elasticsearch scroll, slice(sliced scroll) 성능 비교
개요
다나와에서 사용하는 검색상품 현재 약 7억 건 데이터를 모두 조회하거나 특정 조건에 해당되는 상품을 대량으로 조회해야 하는 경우가 필요하여 elasticsearch의 scroll 과 slice 기능을 활용해서 성능 비교를 해보았습니다.
scroll search란?
scroll api는 하나의 검색 요청으로 대량의 결과나 모든 결과를 가져올 때 사용됩니다.
데이터베이스(database)의 커서(cursor)와 같은 방식으로 생각하시면 됩니다.
기존에는 페이징 처리를 위해서 사용했지만, ES 최신 버전 에서는 pit(point in time api)를 사용하는 것을 추천합니다.
slice : sliced scroll 란?
하나의 scroll query를 분할하여 독립적으로 사용 할 수 있는 다중 scroll api를 만드는 것 입니다.
scroll의 병렬 처리라고 생각하시면 됩니다.
테스트 환경
인덱스의 문서 수 (상품의 개수): 7억 건
컬럼 개수 : 88 개
샤드 개수 : 90 개
레플리카 개수 : 1개
상품 1만 개 씩 가져 오도록 설정 (size)
서버의 개수와 사양은 생략
테스트 내용
case1)
scroll 단일 쓰레드, slice 는 max 수치를 쓰레드 개수로 처리
샘플 데이터 개수(약 4천만 개 이상)를 조회하여 TPS를 계산
7억 건을 조회하는데 예상 시간 측정
*key만 조회 (컬럼 조회 없음)
| 검색 방식 | 병렬 처리 개수 | 샘플 데이터 개수 | 소요 시간 (초) | TPS | 7억 건 예상 조회 시간 | 1만 개 조회 당 평균 속도 (ms) |
|---|---|---|---|---|---|---|
| scroll | 1 | 40,010,000 | 981 | 40,784 | 286 분 | 194 |
| sliced scroll | 2 | 41,280,000 | 470 | 87,829 | 132 분 | 222 |
| sliced scroll | 4 | 46,310,000 | 255 | 181,607 | 64 분 | 214 |
| sliced scroll | 8 | 69,970,000 | 175 | 399,828 | 29 분 | 194 |
case2)
slice max 수치를 10으로 고정
약 7억 건을 실제로 조회
조회 컬럼 개수를 없음, 1개, 10개로 변경
소요 시간을 측정하여 TPS를 계산
| 검색 방식 | 병렬 처리 개수 | 조회된 데이터 개수 | 조회 컬럼 개수 | 소요 시간 (초) | TPS | 7억 건 조회 시간 | 1만 개 조회 당 평균 속도 (ms) |
|---|---|---|---|---|---|---|---|
| sliced scroll | 10 | 700,680,967 | 0개(없음) | 1522 | 460,368 | 25분 21초 | 200 |
| sliced scroll | 10 | 701,206,678 | 1개 | 2069 | 338,910 | 34분 27초 | 287 |
| sliced scroll | 10 | 705,648,840 | 10개 | 3231 | 218,399 | 53분 51초 | 443 |
case3)
slice max 수치를 10으로 고정
특정 조건을 추가하여 약 1억 건을 실제로 조회
조회 컬럼 개수를 3개, 25개로 변경
소요 시간을 측정하여 TPS를 계산
| 검색 방식 | 병렬 처리 개수 | 조회된 데이터 개수 | 조회 컬럼 개수 | 소요 시간 (초) | TPS | 조회 시간 | 1만 개 조회 당 평균 속도 (ms) |
|---|---|---|---|---|---|---|---|
| sliced scroll | 10 | 96,033,260 | 3개 | 356 | 269,756 | 5분 56초 | 355 |
| sliced scroll | 10 | 96,012,662 | 25개 | 1,010 | 95,062 | 16분 50초 | 1,035 |
테스트 결과
다양한 테스트 케이스를 통해서 대량으로 데이터를 가져올 때는 scroll 보다 sliced scroll를 사용하여 slice max 수치를 적정량 만큼 주는게 좋아 보였습니다. (*샤드 수보다 높아지면, 느려진다고 한다.)
그리고 가져오는 컬럼 수가 증가할수록 느려지기 때문에 필요한 컬럼만 기입하는게 가장 좋아 보였습니다.
간단한 필터 조건을 추가함에 따라서 성능 저하는 발견하지 못했습니다.
컬럼의 옵션을 주지 않고(모든 컬럼 가져오도록) 테스트는 해보지 않았지만, 결과가 궁금했습니다.
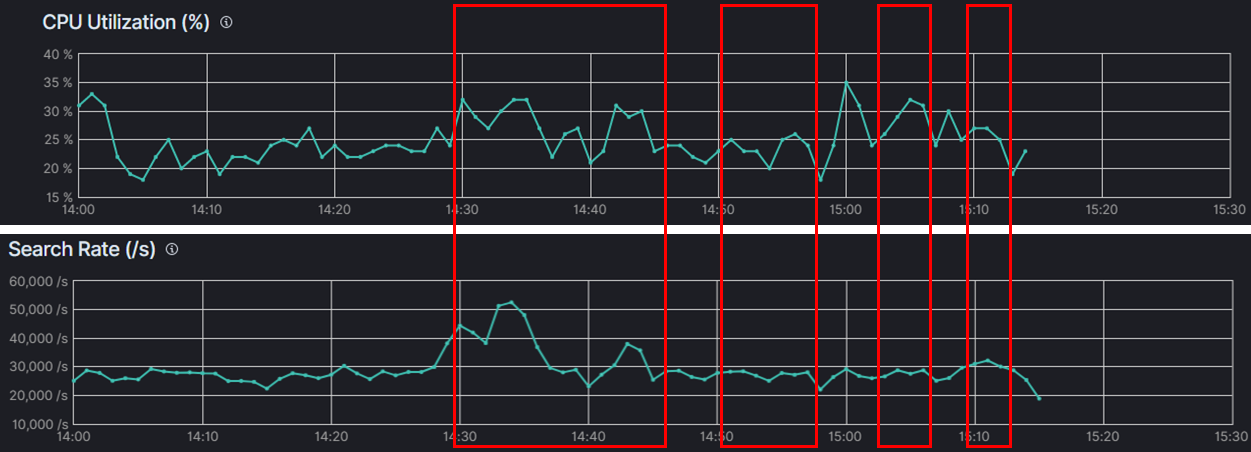
CPU 사용량은 다른 서비스가 되고 있는 상태여서 정확한 측정은 어렵지만, 사용량이 미비했으며 특이사항이 발견되지 않았습니다.
case1 cpu, search rate 그래프
참고 자료
- https://www.elastic.co/guide/en/elasticsearch/reference/current/scroll-api.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html#scroll-search-results
- https://www.elastic.co/guide/en/elasticsearch/reference/current/point-in-time-api.html