디서치 관리도구 사용법 #6 - 컬렉션
소개
이번 포스팅 내용은 다나와에서 개발한 디서치 관리도구(엘라스틱서치 관리도구)에서 컬렉션 메뉴에 대해 소개하는 시간을 가지도록 하겠습니다.
컬렉션 메뉴란?
컬렉션 메뉴는 엘라스틱서치의 두개의 인덱스를 묶어 하나의 인덱스 처럼 사용하기 위한 메뉴입니다.
엘라스틱서치에서 검색기능을 제공하기 위해 데이터를 색인 기능, 노드 전파, 인덱스를 교체하는 기능이 들어가 있습니다.
다양한 타입의 원본소스(DB 테이블 및 csv, ndjson, file 등)에서 색인을 지원하며, 보다 효율적이며 빠른 문서 등록이 가능합니다.
관리도구에서 색인을 지원하지만, 분산된 환경 또는 고급기능이 필요한 상황에서 색인에 특화된 전용인덱서를 제공하고 있습니다. 엘라스틱서치에서 색인 전/후 추가 로직을 구현할 수 있도록 제공하고 있습니다.
디서치 전용인덱서 URL : https://github.com/danawalab/dsearch-indexer
컬렉션 메뉴 사용법
처음 화면
컬렉션 메뉴를 클릭 했을 때의 화면입니다.

컬렉션 추가
컬렉션을 한번 추가해 보겠습니다.
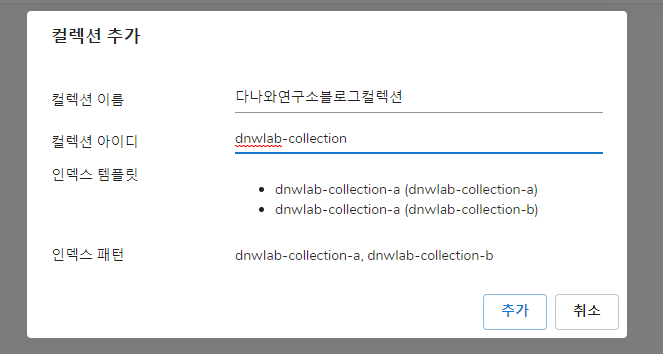

컬렉션 상세 메뉴
컬렉션이 생성 되었다면, 해당 컬렉션을 클릭하여 컬렉션 상세 메뉴로 들어 갈 수 있습니다.
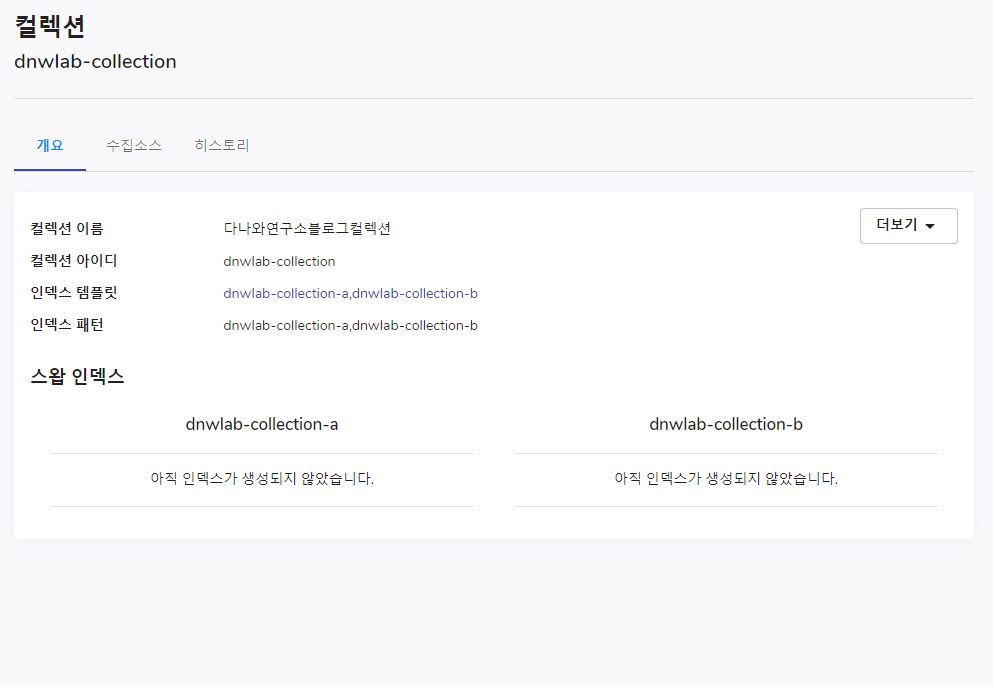
이곳에서는 컬렉션에 대한 개요 및 수집 소스, 히스토리를 볼 수 있습니다.
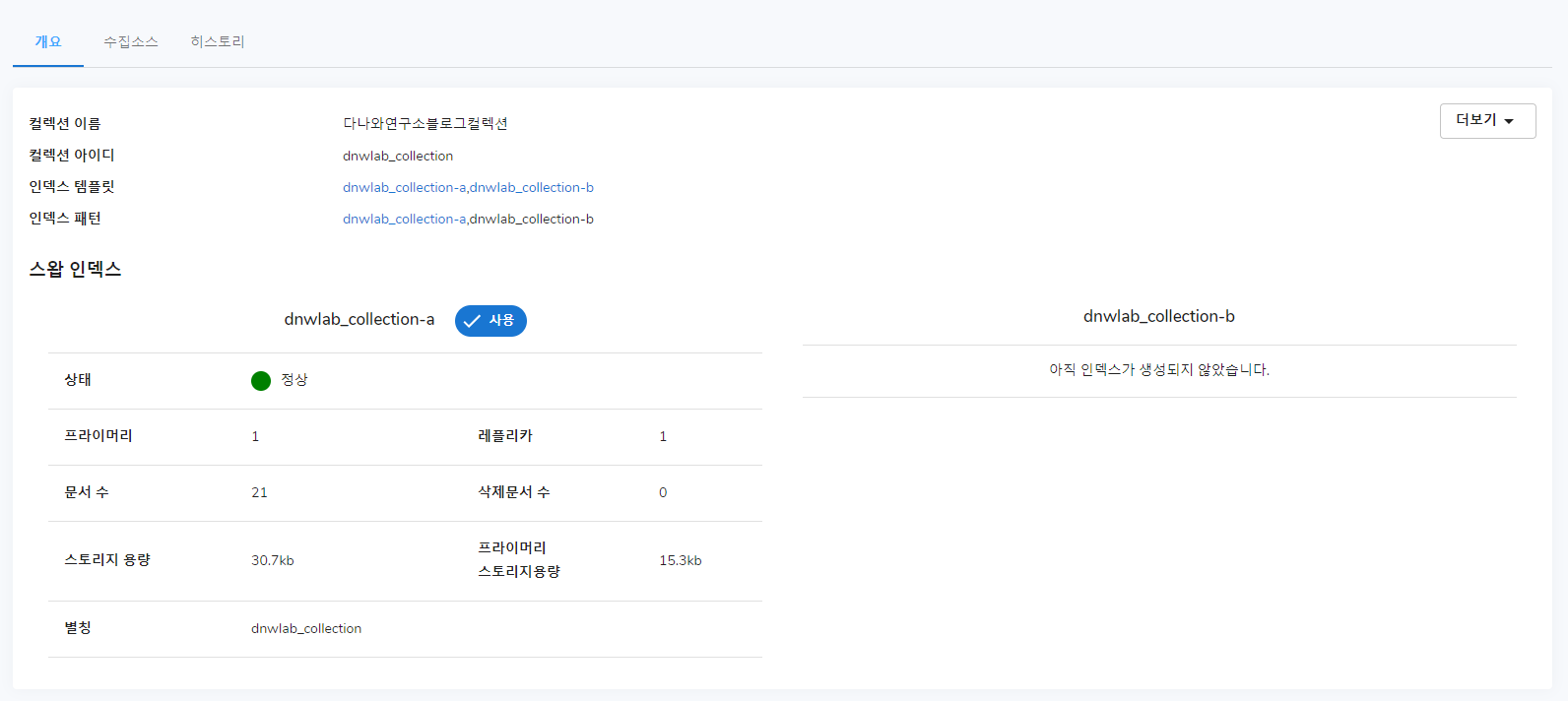
컬렉션 개요
컬렉션 개요에서는 컬렉션에 대한 요약 정보 및 인덱스 템플릿, 인덱스 패턴에 대해서 볼 수 있고, 스왑할 수 있는 인덱스들에 대해 간략히 보여줍니다. 또한, 이 컬렉션에 대한 삭제가 가능합니다.
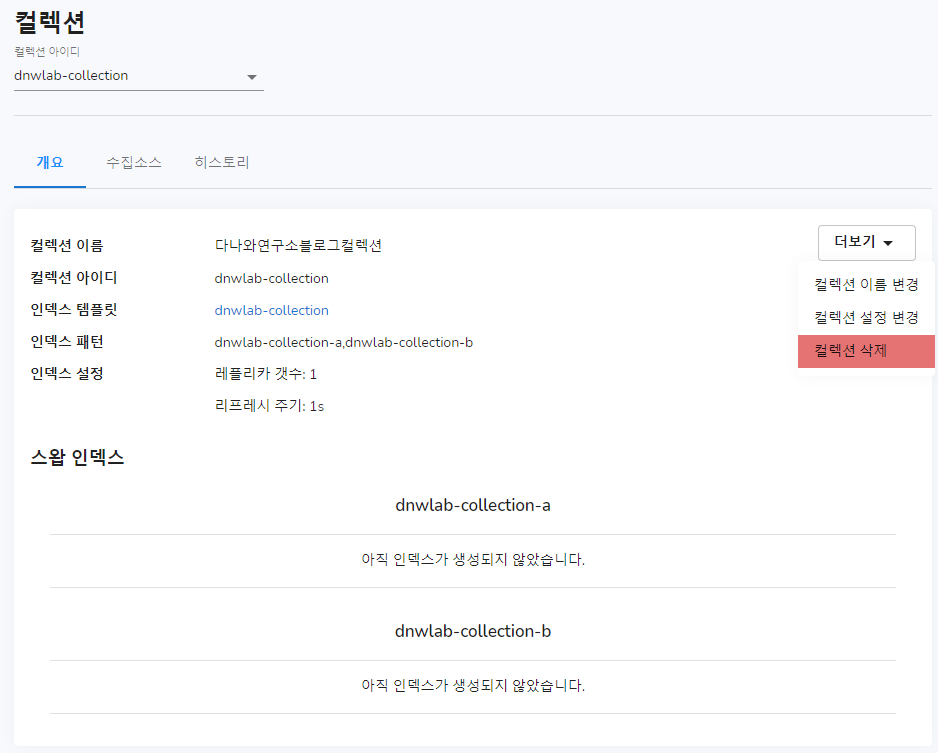
컬렉션 이름 변경 옵션입니다. 이름을 잘못 적었을 때, 이 옵션을 통해 수정할 수 있습니다.

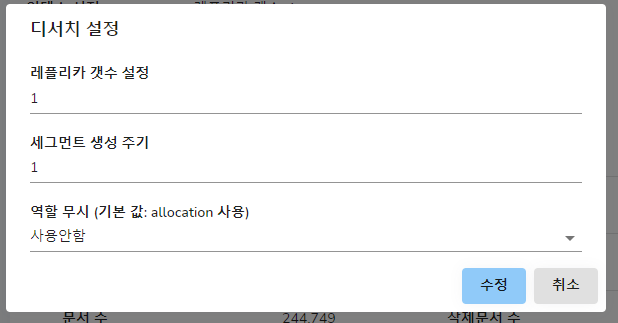
세그먼트 생성주기와 레플리카 갯수 설정 옵션입니다. 각 컬렉션별로 따로 설정할 수 있습니다. 역할무시 기능은 색인을 진행하는 노드를 제한을 무시하도록 합니다. 기본적으로 활성화 상태이며, 역할무시 사용으로 설정 시 노드에 제한된 색인을 하지 않습니다.
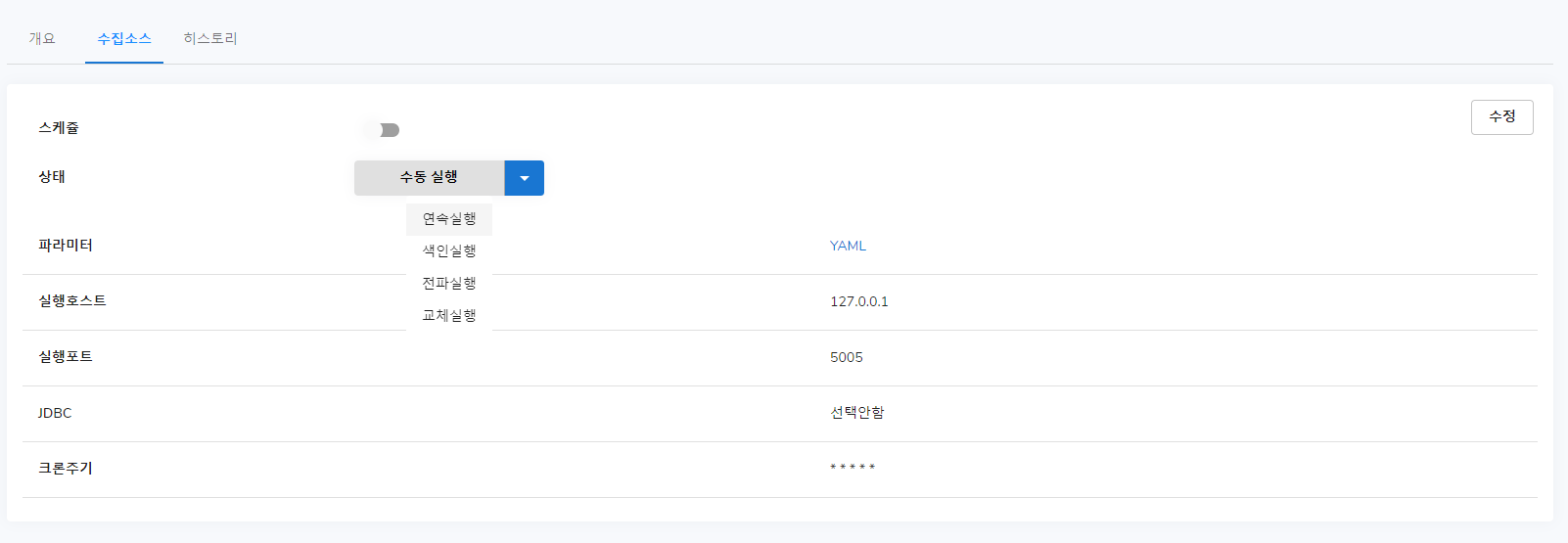
수집소스
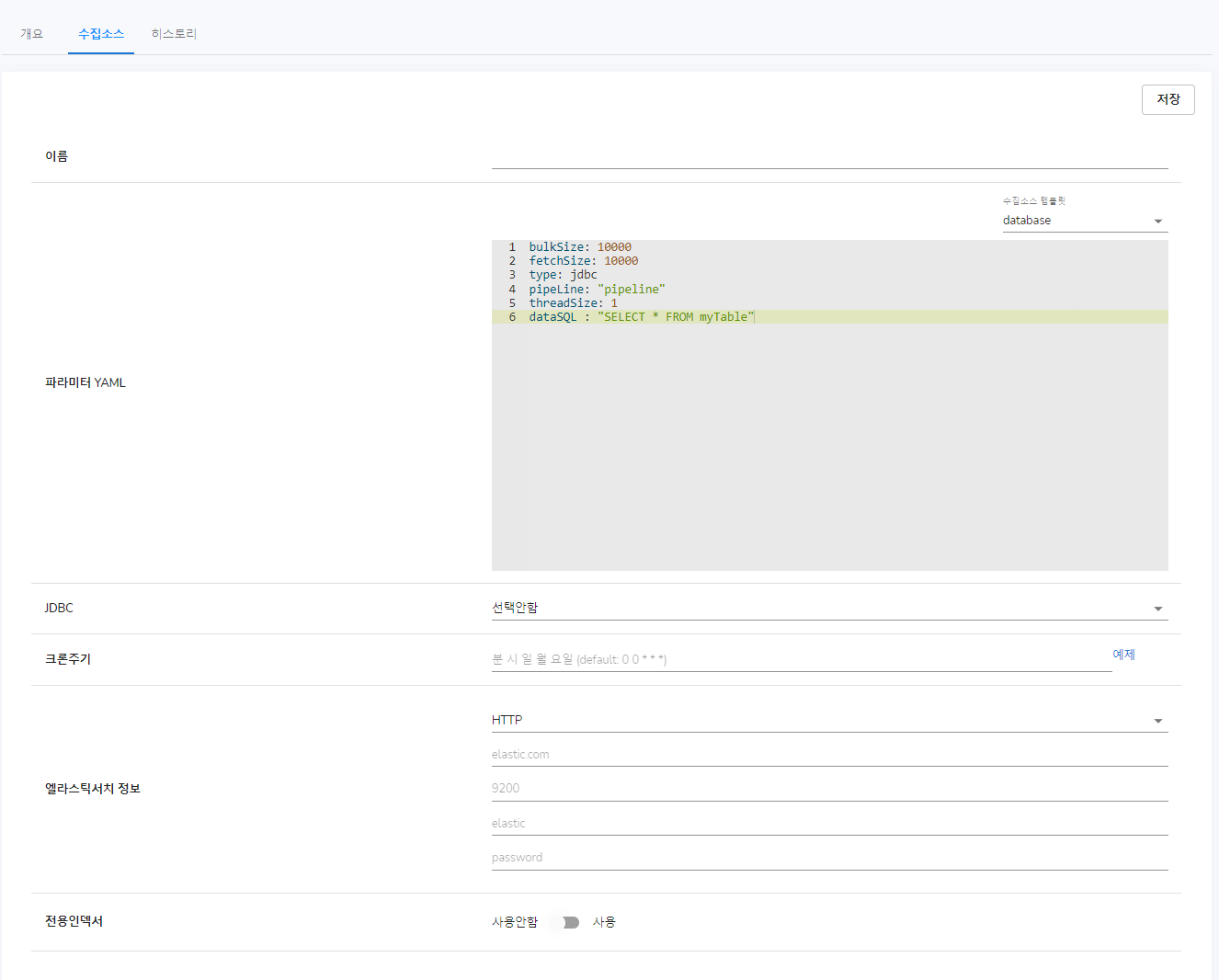
데이터베이스나 파일에서 데이터를 가져와 엘라스틱서치 인덱스에 넣을 수 있게 명세하는 곳입니다.
기본적으로 템플릿을 제공은 하고 있습니다. 각 필드의 자세한 설정은 아래 링크를 통해 확인바랍니다.
이름은 이 컬렉션에서 테스트를 진행할 수집소스 정보 이름에 대해 적어주시면 됩니다.
JDBC는 데이터베이스에서 데이터를 수집해 올 때, 필요한 데이터 (데이터베이스 테이블이름, 아이디, 비밀번호 등)을 미리 JDBC 메뉴에서 등록해 둔 내용을 선택하여 그 내용을 기반으로 데이터를 가져오게 할 수 있습니다.
인덱스를 생성할 엘라스틱서치의 정보를 입력합니다. 기본값으로 등록되어 있는 엘라스틱서치의 정보가 사용됩니다. 하지만 전용인덱서를 사용하는 경우 필수로 입력하여야합니다. 전용인덱서가 엘라스틱서치로 요청보내는 정보로 사용됩니다.
전용인덱서를 사용할 경우 전용인덱서의 정보를 입력합니다.
크론주기는 스케줄을 위해 입력하는 곳입니다. 데이터베이스나 파일을 스케줄 형식으로 가져올 수 있게 입력해 주시면 저장이 된 후 스케줄 옵션을 On 해줄 수 있습니다. 다만 입력해주시지 않으면 저장이 되지 않기 때문에 크론주기를 꼭 입력해 주셔야 합니다. 크론주기에 익숙하시지 않은 분을 위해 예제를 제공하고 있습니다.

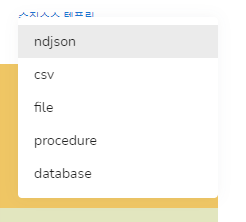
템플릿 리스트 입니다. 기본적으로 아무런 내용이 없을 때, ndjson 템플릿이 선택됩니다.
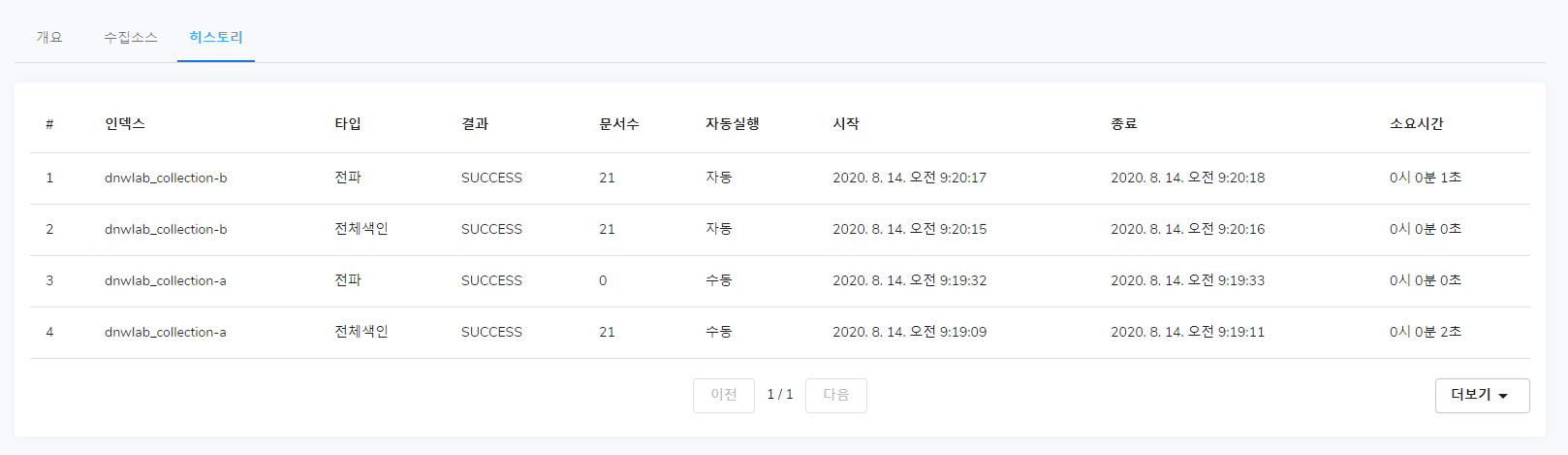
히스토리
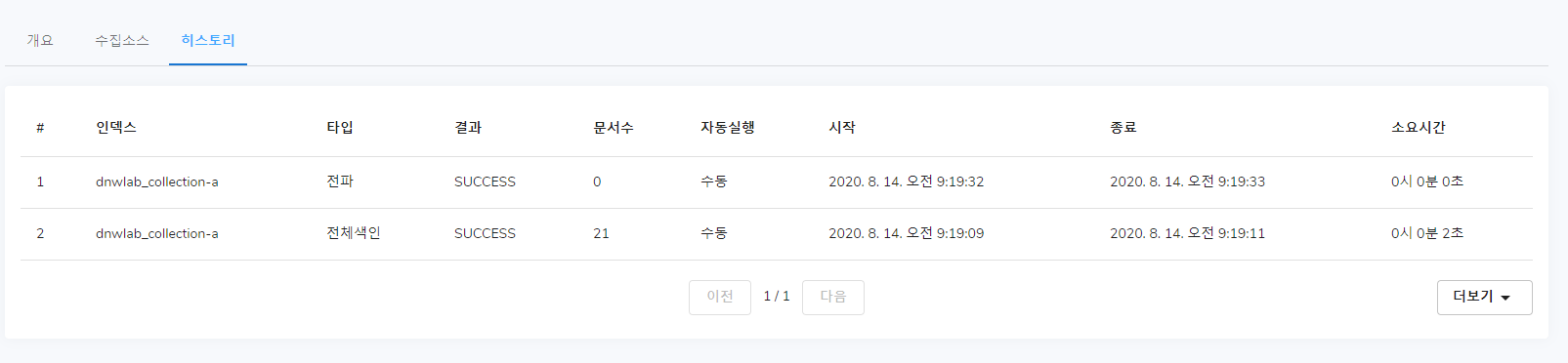
수집소스를 등록하여 진행된 결과에 대해 볼 수 있습니다. 색인과 전파 명령에 대하여 결과를 기록합니다.

전체 또는 기간단위로 삭제 기능을 통해 불필요한 데이터를 줄일 수 있습니다.

CSV 데이터 색인 예제
CSV로 저장된 데이터를 가져오는 방법을 보여드리겠습니다. 버전에 따라 UI 가 일부 상이 할 수 있습니다.
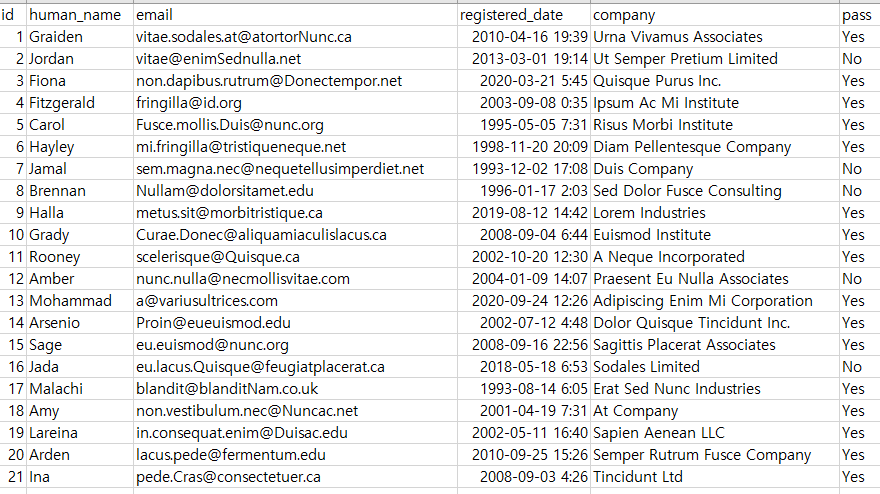
아래의 이미지와 같이 저장된 CSV 파일이 있습니다.
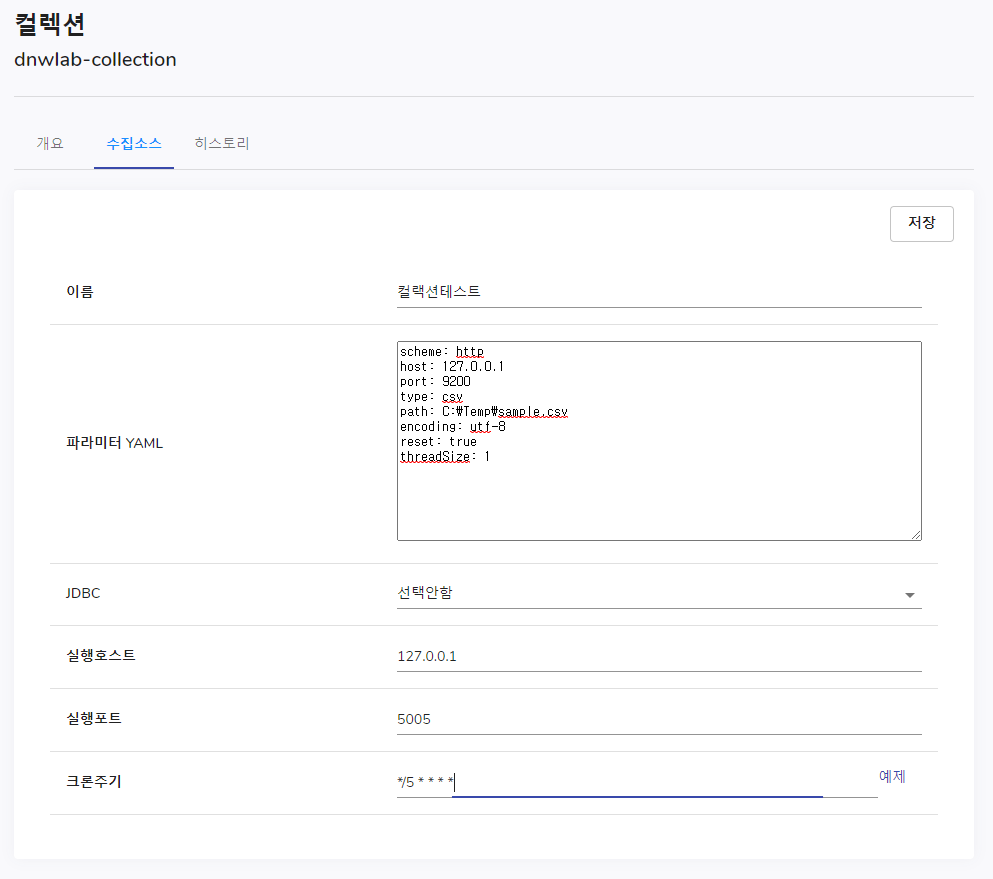
이를 수집소스를 통해 아래의 이미지와 같이 입력하고 저장을 눌러줍니다.
그리고 상태 버튼을 눌러 색인실행을 클릭해 주시면 진행되는 것을 볼 수 있고, 수집이 진행되고 성공하는지, 실패하는지를 옆 히스토리 탭에서 볼 수 있습니다.
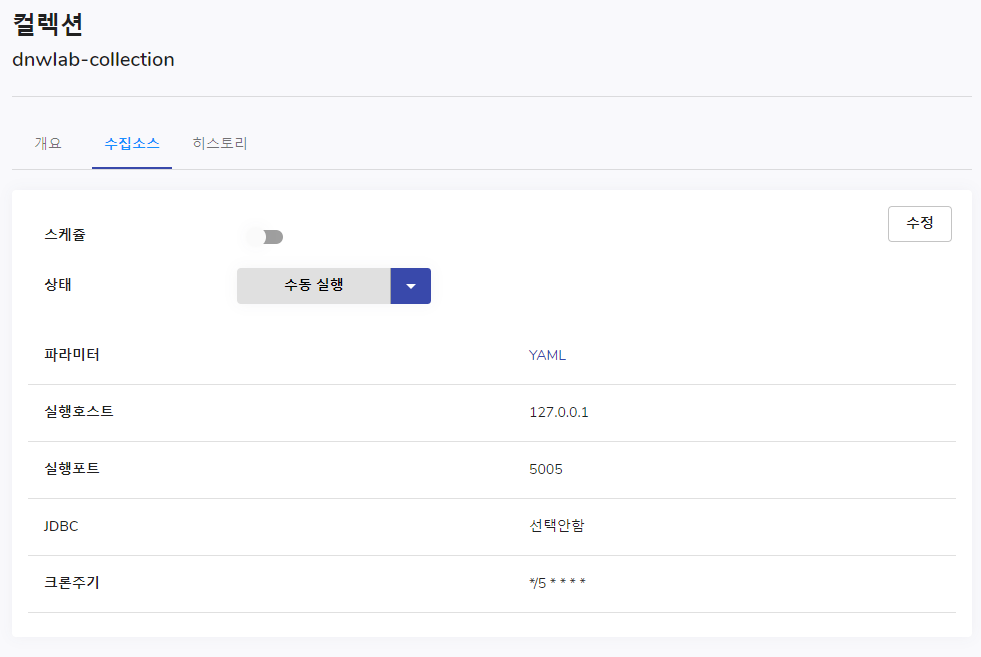

그리고 다시 수집소스로 되돌아와 전파 실행을 클릭해주시면 다른 레플리카로 전파가 되며, 교체 실행을 눌러주시면 곧바로 컬렉션 아이디로 지정해 둔 네이밍으로 사용이 가능하게 됩니다.
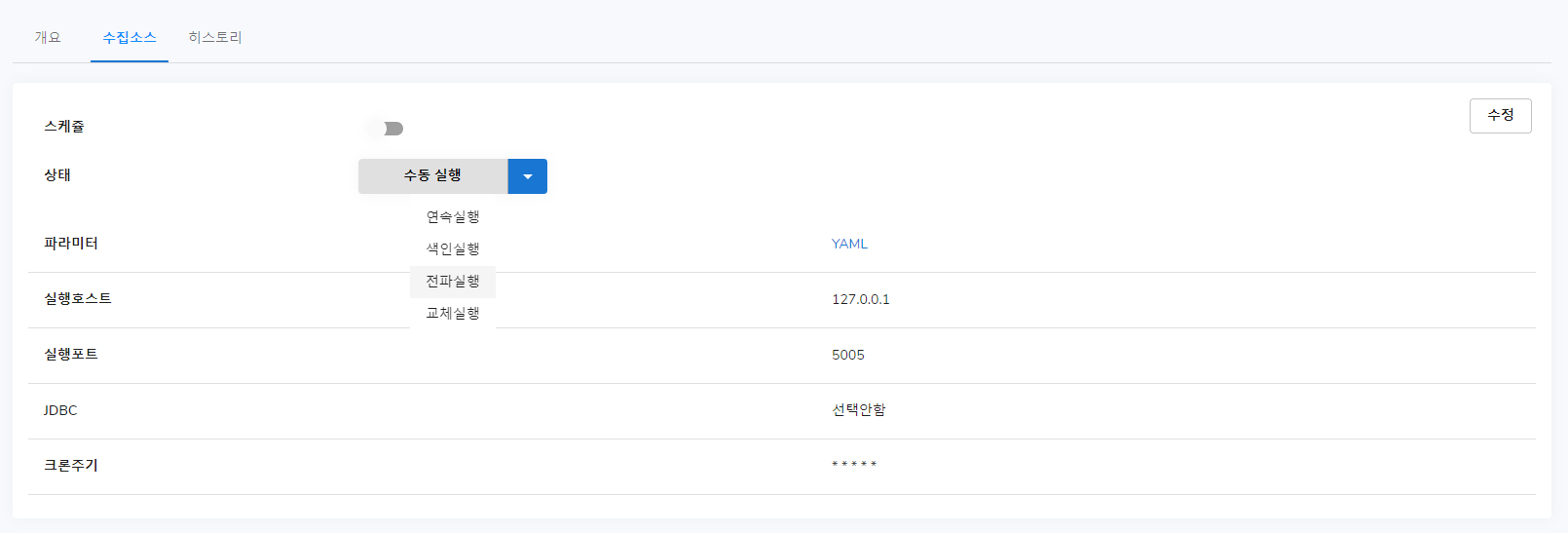
이를 한번에 끝내고 싶으시다면 연속실행 버튼을 클릭해 주시면 됩니다.
이후 히스토리 탭으로 들어가 제대로 실행이 되었는지 여부를 알 수 있습니다.
DB 데이터 가져오기
DB에 저장된 데이터를 가져오는 방법을 보여드리겠습니다.
여기서 진행된 내용은 전부 로컬에서 진행된 내용이고, CSV에서 진행했던 히스토리는 삭제했습니다.
먼저, 데이터베이스를 Docker를 통해 하나 생성합니다.
저는 root 계정에 비밀번호는 ‘ekskdhk’ 데이터베이스는 ‘test’를 사용할 예정입니다.
$ docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=ekskdhk -e MYSQL_DATABASE=test -d mysql:latest
그리고 데이터를 데이터베이스에 테이블을 생성하여 넣어 줍니다. 저는 여기서 간단하게 랜덤데이터를 생성하여 넣었습니다.
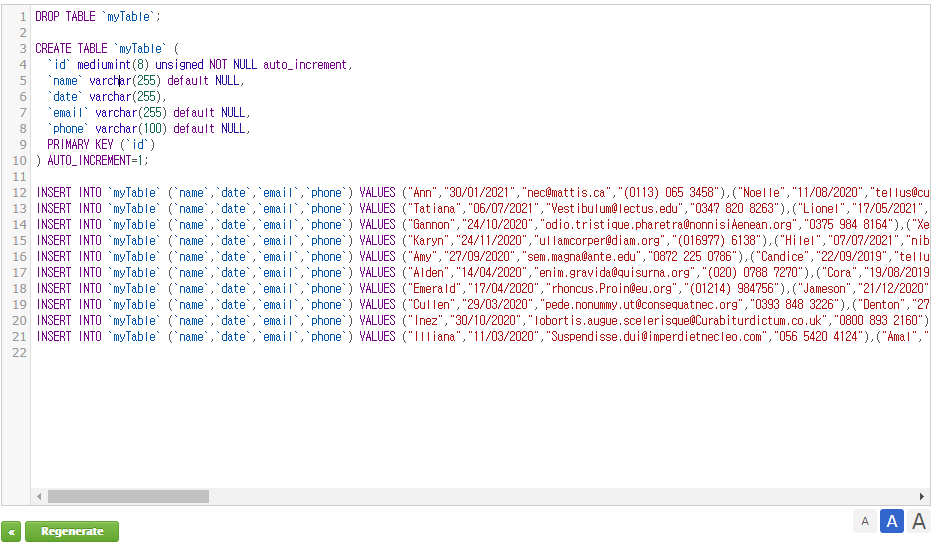
그리고 수집소스 탭으로 이동하여 이렇게 입력해 주었습니다.
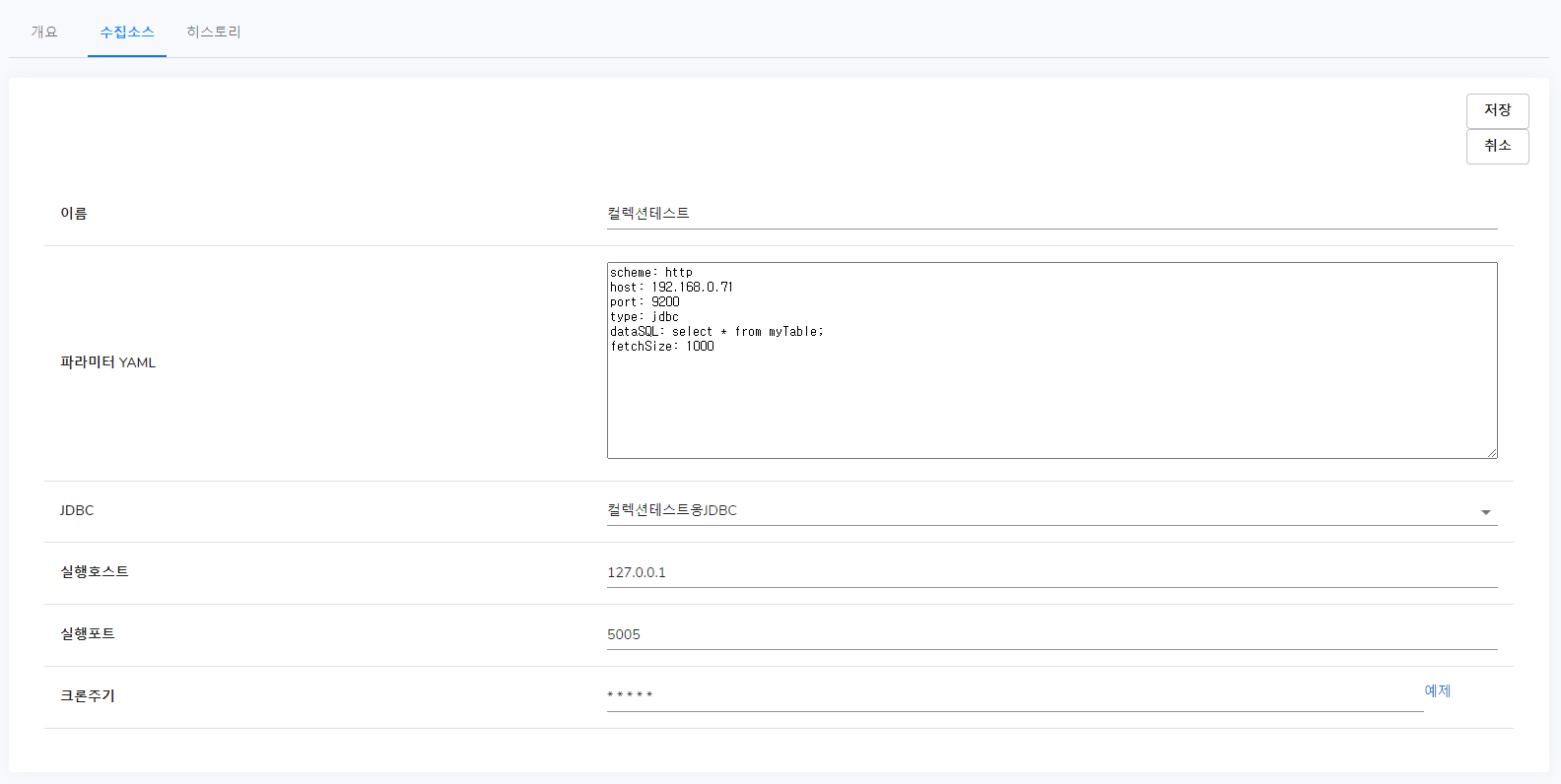
JDBC에 대해서는 추후 자세히 설명할 기회가 있으므로 간략히 이미지로 셋팅이 어떻게 되어있는지만 보여드리겠습니다.

데이터를 정확하게 입력해 주셨다면, 위에서 진행했던 CSV 데이터 가져오기와 마찬가지로 연속실행이나 색인실행-전파실행-교체실행 버튼을 눌러줍니다. 이후 히스토리 탭으로 들어가 제대로 실행이 되었는지 여부를 알 수 있습니다.
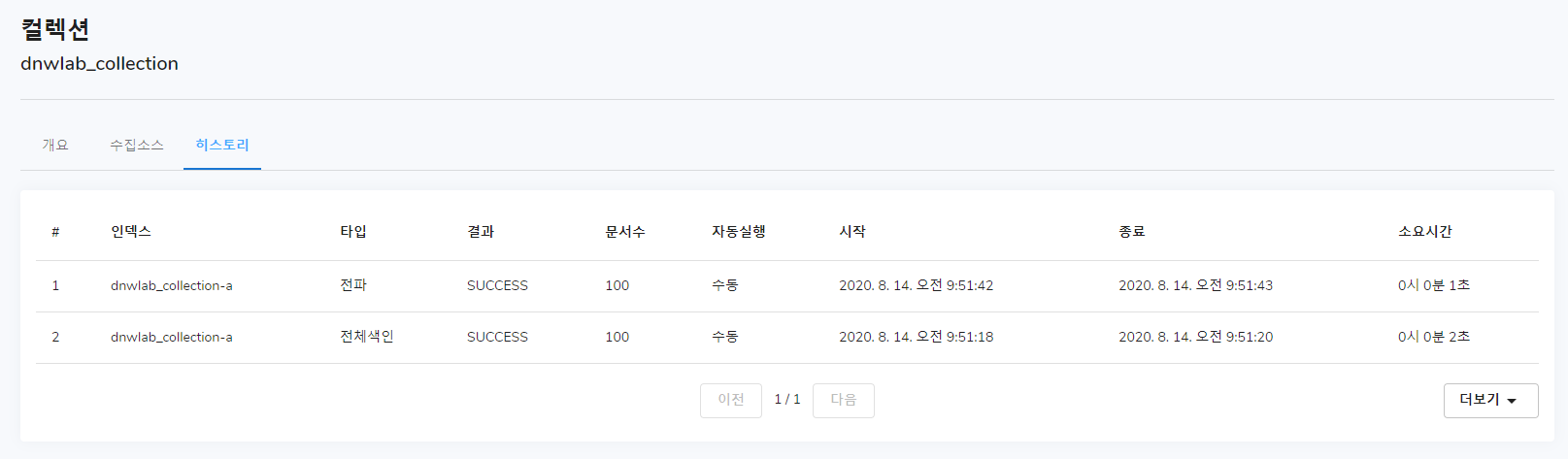
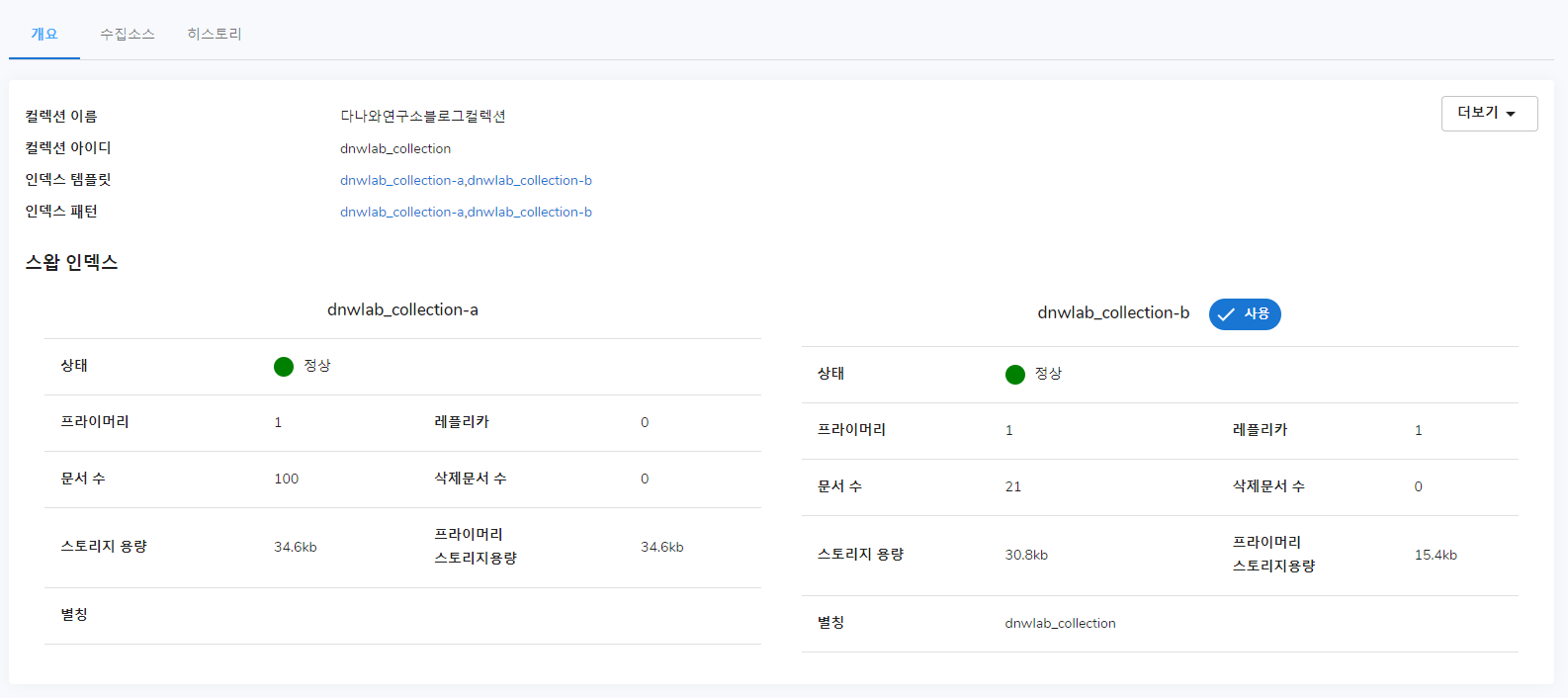
정리
이번에는 다나와에서 개발한 디서치 관리도구-컬렉션 메뉴에 대해 알아 보았습니다. 다양한 환경을 고려하여 사용가능하였고, 두 인덱스를 교차하여 사용하게 되면 검색과 색인을 분리하여 성능에 영향이 안되는 모습을 확인하였습니다.
디서치를 한번도 안 써본 개발자의 입장이 되어 최대한 자세하게 작성해 보았습니다.
이 포스팅이 나중에 사용하시는 분들께 많은 도움이 되었으면 좋겠습니다.