디서치 관리도구 사용법 #2 - 사전
소개
이번 포스팅 내용은 다나와에서 개발한 디서치 관리도구(이하 관리도구)에서 사전 메뉴에 대해 소개하는 시간을 가지도록 하겠습니다. 관리도구에서는 기본적으로 사용자 사전을 지원합니다. 동적으로 사전 구조를 셍상힐 수 있고, 생성된 사전에 단어를 추가하여 색인 또는 검색에 활용할 수 있습니다.
사전 메뉴 사용법
처음 화면
메뉴를 선택하게 되면 처음나오는 화면 입니다. 처음에는 탭으로 검색, 개요, 등록된 사전 들이 탭으로 나열되게 됩니다.
사전 설정 화면
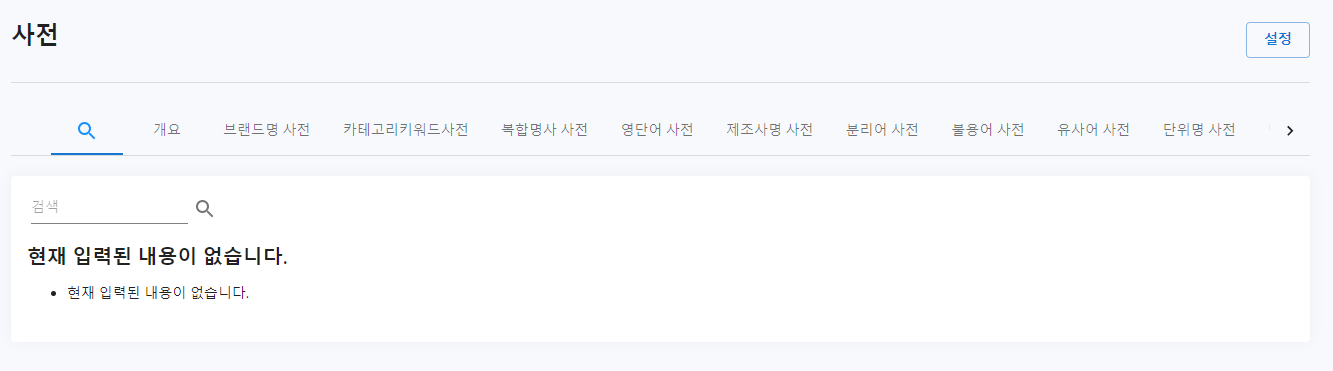
설정 버튼을 클릭하게 되면 사전구조를 관리하는 설정화면으로 전환 됩니다.
사전 추가
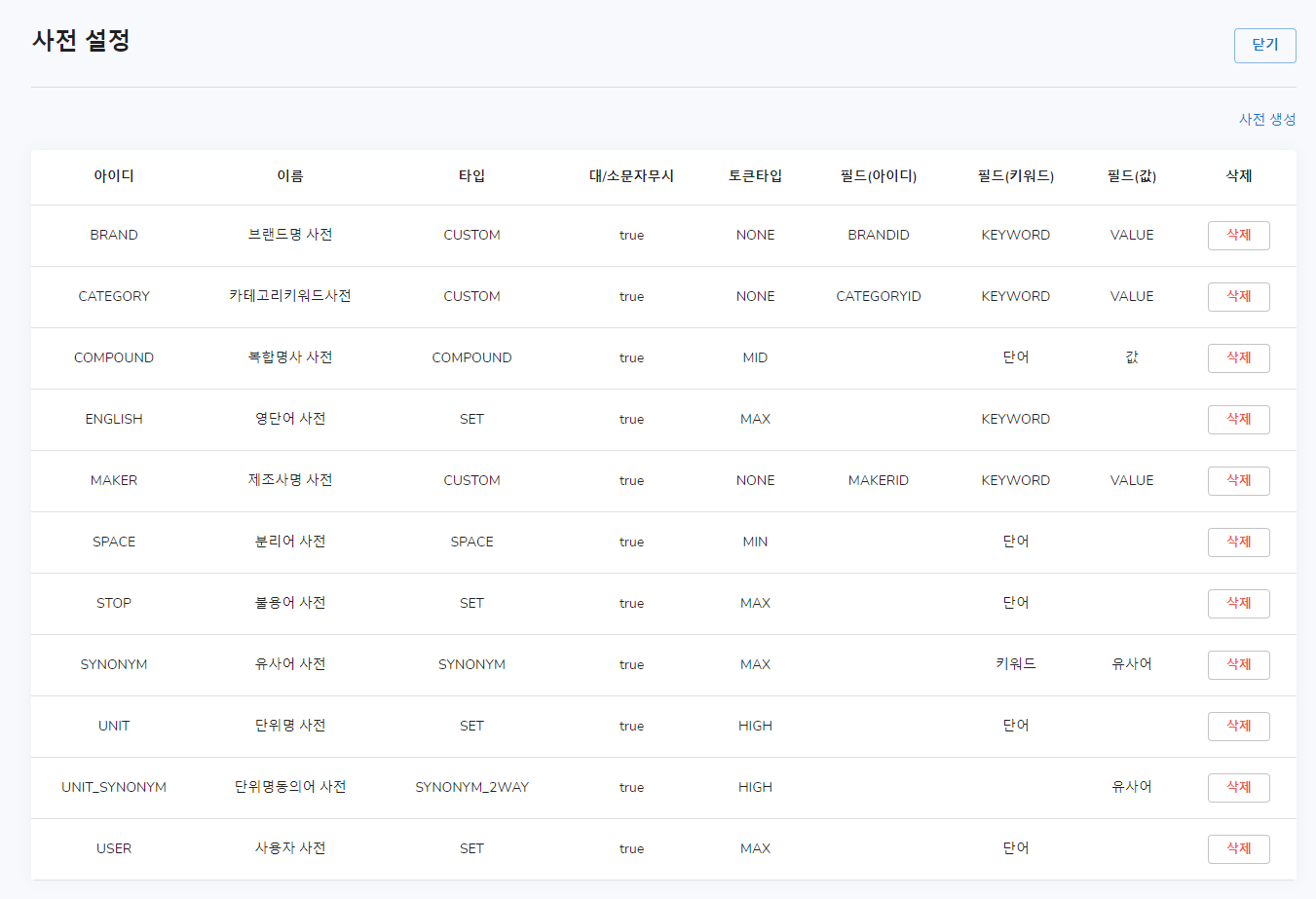
사전 설정화면에서 사전추가버튼을 클릭하면 아래 이미지처럼 모달이 표시됩니다.
아이디: 프로그램 내부적으로 사용하는 아이디입니다.
이름: 사전탭에 표시되는 이름입니다.
타입: 사전 데이터의 구조입니다.(선택에 따라 필드가 변경됩니다)
토큰타입: 형태소 분석에 사용하는 타입 값입니다.
대/소문자 무시: 대/소문자를 무시할지 선택합니다.
검색
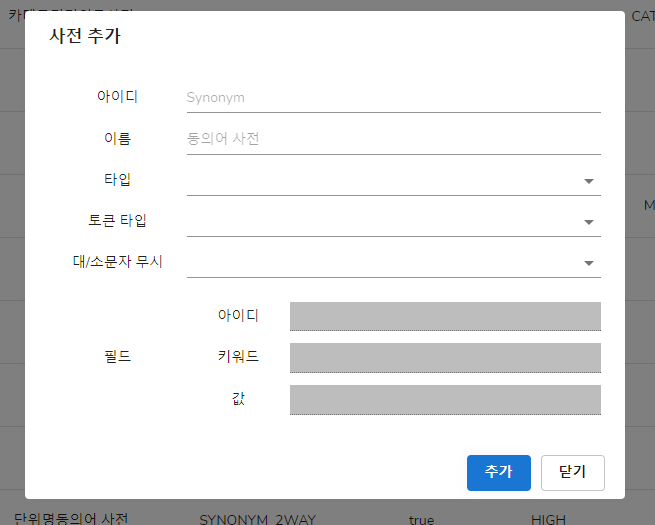
검색을 하게 되면 아래와 같이 값이 나오게 됩니다.
단어의 형태소 분석결과 : 값
각 사전 이름 : 검색된 결과
개요 탭
개요 탭에서는 각 사전에 대한 작업 단어 갯수 및 적용된 단어 갯수, 토큰 타입 등등을 한눈에 볼 수 있습니다.
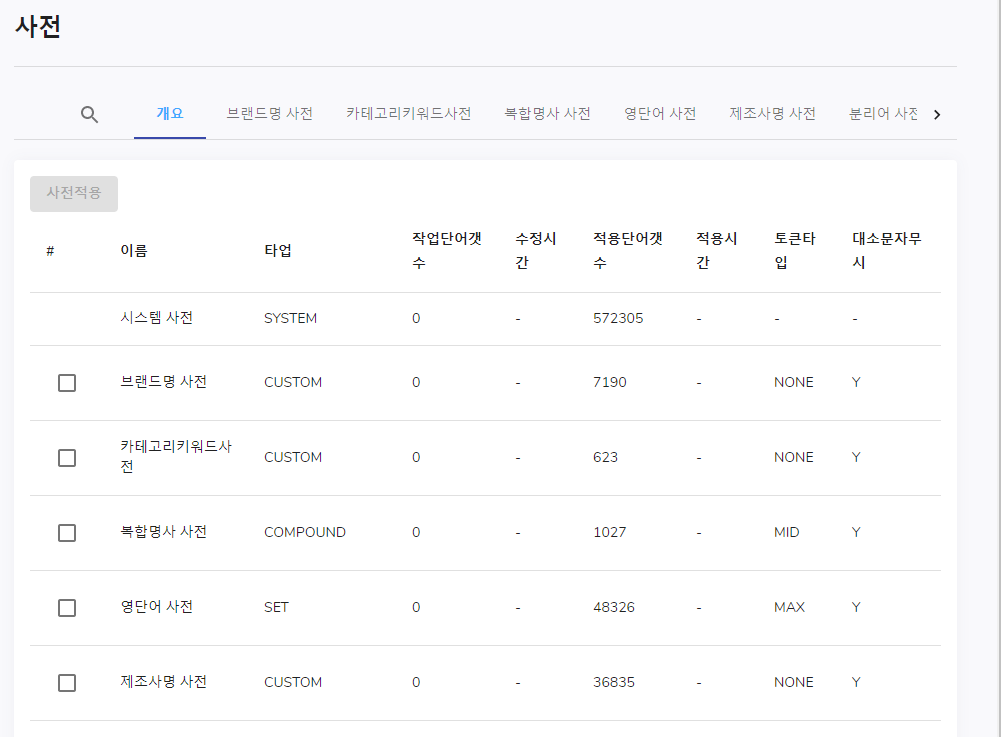
사전에 적용하기 위해서는 왼쪽의 체크버튼을 클릭하고 사전적용 버튼을 클릭합니다 (체크버튼이 체크되지 않는다면 버튼이 활성화 되지 않습니다)
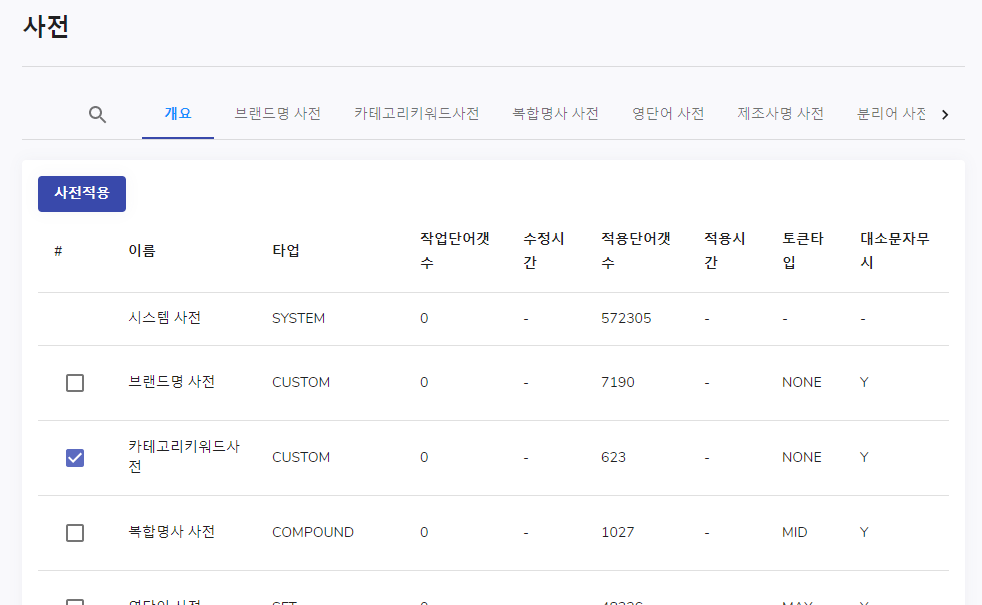
수정사항이 있다면 아래와 같이 적용 시간과 적용 단어 갯수가 변경되게 됩니다.
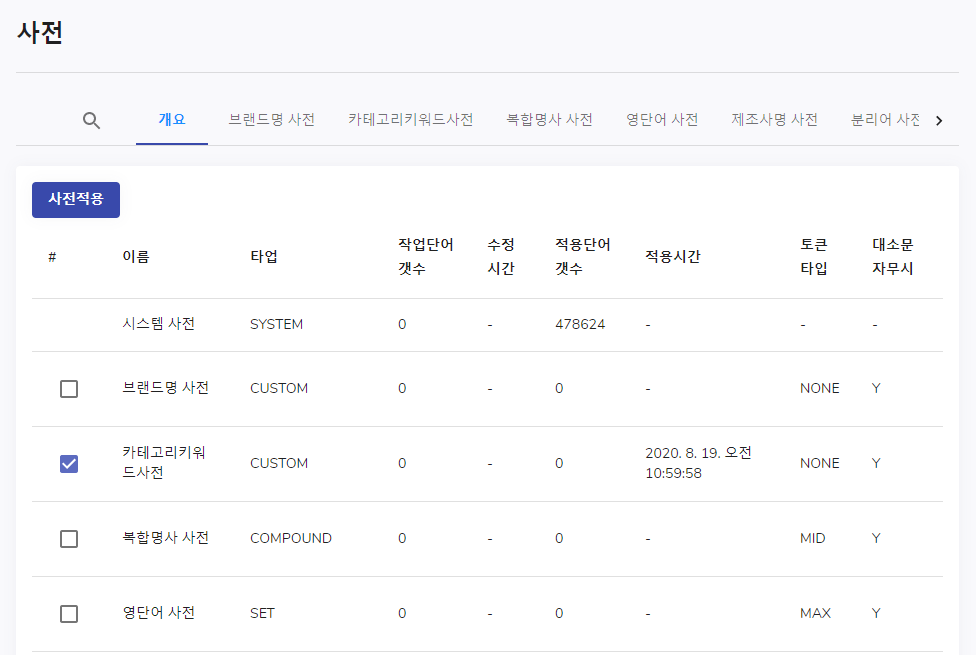
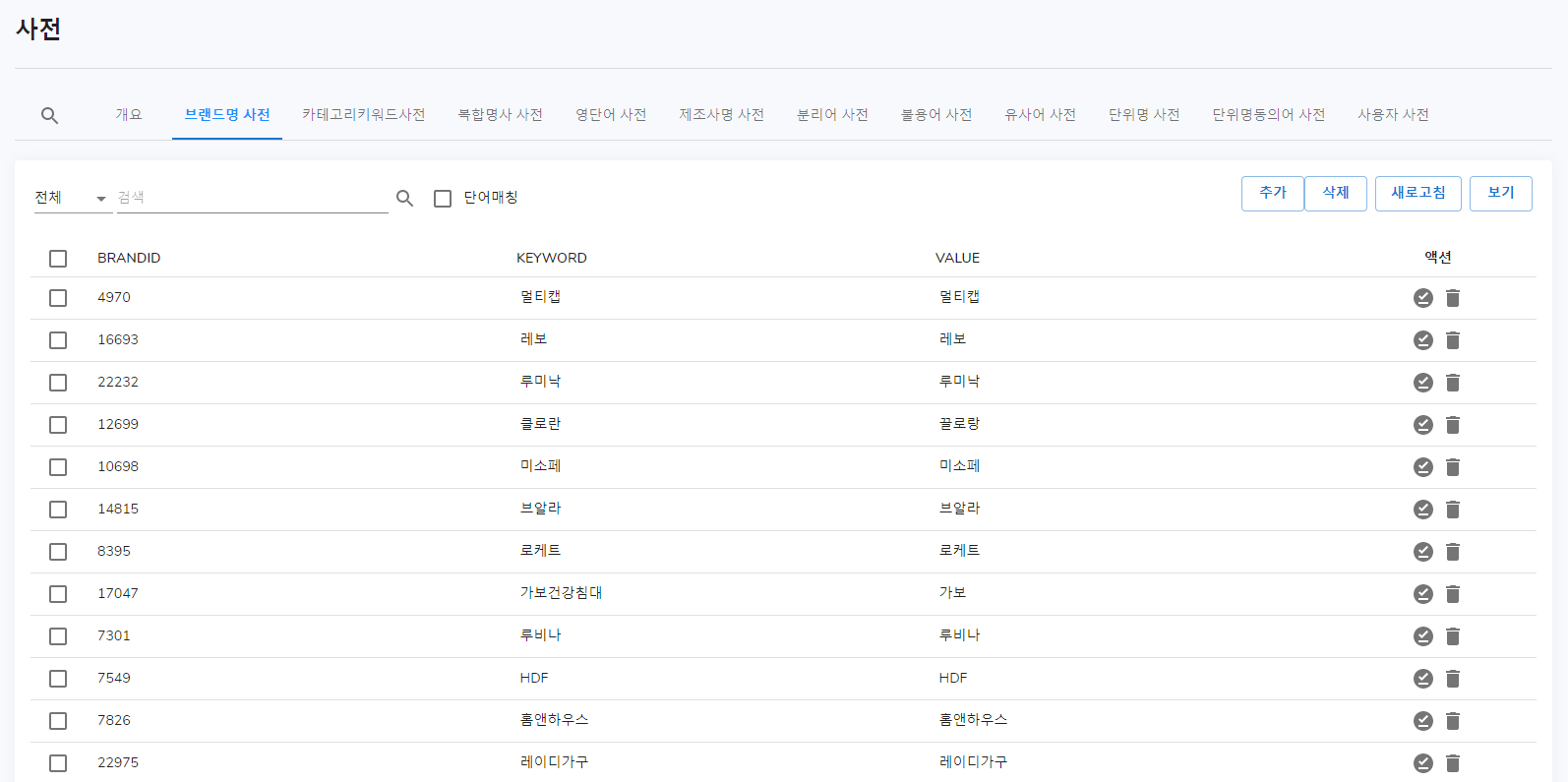
각 사전 탭
사전 탭 UI
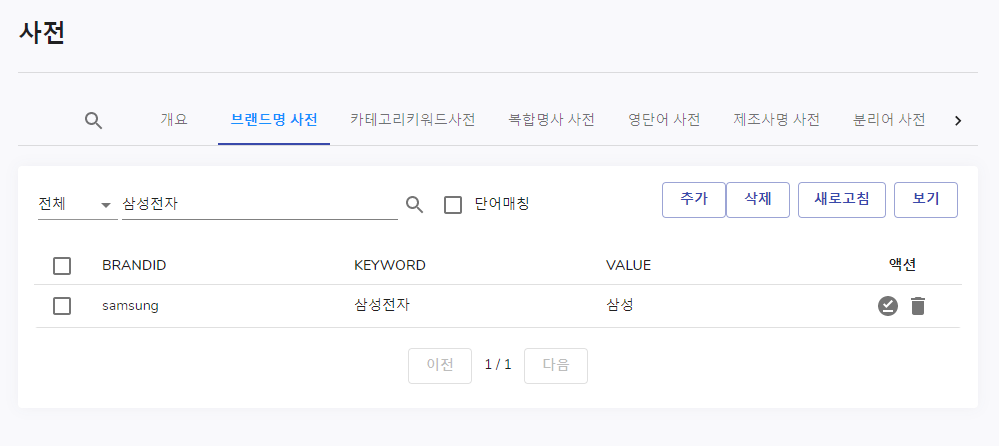
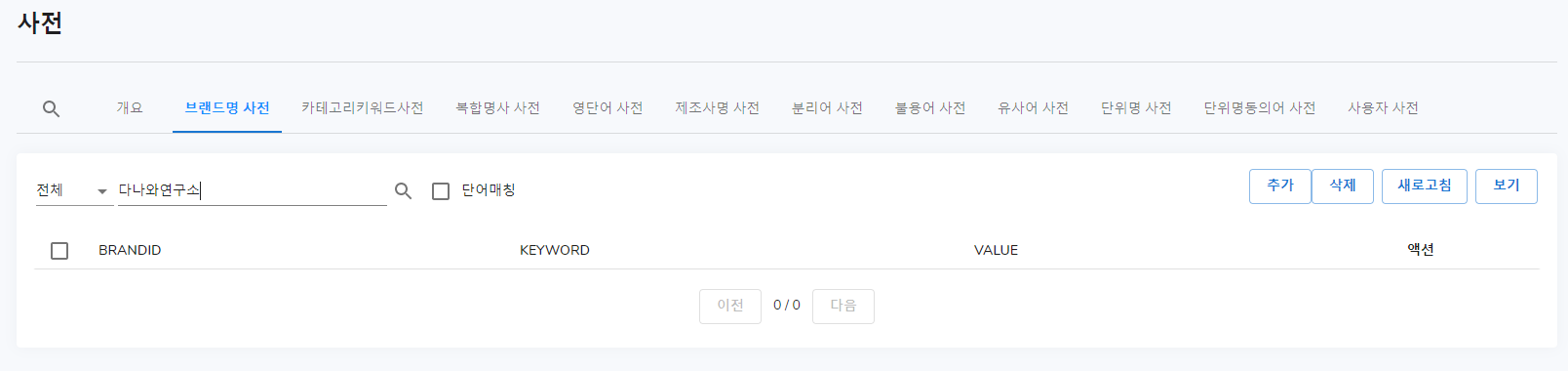
단어매칭
클릭 전
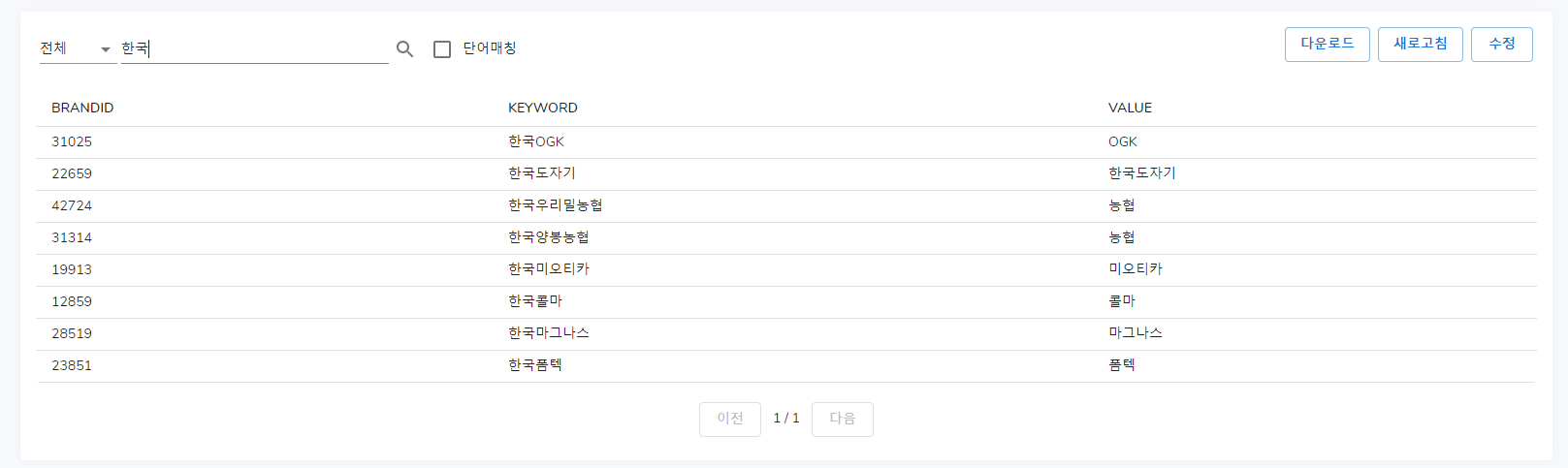
단어 매칭 기준이 되는 단어가 똑같을 때 찾아집니다.


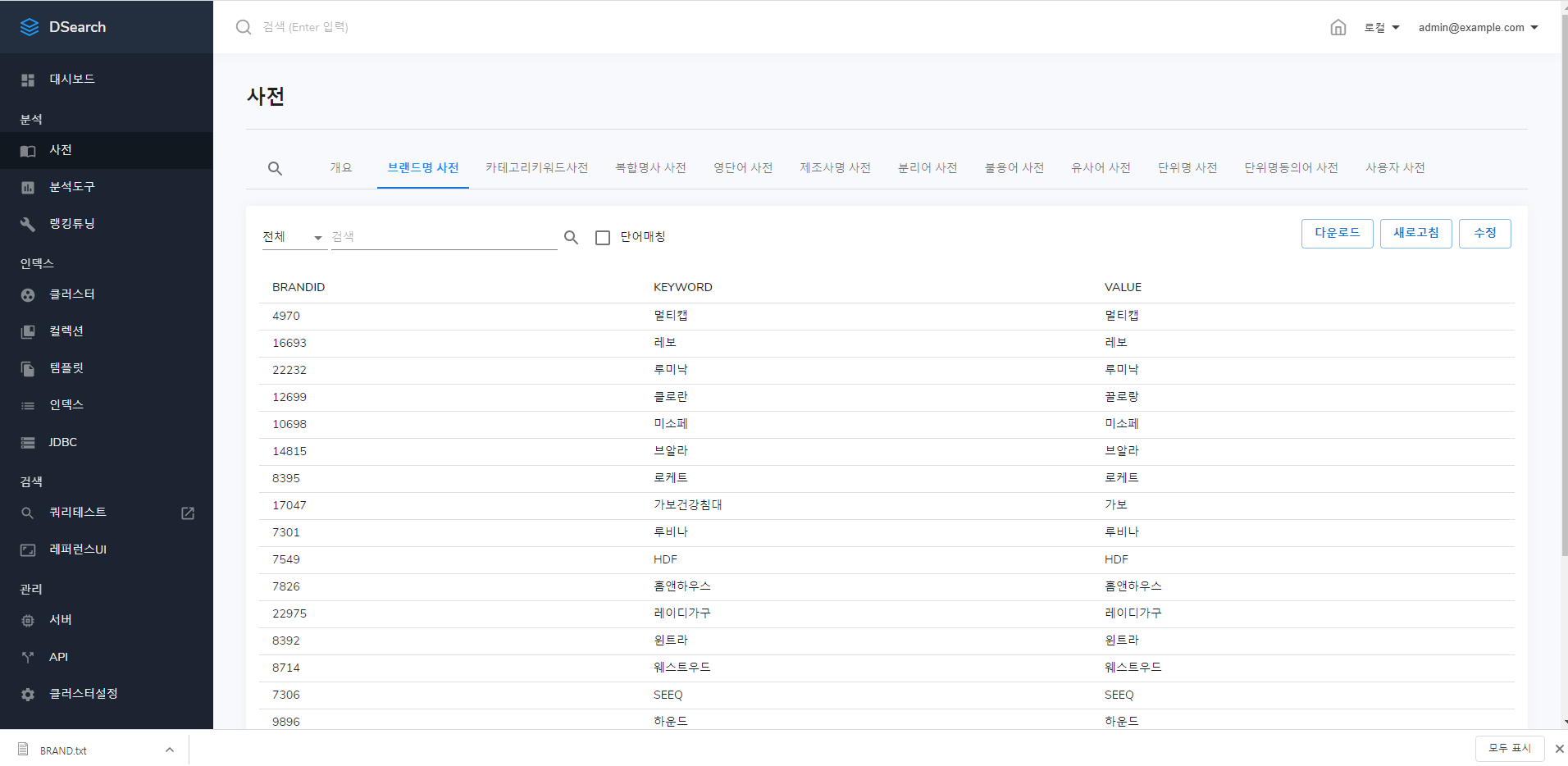
다운로드
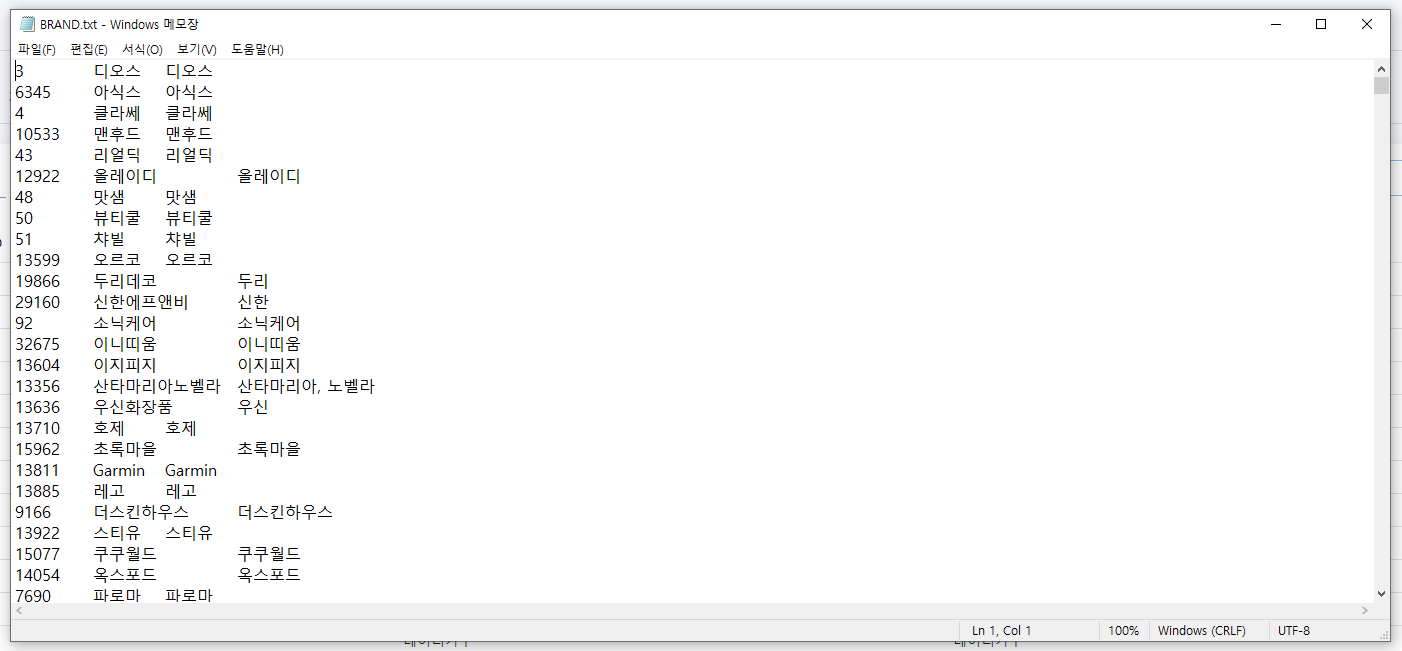
다운로드를 클릭하게 되면 사전을 텍스트 파일로 다운 받을 수 있게 됩니다.
수정 클릭 시 변화
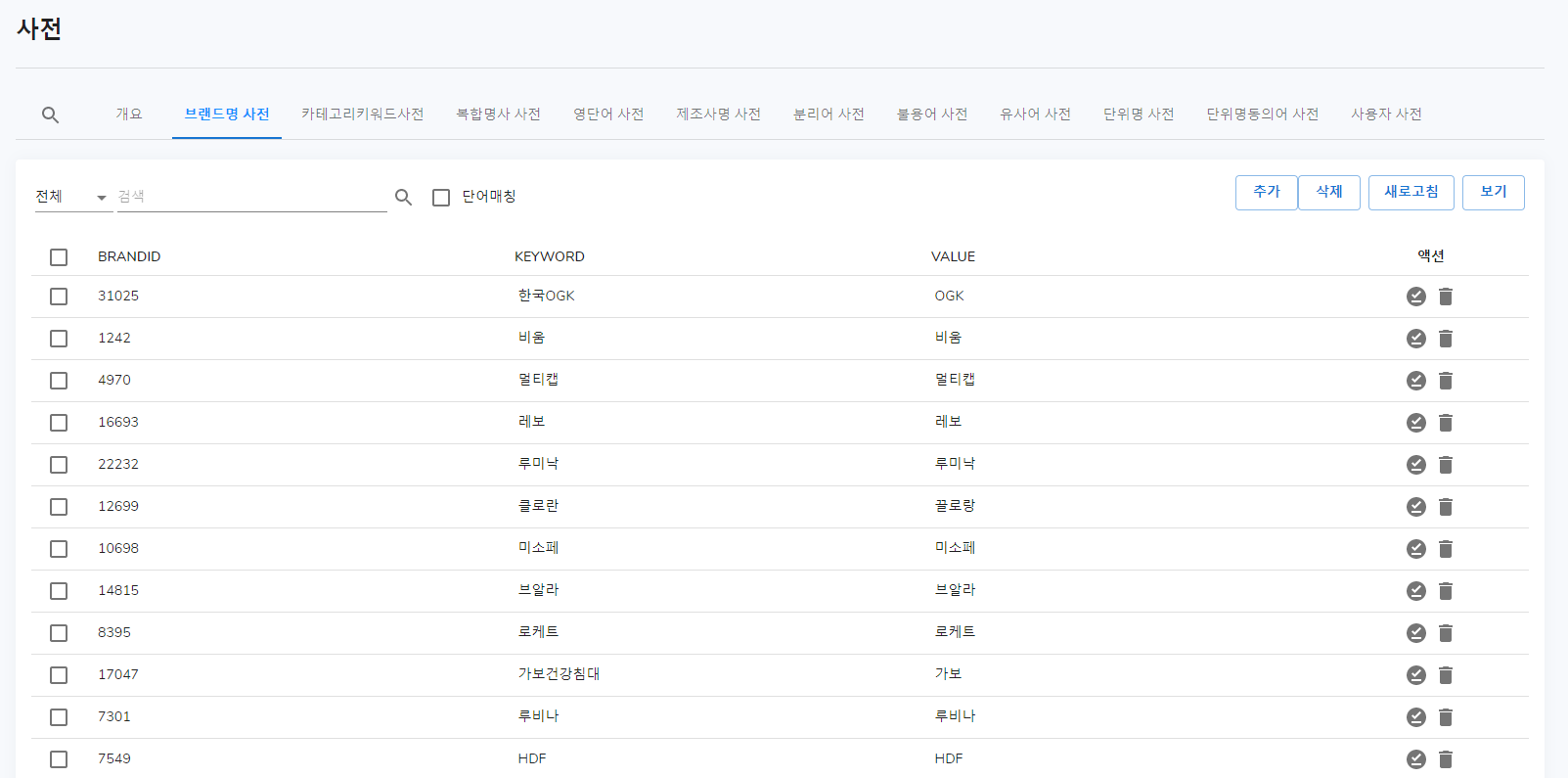
이렇게 직접 수정 가능합니다.

추가 버튼 클릭시
데이터를 새로 등록할 수 있습니다.


삭제 버튼 클릭시 (왼쪽의 체크박스 체크 필요)
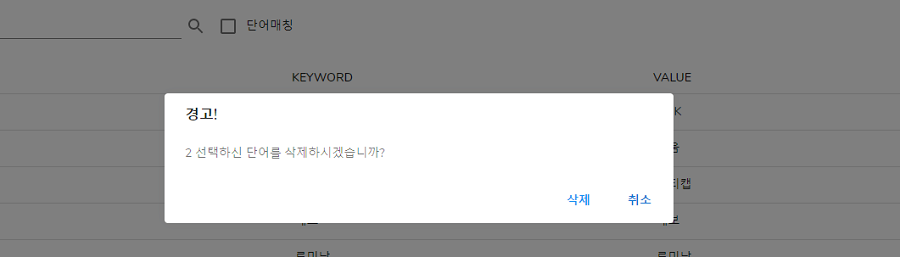
삭제 된 이후
정리
이번에는 다나와에서 개발한 관리도구-사전 메뉴에 대해 설명하고, 사용하는 방법에 대하여 포스팅 해보았습니다. 사전의 구조를 생성하고, 생성된 사전에 데이터를 입력하였습니다. 실제 분석에는 인덱스의 analyzer에는 영향이 없지만 전용인덱서 또는 엘라스틱서치의 플러그인 등에서 사용할 수 있습니다.
관리도구를 한번도 안 써본 개발자의 입장이 되어 작성해 보았습니다.
이 포스팅이 나중에 사용하시는 분들께 많은 도움이 되었으면 좋겠습니다.