 인덱스명은 accounts-a로 생성했습니다. 샘플데이터 링크
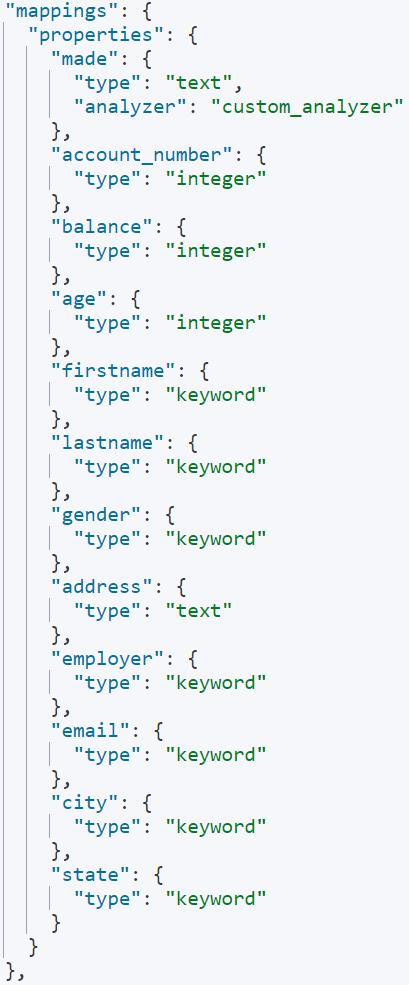
인덱스에 넣은 매핑과 셋팅은 아래 이미지와 같습니다.
매핑
셋팅
 —
먼저, 현재 나이가 30세 미만인 사람을 검색해보겠습니다.
—
먼저, 현재 나이가 30세 미만인 사람을 검색해보겠습니다.
POST accounts-a/_search
{
"query": {
"range": {
"age": {
"lt": 30
}
}
}
}

총 451건이 검색 되었습니다.
이번에는 update-by-query를 사용해 30세 미만인 사람들의 나이를 전부 2살씩 증가시키는 쿼리를 작성해 실행하겠습니다.
POST accounts-a/_update_by_query
{
"script": {
"source": "ctx._source.age = ctx._source.age + 2;",
"lang": "painless"
},
"query": {
"range": {
"age": {
"lt": 30
}
}
}
}
실행 결과로 이전에 검색한 갯수인 451건이 업데이트 된 것을 확인 할 수 있습니다.
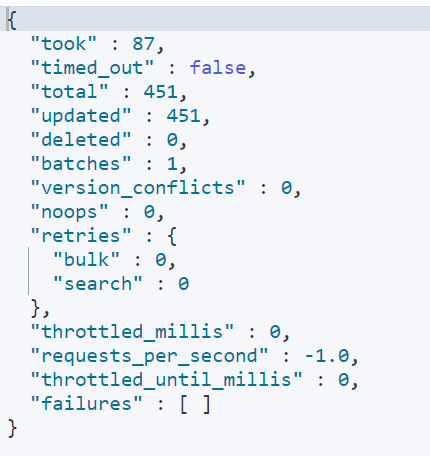
실제로 업데이트 되었는지 한번 내용을 확인해 보겠습니다.
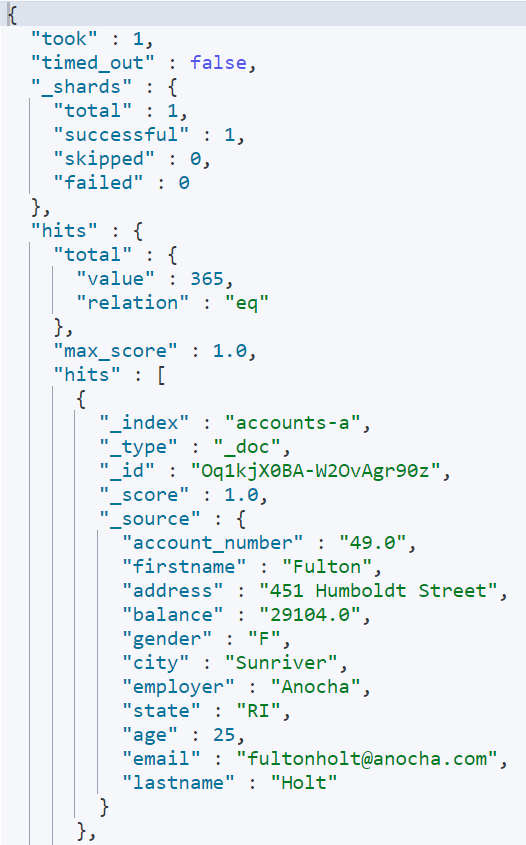
총 365건이 조회 되었습니다. 성공적으로 업데이트가 완료된 것을 확인 할 수 있었습니다.
이미 색인된 문서의 분석 내용 업데이트
이번에는 색인된 문서의 내용을 업데이트 하는 법을 알아보겠습니다.
먼저, 모든 문서에 데이터를 추가하겠습니다.
추가할 내용은 ‘다나다나와’ 입니다.
POST accounts-a/_update_by_query
{
"script": {
"source": "ctx._source.made = \"다나다나와\"",
"lang": "painless"
},
"query": {
"match_all": {}
}
}
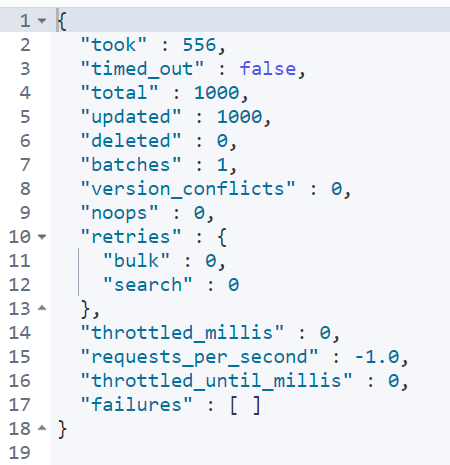
인덱스 안의 문서에 어떻게 분석이 되어 들어가있는지 확인해보겠습니다.
POST accounts-a/_termvectors/KK1kjX0BA-W2OvAgr90z
{
"fields": ["made"]
}

‘다나’ / ‘다나와’ 두개의 텀으로 분석이 되었습니다.
이제, 이 ‘다나’ / ‘다나와’로 분석된 내용을 ‘다나다나와’인 한 텀으로 분석 될 수 있게 변경해보겠습니다.
사전에 ‘다나다나와’를 추가해서 한번 확인해보겠습니다. (사전에 추가할 때에는 디서치 관리도구를 사용했습니다.)


POST accounts-a/_analyze
{
"analyzer": "custom_analyzer",
"text":"다나다나와"
}
사전을 적용하고 analyzer를 사용해 확인해보니 의도 했던 대로 ‘다나다나와’ 한개의 텀으로 나옵니다.

하지만 다시 아래의 쿼리로 분석된 내용을 확인해 보았더니 이전 사전으로 분석이 되어 있습니다.
POST accounts-a/_termvectors/KK1kjX0BA-W2OvAgr90z
{
"fields": ["made"]
}

다시, 새로운 사전을 적용한 분석기로 업데이트를 진행하겠습니다.
POST accounts-a/_update_by_query
{
"query": {
"match_all": {}
}
}
POST accounts-a/_termvectors/KK1kjX0BA-W2OvAgr90z
{
"fields": ["made"]
}

업데이트 된 텀 분석 내용으로 바뀐것을 확인 할 수 있습니다.
정리
엘라스틱서치에서 update-by-query를 사용하여 문서를 업데이트 하는 방법 및 분석기만 따로 업데이트 하는 내용을 확인했습니다.
데이터가 많지 않은 경우 다시 색인을 진행하거나, reindex를 사용하여 새롭게 분석된 문서를 유지할 수도 있지만 데이터가 많은 경우에는 색인 시간이 굉장히 오래 걸립니다.
하지만 앞으로 사전의 분석 내용을 변경 할 경우 update-by-query를 사용하여 새로 색인을 하지 않는 방법으로 진행하면 리소스 측면에서 많은 절약을 할 수 있을 것 같습니다.