동적색인 프로세스 변경 사례
소개
이번에 제휴사에서 대량 처리하기 위한 동적색인 사례를 소개합니다. 기존 구성은 제휴사에서는 변경 데이터가 dynamicIndex(이하 DI) API로 요청이 오게되면, DI에서는 큐에 적재하고, DI 내부 스케줄을 통해 큐의 메시지를 소비합니다. 예전에는 하나의 프로세스를 통해 충분히 대응이 가능하였지만 어느 순간 부터는 큐의 처리량이 부족하여 큐 메시지 소비 전용 프로세스인 dymaicIndexProcess(이하 DIP)를 통해 큐의 메시지 소비량을 높혀 사용하였습니다. 현재는 제휴사 한곳에서 약 1억건 이상의 요청이 오기 때문에 두 프로세스만으로는 소비보단 적재하는 TPS가 크기 때문에 큐에는 늘 소비 되지 못한 메시지가 쌓여 있었습니다. 제휴사에서는 점점 데이터양이 늘어나고 있고, 노후화된 프로세스라 전체 구조를 변경하기로 결정하였습니다.
변경 전
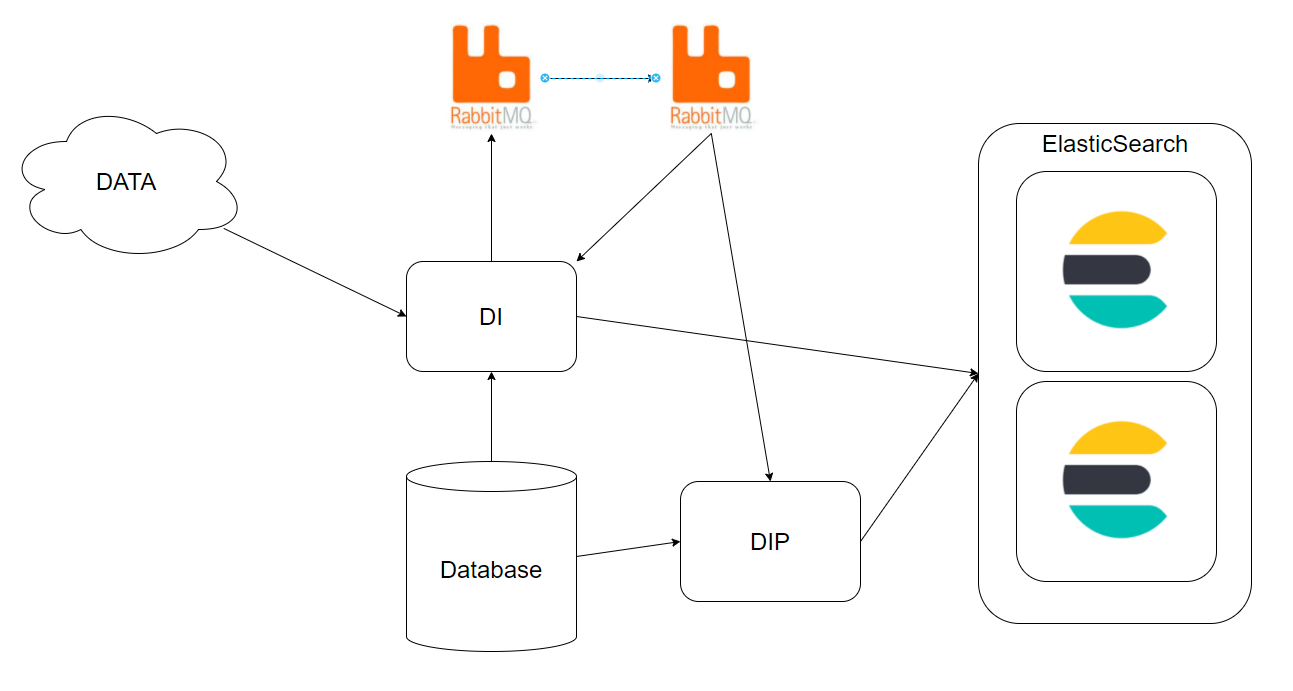
1 제휴사의 DATA가 DI로 요청이 오면 RabbitMQ의 큐에적재합니다.
2 스케줄을 통해 DI, DIP에서는 RabbitMQ 메시지를 500건씩 가져와 제휴사의 DATA에 있는 키를 기준으로 DB 조회합니다.
3 DB에서 가져온 데이터를 가공하여 ElasticSearch으로 벌크 색인요청합니다.
변경 전 구성도)
기존 DI, DIP에서는 멀티 쓰래드를 지원하지 않아, 2개의 프로세스에서 처리하기때문에 처리 성능이 부족하고, 아래와 같이 복잡한 구성이였습니다.
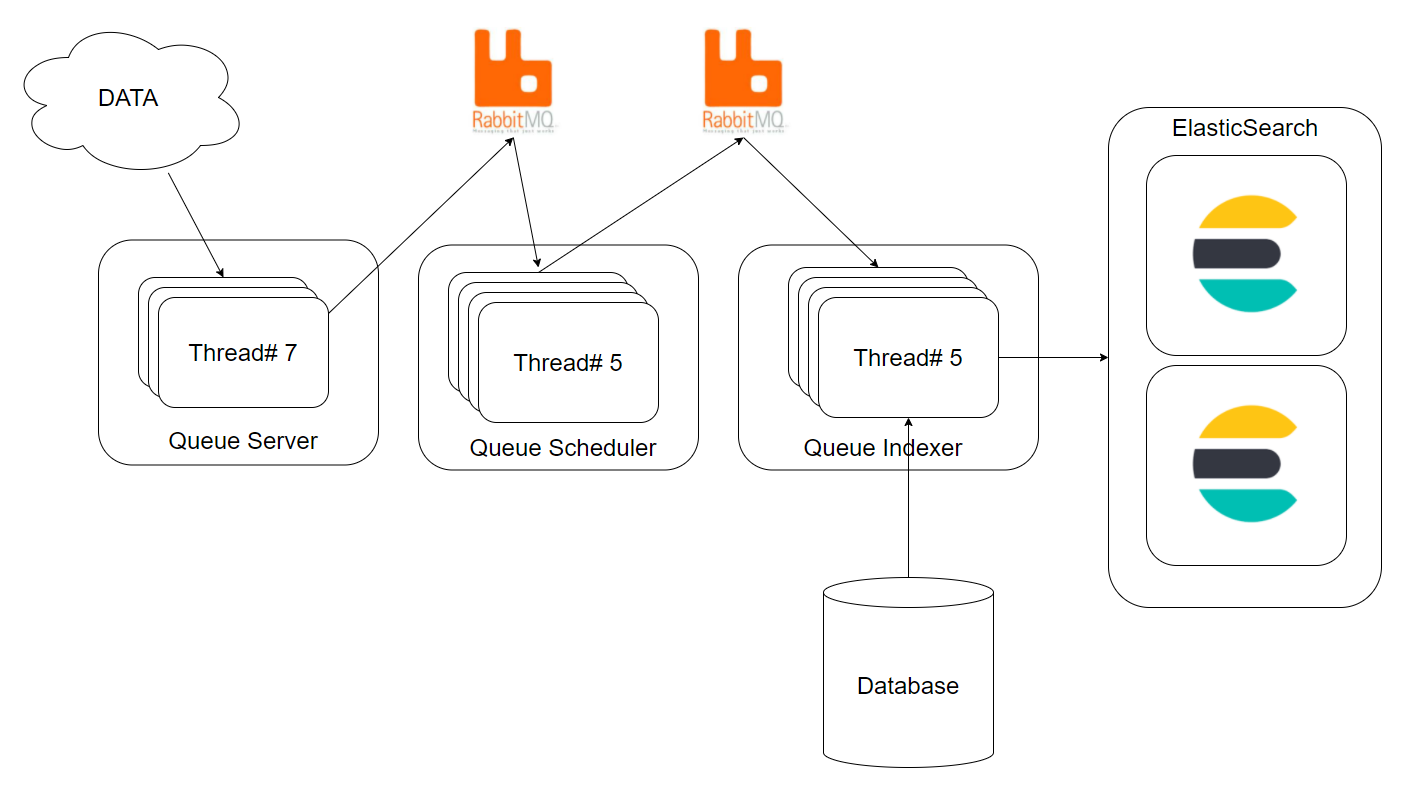
변경 후
1 기존 구성도와 비교하여 단순화되었습니다.
2 Q 서버, Q 스케줄러, Q 인덱서의 역할이 명확해졌습니다.
3 각 프로세스에서는 처리로직이 멀티 쓰래드 방식으로 구현되었습니다.
4 성능에 관련된 모든 수치는 설정을 통해 변경이 가능해졌습니다.
변경 후 구성도)
Queue Server 란?
큐 서버에는 API를 제공하여 제휴사에서 대량의 요청을 받게 됩니다. 받은 모든 요청은 RabbitMQ 메시지로 즉시 적재합니다. 이렇게 하게되면 제휴사의 요청에 대한 처리를 최대한 지연없이 요청을 받을 수 있고, 서버에 부하를 줄일 수 있습니다. Q 서버에서는 기존 DI제공하던 API와 동일하게 구현하였습니다.
Queue Scheduler 란?
큐 스케줄러는 큐 서버에서 적재하는 큐메시지를 인덱서가 컨슘하는 큐로 이동을 해주는 역할을 합니다. 큐 서버에서 즉시 인덱서가 컨슘을해도 문제는 없겠지만, 일시적 대량의 메시지가 요청되었을때 쓰로틀링기능으로 사용할 수있어 두개의 큐를 사용하게 됩니다. 스케줄러는 정해진 크론주기에 따라 메시지를 가져와 큐 인덱서가 컨슘하는 큐로 보내도록 합니다.
설정 내용)
해석을 하자면 APL2 큐 → Q_INDEX1 큐 이동하는 쓰래드가 1개 생성되며, 1초마다 1천개 메시지를 이동합니다. 그리고 TSHOP 큐 → Q_INDEX2로 10초마다 5천개씩 메시지를 이동합니다.
sever.port=8090
delivery.cron=*/1 * * * * *,*/5 * * * * *,*/10 * * * * *
delivery.period=1000,3000,5000
delivery.source.queue-name=APL2,PDM,TSHOP
delivery.source.host=127.0.0.1
delivery.source.port=5672
delivery.source.username=guest
delivery.source.password=guest
delivery.target.queue-name=Q_INDEX1,Q_INDEX1,Q_INDEX2
delivery.target.host=127.0.0.1
delivery.target.port=5672
delivery.target.username=guest
delivery.target.password=guest
큐 → 큐 이동하는 주요 로직은 아래와 같습니다. run 메서드에선 컨슘과 퍼블의 메인 처리로직입니다. consumption 메서드에서 서버에 쌓인 큐를 설정에 따라 n개 조회하고 결과를 리턴합니다. 그러면 publish메서드를 통해 큐 인덱서가 소비하는 큐에 n개의 메시지를 send 합니다.
public void run() {
List<byte[]> messages = null;
try {
messages = consumption();
if (messages.size() > 0) {
logger.info("[{}] period: {}, {} ==> {} message: {}", id, period.get(id), sourceQueueName, targetQueueName, messages.size());
publish(messages);
}
} catch (Exception e) {
logger.error("[Delivery ERROR] ", e);
if (messages != null && pushIndex < messages.size()) {
for (int i = pushIndex; i < messages.size(); i++) {
failedLogger.error("[publisher Fail] Service Queue: {}, message: {}", targetQueueName, new String(messages.get(i)));
}
}
}
}
public List<byte[]> consumption() throws InterruptedException, IOException {
List<byte[]> messages = new ArrayList<>();
try {
blockingQueueConsumer.start();
for (int i = 0; i < period.get(id); i++) {
Message message = blockingQueueConsumer.nextMessage(1000);
if (message == null) {
break;
}
messages.add(message.getBody());
blockingQueueConsumer.commitIfNecessary(false);
}
} finally {
try {
blockingQueueConsumer.stop();
} catch (Exception ignore) {}
}
return messages;
}
@Async
public void publish(List<byte[]> messages) {
int messageSize = messages.size();
for (int i = 0; i < messageSize; i++) {
try {
rabbitTemplate.send(targetQueueName, new Message(messages.get(i), new MessageProperties()));
pushIndex = i;
} catch (Exception e) {
failedLogger.error("[publisher Fail] Service Queue: {}, message: {}", targetQueueName, new String(messages.get(i)));
}
}
}
Queue Indexer 란?
큐인덱서는 큐의 메시지를 소비하며, 필터를 통해 메시지를 가공을 거쳐 엘라스틱서치에 벌크 색인을 진행합니다. 큐 인덱서에서는 큐마다 기준상품, 검색상품등등 처리하는 로직이 다르고, 변경에 우연해야될거 같았습니다. 아래 주요 코드를 보며 설명하겠습니다.
아래는 큐에서 컨슘받는 로직입니다. RabbitMQ SDK에서 제공하는 DefaultConsumer 상속받아 구현하였습니다. handleDelivery 메서드를 통해 메시지를 받게되고, 받은 메시지는 변환을 거쳐 buffer에 추가하게 됩니다.
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
// logger.debug("{} >> {} message: {}", name, queueName, new String(body));
List<T> messages = parseMessage(new String(body, StandardCharsets.UTF_8));
for (T message : messages) {
Delivery<T> delivery = parseMessage(envelope.getDeliveryTag(), message);
if (delivery != null) {
// TODO buffer 에 메시지가 꽉차게 되면..?
try {
buffer.put(delivery);
} catch (InterruptedException ignore) {}
}
}
if (getChannel() != null && getChannel().isOpen()) {
getChannel().basicAck(envelope.getDeliveryTag(), false);
}
}
아래는 버퍼에 쌓인 메시지를 필터링과 엘라스틱서치 벌크 색인하는 메인 로직입니다. buffer.drainTo를 통해 설정에 정해진 수치의 메시지만큼을 받아 indexerFilters 통해 필터과정을 거치게 됩니다. 그리고 메시지를 elasticHandler.indexBulk 를 통해 변환된 메시지를 색인하게 됩니다. elasticHandler는 restHighLevelClient를 랩핑한 인스턴스입니다.
@Override
public Boolean call() throws Exception {
while(true) {
try {
stopWatch = new StopWatch("[" + id + "] QueueIndexerListener StopWatch");
stopWatch.start("Queue Buffer filled");
int remainSize = bufferMaxSize;
List<Delivery<?>> deliveries = new ArrayList<>();
for (long start = System.currentTimeMillis(); System.currentTimeMillis() - start < bufferMaxIntervalMs; ) {
if (buffer.size() > 0) {
int count = buffer.drainTo(deliveries, remainSize);
remainSize -= count;
// logger.debug("Fetch {} docs <<< Q ({})", deliveries.size(), count);
}
if (remainSize <= 0) {
break;
} else {
Thread.sleep(500);
}
}
stopWatch.stop();
if (deliveries.size() > 0) {
int deliveriesSize = deliveries.size();
String idStr = String.valueOf(id);
Map<String, List<Delivery<?>>> deliveriesForQueue = new HashMap<>();
for (int i = 0; i < deliveriesSize; i++) {
Delivery<?> delivery = deliveries.get(i);
String queue = delivery.getQueue();
deliveriesForQueue.computeIfAbsent(queue, k -> new ArrayList<>());
delivery.getMeta().put("id", idStr);
deliveriesForQueue.get(queue).add(delivery);
}
deliveriesForQueue.forEach((queue, value) -> {
try {
stopWatch.start("[" + queue + "] Filter Elapsed Time");
if (indexerFilters.get(queue) != null) {
value = indexerFilters.get(queue).filter(value);
}
stopWatch.stop();
if (!test) {
stopWatch.start("[" + queue + "] Elastic Bulk Request Elapsed Time");
elasticHandler.indexBulk(value);
stopWatch.stop();
logger.info("index finished. doc Size: {}", value.size());
} else {
logger.info("index finished. doc Size: {}", value.size());
}
} catch (Exception e) {
logger.error("queue: {}", queue);
logger.error("Filter ERROR", e);
}
});
}
} catch (Throwable t) {
logger.error("Error", t);
} finally {
// 10초 이상일때만.. 로그찍기..
int maxElapsedSecond = 10;
if (stopWatch != null && stopWatch.getTotalTimeSeconds() > maxElapsedSecond) {
logger.debug("\n[" + maxElapsedSecond + "초 이상 소요됨]\n{}", stopWatch.prettyPrint());
}
if (exitSignal.contains(id)) {
exitSignal.remove(id);
logger.info("Queue Indexer Thread#{} Closed.", id);
break;
}
}
}
return true;
}
아래 로직은 RestHighLevelClient를 랩핑하여 구현한 ElasticHandler 입니다. 메시지의 내용중 기존엘라스틱서치의 문서를 지워야할때 또는 문서를 색인 후 다른 인덱스에 삭제 트리거가 되어야할때가 필요하여 아래와 같이 구현하였습니다.
public class ElasticHandler {
... (중략)
@Async
public void indexBulk(List<Delivery<?>> deliveries) throws Exception {
... (중략)
// Prev
TimeValue prevDeleteTimeValue = TimeValue.ZERO;
if (prevDeleteCount > 0) {
for (int retry = 0; retry < retryCount; retry++) {
try {
BulkResponse response = restHighLevelClient.bulk(prevDeleteBulkRequest, RequestOptions.DEFAULT);
prevDeleteTimeValue = response.getTook();
break;
} catch (Exception e) {
logger.error("Document Prev Delete Request Fail.", e);
try {
Thread.sleep(500);
} catch (Exception ignore){}
}
}
}
// Index
TimeValue indexTimeValue = TimeValue.ZERO;
if (indexCount > 0) {
for (int retry = 0; retry < retryCount; retry++) {
try {
BulkResponse response = restHighLevelClient.bulk(indexBulkRequest, RequestOptions.DEFAULT);
indexTimeValue = response.getTook();
break;
} catch (Exception e) {
logger.error("Document Index Request Fail.", e);
try {
Thread.sleep(500);
} catch (Exception ignore){}
}
}
}
// Update
TimeValue updateTimeValue = TimeValue.ZERO;
if (updateCount > 0) {
for (int retry = 0; retry < retryCount; retry++) {
try {
BulkResponse response = restHighLevelClient.bulk(updateBulkRequest, RequestOptions.DEFAULT);
updateTimeValue = response.getTook();
break;
} catch (Exception e) {
logger.error("Document Update Request Fail.", e);
try {
Thread.sleep(500);
} catch (Exception ignore){}
}
}
}
// Delete
TimeValue deleteTimeValue = TimeValue.ZERO;
if (deleteCount > 0) {
for (int retry = 0; retry < retryCount; retry++) {
try {
BulkResponse response = restHighLevelClient.bulk(deleteBulkRequest, RequestOptions.DEFAULT);
deleteTimeValue = response.getTook();
break;
} catch (Exception e) {
logger.error("Document Delete Request Fail.", e);
try {
Thread.sleep(500);
} catch (Exception ignore){}
}
}
}
// trigger Delete
TimeValue triggerDeleteTimeValue = TimeValue.ZERO;
if (triggerDeleteCount > 0) {
for (int retry = 0; retry < retryCount; retry++) {
try {
BulkResponse response = restHighLevelClient.bulk(triggerDeleteBulkRequest, RequestOptions.DEFAULT);
triggerDeleteTimeValue = response.getTook();
break;
} catch (Exception e) {
logger.error("Document Delete Request Fail.", e);
try {
Thread.sleep(500);
} catch (Exception ignore){}
}
}
}
logger.debug("[Bulk] PrevDelete Size: {} Elapsed: {}, " +
"Index Size: {} Elapsed: {}, " +
"Update Size: {} Elapsed: {}, " +
"Delete Size: {} Elapsed: {}, " +
"TriggerDelete Size: {} Elapsed: {}",
prevDeleteCount, prevDeleteTimeValue,
indexCount, indexTimeValue,
updateCount, updateTimeValue,
deleteCount, deleteTimeValue,
triggerDeleteCount, triggerDeleteTimeValue
);
}
}
주요 설정)
indexer.input.queue: 소비할 큐를 지정합니다.
indexer.input.thread-count: 소비에 필요한 쓰래드 수치입니다. (ex: 1이면 컨슘 연결1개)
indexer.output.thread-count: 메시지를 필터 처리에 사용되는 쓰래드 수치. 필터마다 쓰래드를 지정할 수 있습니다.
indexer.output.buffer-max-size: 내부적인 메시지처리를 위한 버퍼에 500개씩 쌓아서 처리합니다.
indexer.output.buffer-max-interval-ms: 버퍼에 500개가 안차도 0.5초 후 메시지를 처리합니다.
queue.filter: 큐마다 각각 다르게 구현된 필터를 사용할 수 있습니다. (기본값: emptyFilter)
elastic.thread.core-pool-size: 엘라스틱서치에 벌크색인 코어 쓰래드 풀 크기입니다.
elastic.thread.max-pool-size: 엘라스틱서치에 벌크색인 최대 쓰래드 풀 크기입니다.
elastic.thread.queue-capacity: 엘라스틱서치에 벌크색인 쓰래드의 큐 크기입니다.
indexer.input.queue=QINDEX_1,QINDEX_2
indexer.input.thread-count={ALLIED_CONTROL: "1"}
indexer.output.thread-count=1
indexer.output.buffer-max-size=500
indexer.output.buffer-max-interval-ms=500
queue.filter={ \
QINDEX_1: "tshopFilter", \
QINDEX_2: "testFilter"
}
elastic.thread.core-pool-size=1
elastic.thread.max-pool-size=1
elastic.thread.queue-capacity=50
성능 테스트
성능 테스트의 결과는 다나와 기준이며, 환경에 따라 차이가 있을 수있습니다. 내부 로직에서 예상 지연이 되는 지점이 DB 조회로 판단되어 Database 최대 TPS 측정한 수치가 15,000 ~ 20,000 TPS이기 때문에 큐 인덱서의 최대 예상 TPS도 유사할거로 예상됩니다.
아래 결과를 보았을때 쓰래드 갯수를 16으로 설정했을때 TPS와 CPU 사용량이 최적의 수치로 보였습니다. 그리고 쓰래드당 대략 약 1,500TPS 메시지를 처리하는 모습을 확인 할 수 있습니다.
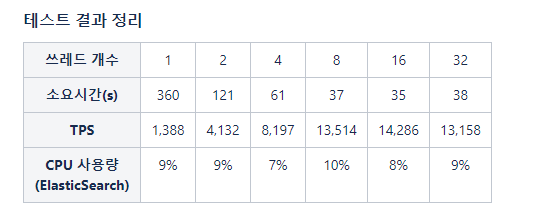
정리
이번에 다나와에서 동적색인 시스템의 구조를 변경해보았습니다. 기존 DI, DIP 프로세스를 통해 최대 2,000TPS에 비해 테스트에선 14,000 TPS 정도 높아진걸 확인 할 수 있었습니다. 성능 테스트 시점에서 서버의 컨디션에 지연이 되어 수치가 적게 나왔고, 실제 운영에 사용될때는 20,000TPS가 나오는걸 확인하였습니다. 현재 큐 서버, 큐 스케줄러, 큐 인덱서가 깃헙에 오픈되진 않았지만 시스템 구현시 참고가 되었으면 합니다. 감사합니다.