다나와 웹 트래픽 로그 데이터 분석 시스템 도입기
개요
안녕하세요. 다나와에서 데이터 파트를 맡아 진행하고 있는 선지호입니다.
다나와에서는 웹 트래픽 로그 데이터 분석을 위해 새로운 내부 서비스를 구축 했습니다.
이 과정중에 저희가 했던 많은 고민과 결정을 공개하여 다나와를 관심있어하는 여러분들께 하나의 사례를 공유해 볼까 합니다.
여정
저희의 여정은 이렇습니다
- 1) 정책 및 필요조건 정하기
- 2) 유비쿼터스 언어 사전 만들기
- 3) 아키텍처 및 기술 검토
- 4) 데이터 포맷 선정
- 5) 데이터 필터링 및 색인
- 6) 데이터 검증
- 7) 데이터 분석 API 및 쿼리
- 8) 엣지케이스 관련 처리
정책 및 필요조건 정하기
먼저, 이 서비스를 개발하기 전, 도메인 전문가와 이야기를 했습니다.
여기서의 도메인 전문가는 기획자 혹은 데이터 분석가, 마케팅 담당 등등 여러 사람이 있을 수 있습니다.
저희는 여기서 기획 겸 데이터 분석을 담당하시는 분과 이야기를 많이 나누었습니다.
아래 내용은 했던 이야기를 재구성 및 각색 해봤습니다.
Q1. 어떤 내용이 분석이 필요한가요 ?
A1. 유저가 다나와의 페이지로 들어와서 마지막으로 이동 했을 때의 모든 사용자 여정에 대해 분석이 필요합니다.
Q2. 그 여정은 사용자 기준으로 보면 될까요?
A2. 아뇨, 세션 단위로 봐주셔야 합니다.
여기서 세션은 사용자가 다나와 페이지에 접속은 하되, 이동한 페이지 간 30분 이상의 텀이 생긴다면 이를 다른 세션으로 바라봐주셔야 합니다.
Q3. 그렇다면 필요한 분석 내용들은 무엇이 있을까요?
A3. 세션단위로 이동한 페이지의 카테고리별 페이지 뷰를 보거나 광고를 몇 세션이나 클릭했는지 여부 등, 이런 내용들이 필요합니다.
Q4. 이 외에 다른 요건들이 있을까요?
A4. 분석에 대해 최대한 빠른 결과가 나왔으면 좋겠습니다. 늦더라도 1분안에는 나왔으면 좋겠어요.
Q5. 꼭 실시간으로 보여져야 하나요?
A5. 아뇨, 실시간으로 보여주지 않아도 됩니다.
Q6. 봇이나 크롤러에 대한 로그 내용은 어떻게 해야 할까요?
A6. 내부에서 사용하는 필터링을 적용해서 그 필터링에 맞게 보여져야 합니다.
저희는 이러한 대화를 거쳐 업무를 진행했습니다.
유비쿼터스 언어 사전 만들기
저희 개발자와 도메인 전문가의 대화에는 이해하고 있는 배경이 다르기 때문에, 이를 맞추기 위해서는 서로 의도에 맞는 언어를 써야 한다고 생각했습니다.
그래서 이를 위해 위에서 이야기를 나누며 나온 언어 사전을 먼저 만들었습니다.
아래는 언어 사전의 예시입니다.
페이지 뷰(page view) - 방문자가 조회한 웹사이트의 페이지의 조회 수 (= 한 개의 로그를 의미함)
유입(inflow) 페이지 - 다나와 웹 사이트에서 첫번째로 접근했을 때의 웹 페이지
유출(outflow) 페이지 - 다나와 웹 사이트에서 마지막으로 이동한 웹 페이지
전환(conversion) - 다나와 웹 사이트를 방문한 사람 중 특정 페이지를 방문한 페이지 뷰 갯수
아키텍처 및 기술 검토
이제 언어사전까지 구축이 되었으니 상세 요건들에 맞게 아키텍처 및 기술에 대해 검토를 했습니다.
저희는 성능에 대한 요건이 몇몇개가 있어 이를 고려하며 어떤 기술을 검토할 지 선정했습니다.
아래는 검토한 기술 목록 입니다.
- Hadoop + Hive
- Elasticsearch
- AWS Opensearch
- AWS Athena
- Graph Database(Neo4j)
Hadoop을 사용하게 될 경우엔 Parquet 형식까지 고려를 해야 했기에 이를 위해 어떤 아키텍처를 가져가야 하는지도 많은 고민이 필요 했습니다.
고민을 해결하기 위해 협력 업체인 AWS의 파트너사인 메가존 클라우드 직원들과 회의도 잡아 진행 했었습니다.
마지막까지 2개의 안(AWS Athena / Opensearch)으로 저울질을 했지만, 저희의 최종 선택은 AWS Opensearch를 이용하기로 했습니다.
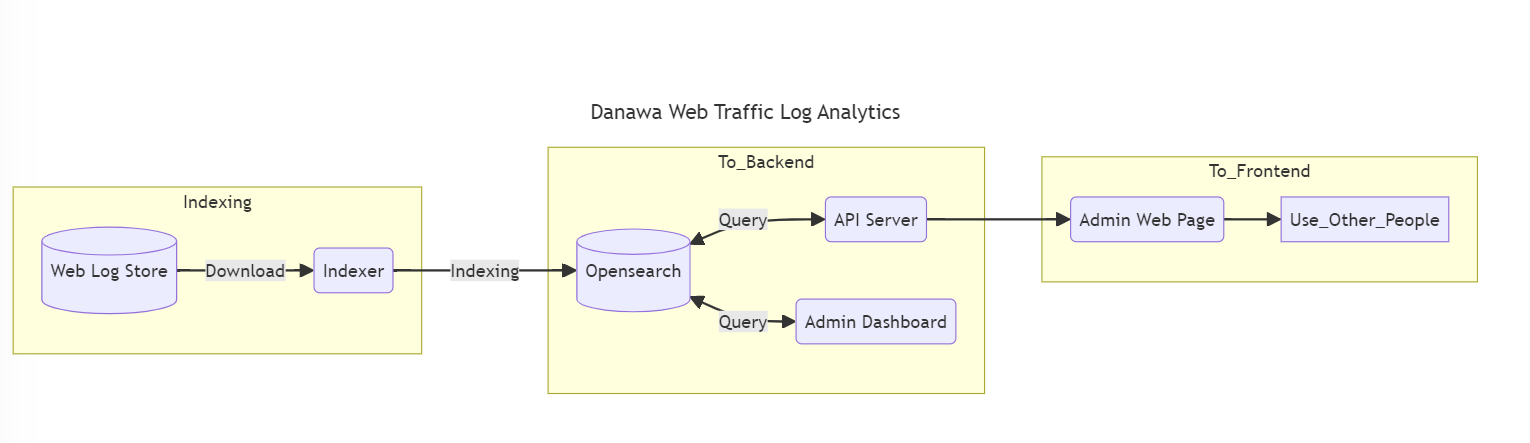
그 이유는 결국 색인, 검색, 집계 과정이 필요한데, 빠른 집계와 빠른 검색이 장점인 Opensearch를 클라우드로 이용하면 관리 포인트 또한 줄어들 수 있기 때문입니다.
데이터 포맷 선정
이제 아키텍처에 맞게 데이터 포맷들을 설계했습니다.
Opensearch는 Elasticsearch 7.10 버전 에서 중간에 따로 나와 진행되는 오픈소스 프로젝트였기 때문에 Elasticsearch와 많은 유사점을 가지고 있었습니다.
그래서 저희 데이터 파트에서는 Elasticsearch를 하나의 기술스택으로 삼고 있었기 때문에 데이터 포맷을 설계할 때 큰 어려움은 없었습니다.
포맷 예시
PUT _index_template/danawa-analytics
{
"index_patterns": [
"danawa-analytics-*-*-*"
],
"template": {
"aliases": {
"danawa-analytics": {}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"refresh_interval": "30s"
},
"mappings": {
"properties": {
"uid": {
"type": "keyword"
},
"url": {
"type": "keyword",
},
"ip": {
"type": "ip"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss.SS||yyyy-MM-dd HH:mm:ss.S||yyyy-MM-dd HH:mm:ss"
},
"event_log": {
"type": "object",
"properties": {
"log_id": {
"type": "keyword"
},
"parameter": {
"type": "object",
"properties": {
"productCode": {
"type": "integer"
},
"shopCode": {
"type": "keyword"
},
"shopProductCode": {
"type": "keyword"
},
"price": {
"type": "integer"
},
"categoryCode1": {
"type": "integer"
},
"categoryCode2": {
"type": "integer"
},
"categoryCode3": {
"type": "integer"
},
"categoryCode4": {
"type": "integer"
}
}
}
}
},
"user_agent": {
"type": "object",
"properties": {
"origin": {
"type": "keyword"
},
"tag": {
"type": "keyword"
}
}
},
"referer": {
"type": "object",
"properties": {
"origin": {
"type": "keyword"
},
"device_type": {
"type": "keyword"
},
"is_bot": {
"type": "boolean"
}
}
},
"sid": {
"type": "keyword"
},
"step": {
"type": "integer"
},
"service_type": {
"type": "keyword"
},
"log_type": {
"type": "keyword"
},
"session_type": {
"type": "keyword"
}
}
}
}
}
데이터 필터링 및 색인
저희의 요건 중에는 데이터 필터링에 대한 요건이 있었습니다.
내부에서 사용하는 데이터 필터링 조건은 일일 단위로 어뷰저와 봇을 제거하는 필터링 조건이 따로 있었습니다.
예를 들자면, ‘IP는 하나 인데, 유저를 판별하는 ID는 전부 다르면서 특정 페이지만 조회하는 경우(ex. 다나와의 상품 설명 페이지)에는 어뷰저로 판단한다’ 라는 기준이 있습니다.
따라서, 이를 위해 데이터 필터링 조건을 먼저 확인한 뒤, 이를 데이터 필터 라이브러리로 만들었습니다
이 필터를 가지고 위에서 정의되었던 요건들을 하나씩 정리하여 배치 작업으로 색인 하였습니다.
색인 대상은 위에서 설계했던 대로 Opensearch가 대상이 되었습니다.
데이터 검증
데이터를 색인 하였다면, 이를 바탕으로 나온 결과들은 거의 다른 플랫폼들이 가지고 있는 데이터들과 비슷할 겁니다.
따라서, 저희는 데이터 검증을 내부에서 활용하고 있던 인사이트, GA4와 같은 웹로그 솔루션들과 비교 하였습니다.
하루 단위, 일주일 단위, 한달 단위, 3개월 단위 순으로 데이터를 비교 하였고 데이터의 증/감 추세나 대략적인 갯수로 비교 하였습니다.
왜냐하면 타사 솔루션을 완전히 신뢰할 수는 없었고, 또한 로깅을 클라이언트 사이드에서 전송하므로 네트워크 패킷 유실에 대한 내용도 감안 해야 했기 때문입니다.
이 기간이 굉장히 길었는데, 색인 시간도 시간이었을 뿐 더러 비교 대상이 많았기 때문에 시간이 가장 오래 걸렸습니다.
마찬가지로, 오래 걸린 만큼 이 기간동안 예외 케이스들이 많이 발견되어 수정하며 더욱 정교한 데이터를 갖출 수 있었습니다.
데이터 분석 API 및 쿼리
이제 색인 된 데이터를 가지고 분석해야 하는 내용들을 하나씩 쿼리로 만들어 API로 제공 하였습니다.
로그가 분석된 내용들을 보고 싶어 하는 내부 팀들이 많이 있었기 때문에, 이를 API로 제공하는 방법이 되어야 양쪽이 다 만족하는 방향이 될 것 같았습니다.
분석 데이터를 제공하기 위해 내부에서 관리자 대시보드를 관리하는 팀과 연계하여, UI를 붙여 접근성과 가독성을 높게 가져가는 방향으로 현재 진행 중입니다.
엣지케이스 관련 처리
아직 저희가 찾지 못한 엣지케이스들은 분명히 존재할 것 같습니다.
이를 위해 저희는 PC/Mobile 영역을 나누어 각 영역별 페이지 체크를 하고 있습니다. (매일 하는건 아닙니다)
최근 발견된 엣지 케이스로는 모바일 영역에서 구글로 통해 들어왔을 때의 로깅 이슈가 있는데, 색인 시 로깅 데이터를 변경하여 색인 할 수 있도록 했습니다.
문제의 범위를 확인 한 후 저희팀과 타팀 중 빠르게, 그리고 근본적으로 처리가 가능한건지 저울질을 해보고 결정을 하게 됩니다.
이번 건은 저희 파트에서 색인 시 변경하여 처리 할 경우 더 적은 작업으로 큰 이슈 없이 처리할 수 있었습니다.
더욱 고민해봐야 하는 점
Q1. 만약 Opensearch가 아닌 다른 서비스로 이전해야 한다면 이전의 요건은 어떻게 해결해야 할까요 ?
A1. 차선책으로는 Hadoop + Hive를 생각중이고, 요건들을 맞추기 위해서는 미리 캐시를 만들어두어야 할 것 같습니다.
Q2. 만약 엣지케이스가 추가로 발견되면 어떻게 하나요 ?
A2. 먼저 검증을 해보고 새롭게 색인을 해야 할 것 같습니다.
현재로서는 아직 정책이 정해진 게 없어서 예상을 해보자면 최근 부터 한달 단위로 변경을 해 나가거나, 아니면 발견된 이후 색인에 대해서 기록해두고 제공할 것 같습니다
결론
저희 파트는 이러한 여정을 거쳐 웹 트래픽 로그 분석 내용이 내부 서비스로 활용될 수 있게 되었습니다.
저희의 도입기를 읽어주신 분들께 모두 감사드립니다.
아직은 많은 개선점이 필요하지만, 이 시스템으로 다나와 서비스에 대한 분석을 시작할 수 있게 되었습니다.
저희 데이터 파트에서는 이러한 데이터를 관심있게 볼 수 있고, 분석하고, 시스템을 구축하는데 흥미가 있는 개발자분들을 모집하고 있습니다.
많은 관심 부탁드립니다.
감사합니다.