엘라스틱서치 오타교정 API 만들어보기
1. 개요
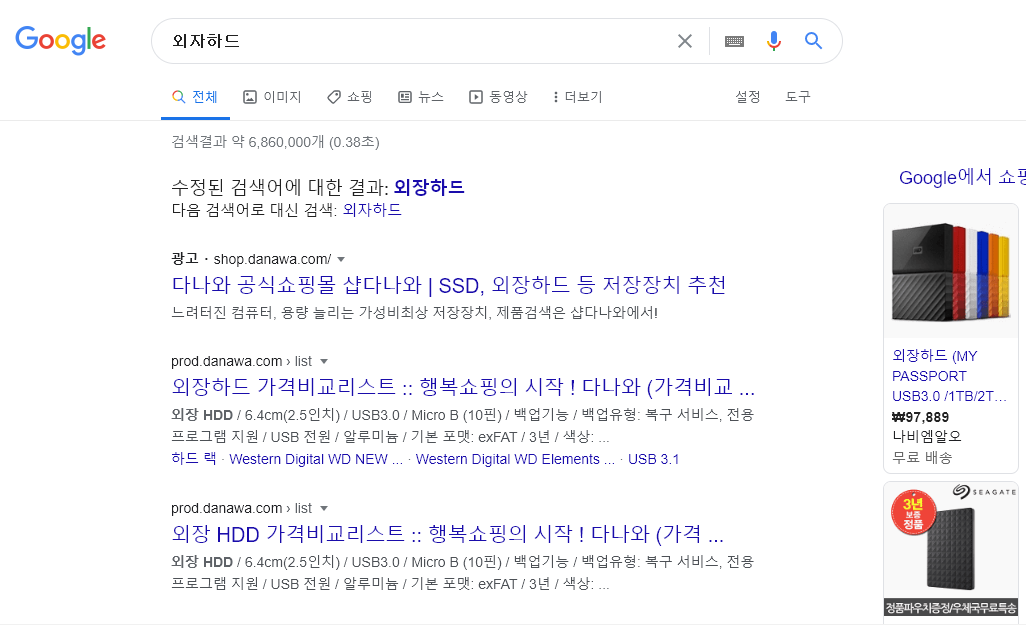
검색을 하다보면 때때로 잘못된 타이핑으로 인해 원하지 않는 키워드로 검색을 할 때가 있습니다. 이럴 때는 원하는 키워드로 다시 검색을 하게 되는데요. 이러한 수고스러움을 덜어주기 위해 이미 여러 사이트에서는 제안검색 개념으로 이를 제공해주고 있습니다. 이번 블로그에서는 엘라스틱서치를 이용하여 오타로 인한 검색을 교정된 키워드로 제공해주는 구성을 만들어보겠습니다.
[오타 교정 검색의 예]
2. 구성 작업
2-1. ICU Analysis Plugin 설치
분석 플러그인으로는 ICU 플러그인을 사용하겠습니다.
sudo bin/elasticsearch-plugin install analysis-icu
더 자세한 내용은 하단 링크를 참조해주세요
2-2. 인덱스 생성
검색된 키워드를 알맞는 키워드로 제공할 수 있도록 교정된 키워드 SET이 필요합니다.
csv형태의 키워드 파일과 키바나에 Machine Learning탭의 Data Visualizer 기능을 사용하여 간단하게 인덱스를 생성해보겠습니다.
-
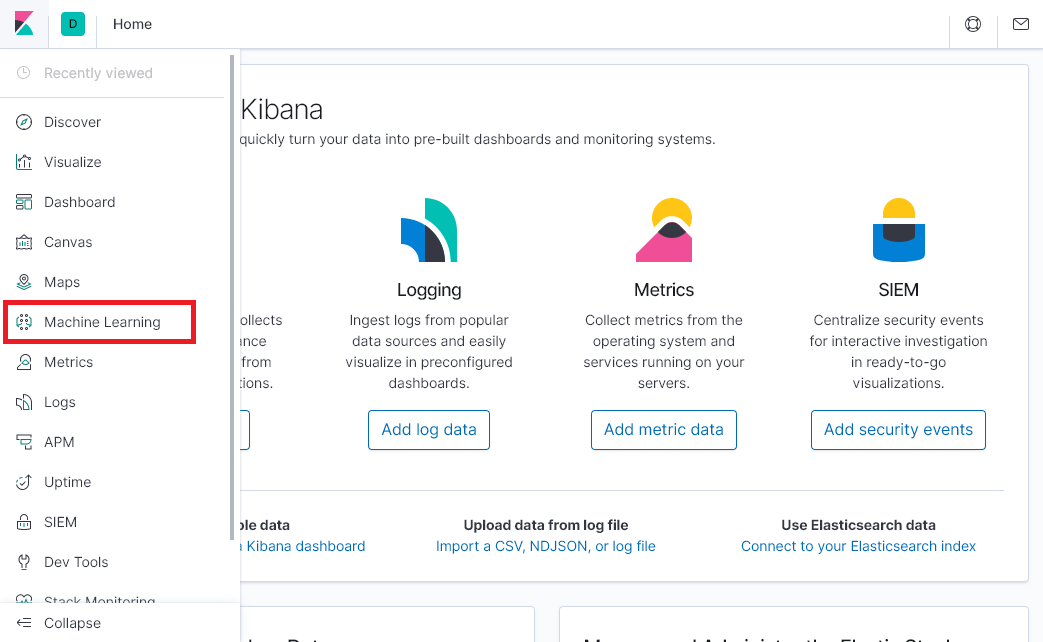
Machine Learning 탭을 선택합니다.
-
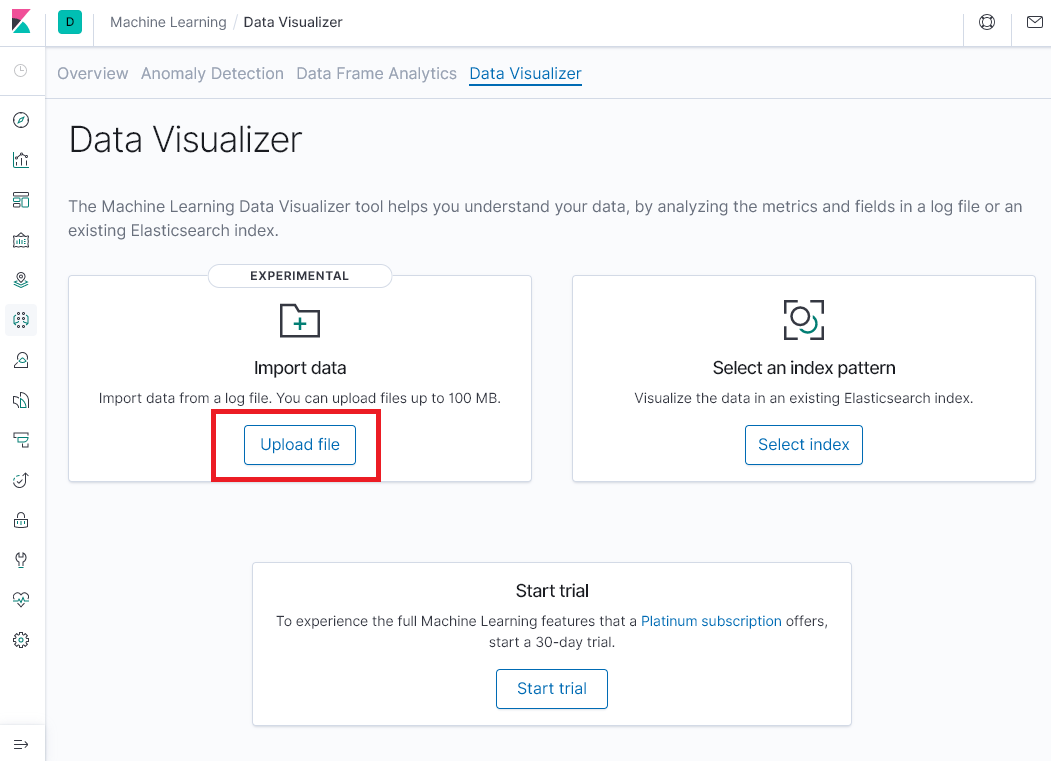
Upload File을 선택합니다.
-
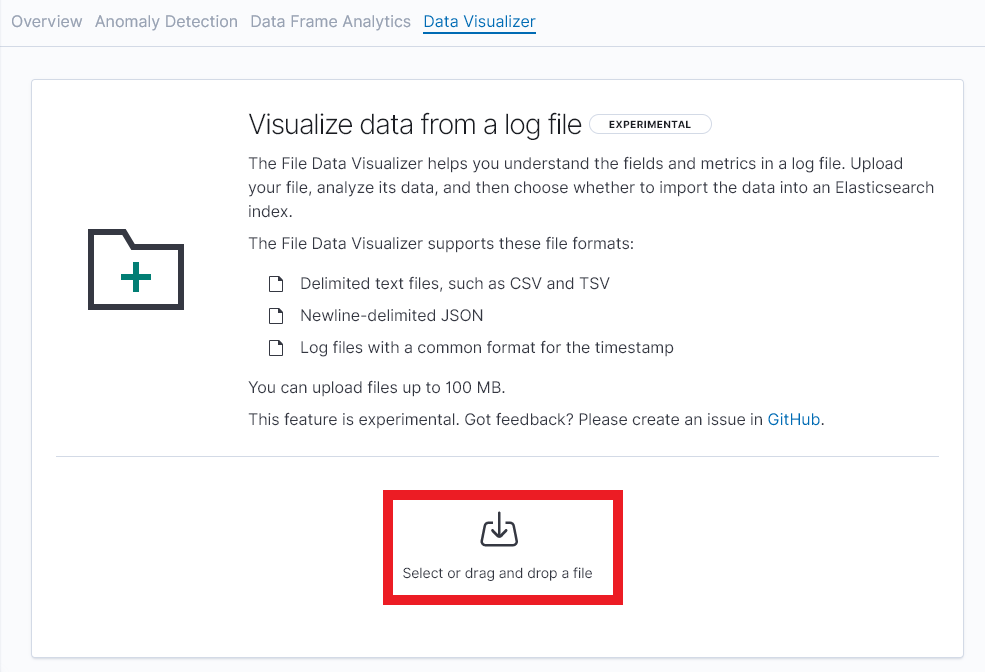
아래 버튼을 눌러 파일을 불러옵니다. 불러오려는 파일은 ‘,’ 로 구분된 CSV 파일을 사용하였습니다.
-
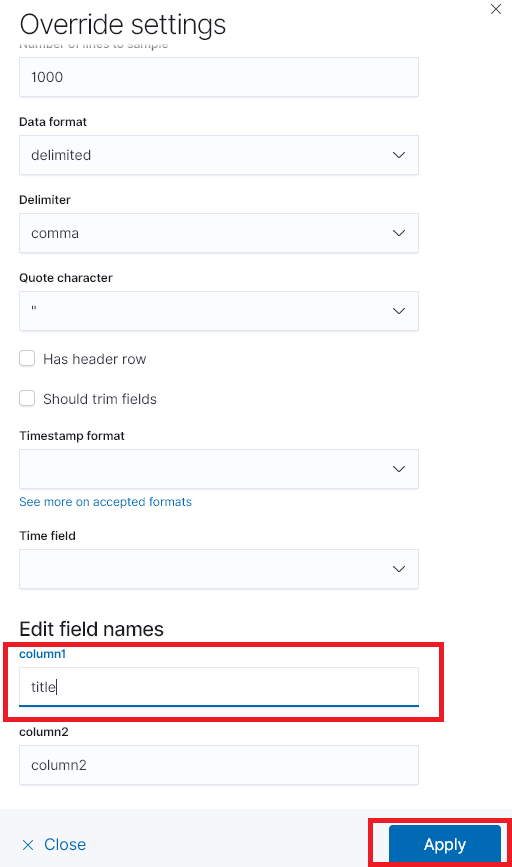
Override setting에서 컬럼명을 정해줍니다.
- 인덱스명, 인덱스 셋팅과 맵핑을 각각 설정합니다.
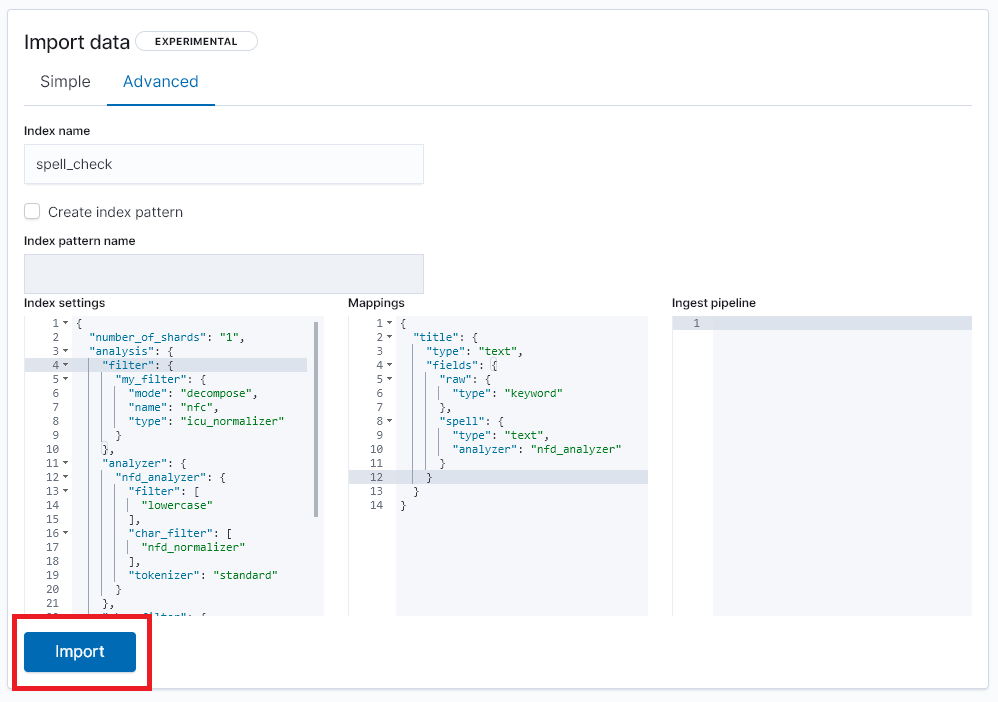
사용한 셋팅 및 맵핑입니다. 분석은 NFD(정준분해) 방식을 사용합니다.
index settings
"settings": {
"index": {
"analysis": {
"filter": {
"my_filter": {
"mode": "decompose",
"name": "nfc",
"type": "icu_normalizer"
}
},
"analyzer": {
"nfd_analyzer": {
"filter": [
"lowercase"
],
"char_filter": [
"nfd_normalizer"
],
"tokenizer": "standard"
}
},
"char_filter": {
"nfd_normalizer": {
"mode": "decompose",
"name": "nfc",
"type": "icu_normalizer"
}
}
}
}
}
인덱스 맵핑 셋팅입니다.
title 컬럼 하위의 fields 셋팅중 spell 필드는 분석기로 ndf_analyzer로 설정합니다. 이 필드는 아래 검색에서 사용됩니다.
index mappings
"mapping": {
"properties": {
"title": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
},
"spell": {
"type": "text",
"analyzer": "nfd_analyzer"
}
}
}
}
}
- 그 후 import를 클릭하시면 인덱스가 생성됩니다.
3. 테스트
인덱스가 생성됬으니 검색을 통해 교정된 키워드를 확인해 보겠습니다. 검색API의 suggesters를 사용하겠습니다.
엘라스틱서치의 suggesters는 아래 링크를 참조해주세요
검색 쿼리 예시입니다.
위에 맵핑에서 분석기를 설정한 title.spell 를 필드로 지정합니다.
POST /spell_check/_search
{
"suggest" : {
"my-suggestion" : {
"text" : "쟈전거",
"term" : {
"field" : "title.spell",
"string_distance" : "jaro_winkler"
}
}
}
}
검색 결과입니다. my-suggestion 하위의 options에서 검색한 키워드의 교정된 결과를 얻을 수 있습니다.
{
"took" : 3,
... 중략
"suggest" : {
"my-suggestion" : [
{
"text" : "쟈전거",
"offset" : 0,
"length" : 3,
"options" : [
{
"text" : "자전거",
"score" : 0.9142858,
"freq" : 1
}
]
}
]
}
}
아래처럼 다수의 결과가 나올 수도 있습니다.
"suggest" : {
"my-suggestion" : [
{
"text" : "신세ㄱ",
"offset" : 0,
"length" : 3,
"options" : [
{
"text" : "신세계",
"score" : 0.9246032,
"freq" : 1
},
{
"text" : "신생",
"score" : 0.86666673,
"freq" : 1
},
{
"text" : "신성",
"score" : 0.86666673,
"freq" : 1
},
{
"text" : "신솔",
"score" : 0.86666673,
"freq" : 1
},
{
"text" : "신신",
"score" : 0.86666673,
"freq" : 1
}
]
}
]
}
3-1. 성능 테스트
결과는 나오는것 같고.. 성능적인 부분도 측정해보고자 jmetter를 사용하여 테스트를 진행해봤습니다. 그럴려면 오타 키워드들이 필요한대요. 기존에 인덱스를 생성할 때 사용한 키워드에서 자음이나 모음을 바꿔서 동일한 수의 오타 키워드 SET을 만들었습니다.
오타 생성에 사용한 PYTHON 코드입니다.
from jamo import h2j, j2hcj, j2h, get_jamo_class
import random
import re
ota_hubo = [
('ㅔ','ㅐ'), ('ㅗ','ㅓ'), ('ㅏ','ㅑ'), ('ㅜ','ㅠ'),
('ㄷ','ㅈ'), ('ㄱ','ㅅ'), ('ㅇ','ㄹ'),('ㅁ','ㄴ'),
('ㅋ','ㅌ'), ('ㅊ','ㅍ')
]
hangul_regex = re.compile('[ㄱ-ㅣ가-힣]')
def _change(jaso):
for hubo in ota_hubo:
# 후보리스트를 돌면서 양방향 변환
# ㅗ -> ㅓ로 변경하거나
# ㅓ -> ㅗ 로 변경한다.
if hubo[0] in jaso:
return jaso.replace(hubo[0], hubo[1]), True
elif hubo[1] in jaso:
return jaso.replace(hubo[1], hubo[0]), True
return jaso, False
def make_ota(word):
value = list(word)
start = random.randint(0, len(value) - 1)
i = start
done = False
# 시작index정하고, 변환.. 끝에서는 0으로 복귀.
# 시작인덱스와 동일하면 루프종료.
while not done:
ch = value[i]
# print('Try >> ', i, ch)
#한글여부확인
is_hangul = len(hangul_regex.findall(ch)) > 0
changed = False
if is_hangul:
# 한글만 변환
jaso = j2hcj(h2j(ch))
jaso2, changed = _change(jaso)
ch2 = j2h(*jaso2)
# print(' > ', ch2, changed)
if changed:
value[i] = ch2
break
else:
i += 1
if i == len(value):
i = 0
if i == start:
# 변환불가. 종료
break
return ''.join(value)
ex)
야이포크
아리폰
아이펀용
야이폴바이오
야이폼
아이퓨드
야이퓨
...
3-2 테스트 결과
오타 키워드들을 가지고 각각 3분동안 호출 했을 때의 결과입니다. 쓰레드 2 기준으로 응답시간이 3ms, TPS는 220/s가 나왔고 쓰레드 수가 점점 증가함에 따라 TPS, CPU 사용 모두 증가하였습니다. TPS의 경우 5->10개 이후로는 증가폭이 높진 않았습니다. 서버 성능에 따라 알맞는 수치를 정해야 할 것 같습니다.
| 쓰레드 수 | 호출 수 | 평균 응답시간(ms) | TPS | 평균 CPU(%) |
|---|---|---|---|---|
| 2 | 39666 | 3 | 220.38 | 13.02 |
| 5 | 93466 | 3 | 519.17 | 16.99 |
| 10 | 115539 | 4 | 641.0 | 20.27 |
| 20 | 129349 | 5 | 717.83 | 24 |
4. 검색 페이지 적용
내부적으로 테스트중인 검색 페이지에 적용해보았습니다. 검색 키워드마다 교정된 키워드를 노출시켰습니다. 데이터가 몇만건 안되다보니 엉뚱한 결과가 나오기도 합니다.
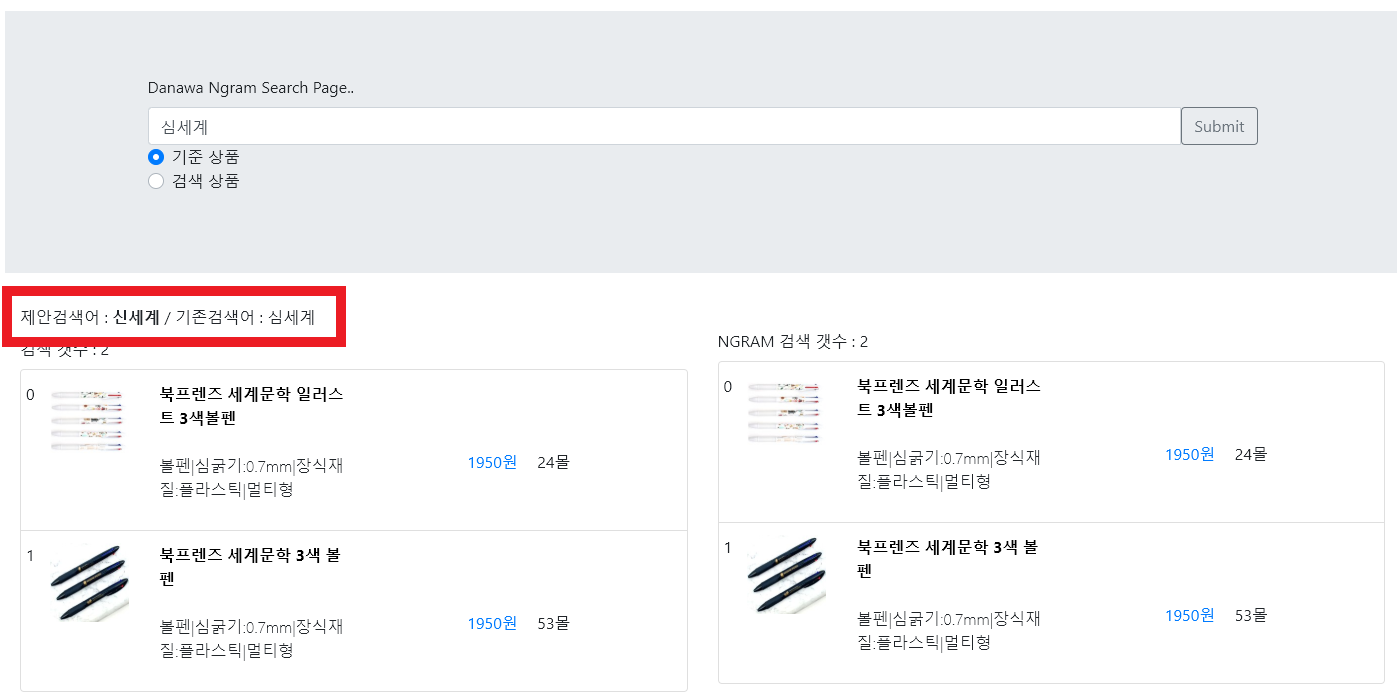
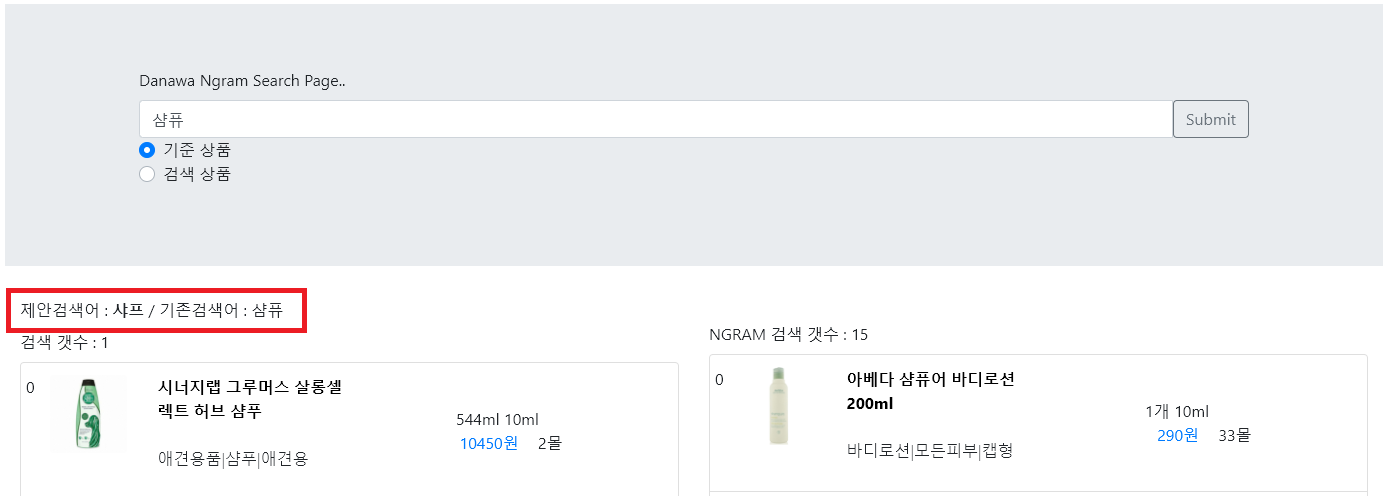
5. 결론
엘라스틱서치를 통해 간단한 오타교정 모듈을 만들어보았습니다. 데이터 수가 많으면 원하는 결과를 얻을 확률이 높아보이지만 데이터가 많다 하더라도 실제 교정된 키워드가 사용자가 의도한 검색 키워드인지 검증해야 합니다. 위 구성을 토대로 품질을 더 높힐 수 있는 방법을 연구해야 할 것 같습니다.
참고 자료
- https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html#search-suggesters
- https://python-jamo.readthedocs.io/en/latest/