influxDB의 flux를 활용하여 기간별 통계 그래프 만들기(grafana)
개요
influxDB로 시계열 데이터를 수집하여 grafana를 통해서 시각화하여 모니터링에 사용중이였습니다. prometheus를 통해서도 수집을 하는 데이터가 있지만, 특정 기간을 그룹핑하는데는 influxDB에 강점이 있다고 판단되어 influxDB 사용하게 되었습니다. flux query을 사용하여 기간별 통계 그래프를 작성하였습니다. 익숙하지 않은 query 이지만, 참고 문서를 활용하면 원하는 그래프를 그릴 수 있습니다.
influxDB 란?
InfluxDB는 인플럭스데이터가 개발한 오픈 소스 시계열 데이터베이스(TSDB:Time-series Database)입니다.
시계열 데이터 베이스 란?
데이터를 저장할 때 시간을 key로 저장하는 데이터베이스 입니다. 시간을 베이스로 조회하는 기능을 제공합니다.
flux query 를 활용하기
저장된 데이터
collection 은 상품수, index 는 동적색인, api는 검색api 호출량 입니다. 서비스를 구분하기 위해서 name으로 tag를 추가했습니다.
| db | measurement | field | tag |
|---|---|---|---|
| search | collection | count | name |
| search | index | count | name |
| search | api | count | name |
A. 일간 상품수 그래프 만들기
< query >
from(bucket:"search")
|> range(start: -${start_time}, stop: now())
|> filter(fn: (r) => r._measurement == "collection")
|> filter(fn: (r) => r._field == "count")
|> filter(fn: (r) => r.name == "기준상품")
|> group(columns: ["count"], mode: "by")
|> aggregateWindow(every: 1d, fn: max)
|> map(fn: (r) => ({_value: r._value, _time: r._time, _field: "기준 상품 수"}))
< 설명 >
bucket은 db를 기입합니다.
range 범위는
(start: -${start_time}, stop: now())
시작값(start)을 start_time 변수로 사용하고
종료값(stop)은 현재(now()
까지로 설정했습니다.
filter 를 사용하여 measurement 는 상품수를 저장한 "collection" 을 사용합니다.
추가적인 filter 를 사용하여 count 이 외에 저장한 field가 있어서 설정을 하였습니다.
tag를 사용하여 서비스 별로 name으로 구분하기 때문에
"기준상품" 을 선택했습니다.
aggregateWindow 집계함수를 사용하여 every: 1d 1일간,
fn: max 최대값을 사용하도록 했습니다.
map을 사용하여 count로 저장된 이름을 "기준 상품 수"로 변경하였습니다.
위에 쿼리로 구성한 그래프 입니다.
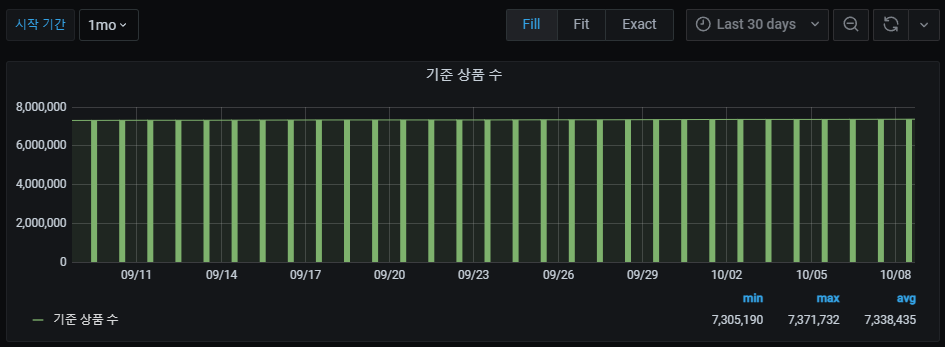
* start_time 설정
grafana 대시보드 설정(Settings)에서 Variables 탭에서 설정하였습니다.

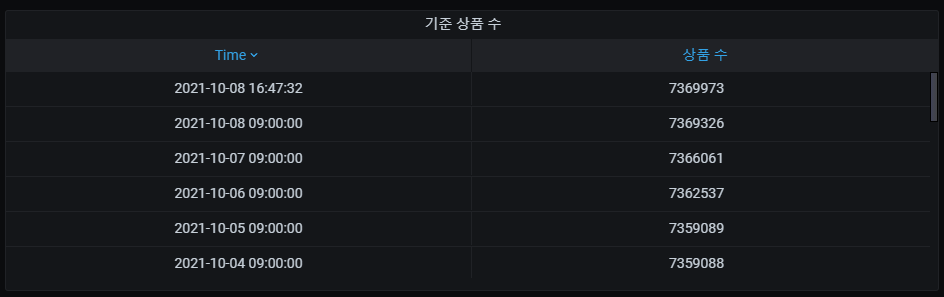
위에 동일한 쿼리를 그래프가 아닌 테이블로도 사용하고 있습니다.
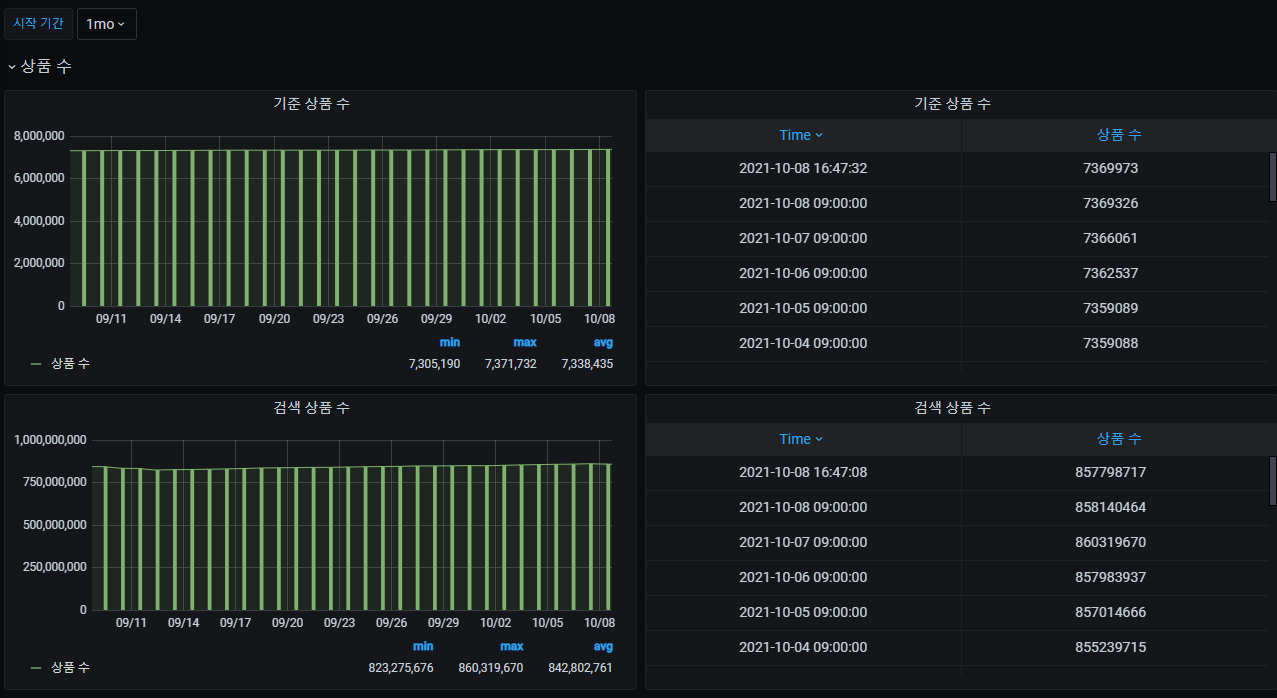
다른 상품 수도 설정해서 대시보드에서는 이렇게 구성하여 사용합니다.
B. 일간 검색량 그래프 만들기
< query >
from(bucket:"search")
|> range(start: -${start_time}, stop: now())
|> filter(fn: (r) => r._measurement == "api1" or r._measurement == "api2" or r._measurement == "api3")
|> filter(fn: (r) => r._field == "count")
|> filter(fn: (r) => r.name == "통합검색API")
|> group(columns: ["count"], mode: "by")
|> aggregateWindow(every: 1d, fn: sum)
|> map(fn: (r) => ({_value: r._value, _time: r._time, _field: "호출 수"}))
< 설명 >
위의 상품수와 다른 부분만 설명하자면
measurement를 api 서버별로 저장을 하기 때문에 or 를 사용하여 합쳤습니다.
집계 함수에서 fn 은 sum을 사용하여 검색량을 합산으로 계산하였습니다.
위에 쿼리로 구성한 그래프 입니다.
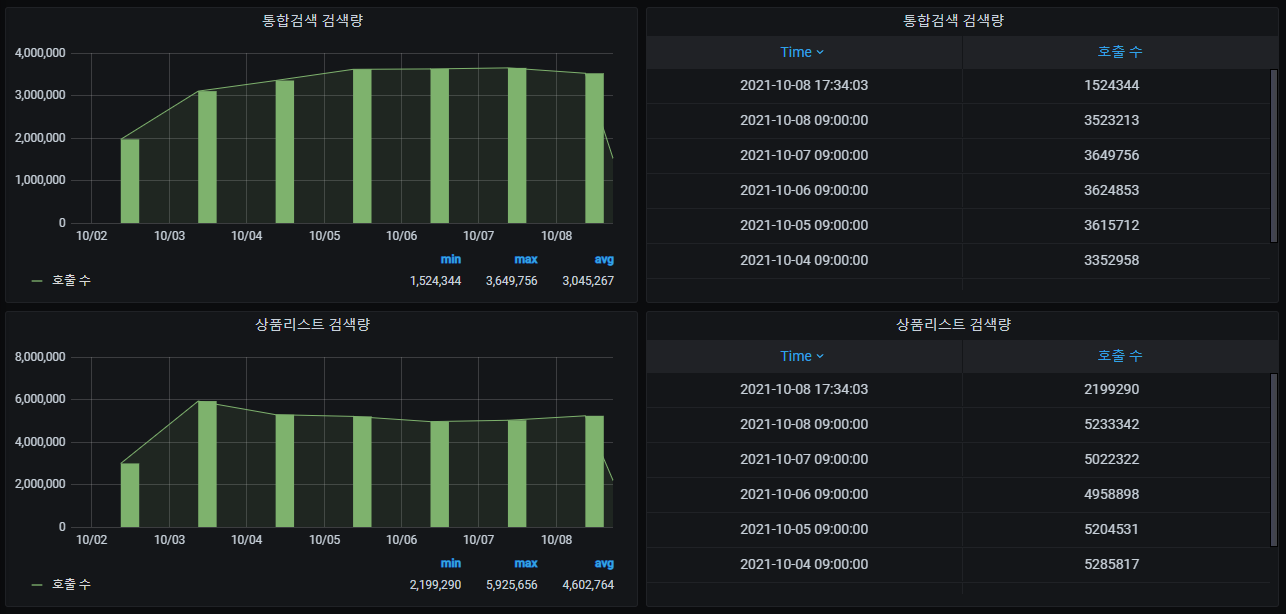
위와 같은 방법으로 동적색인량도 구성하였습니다.
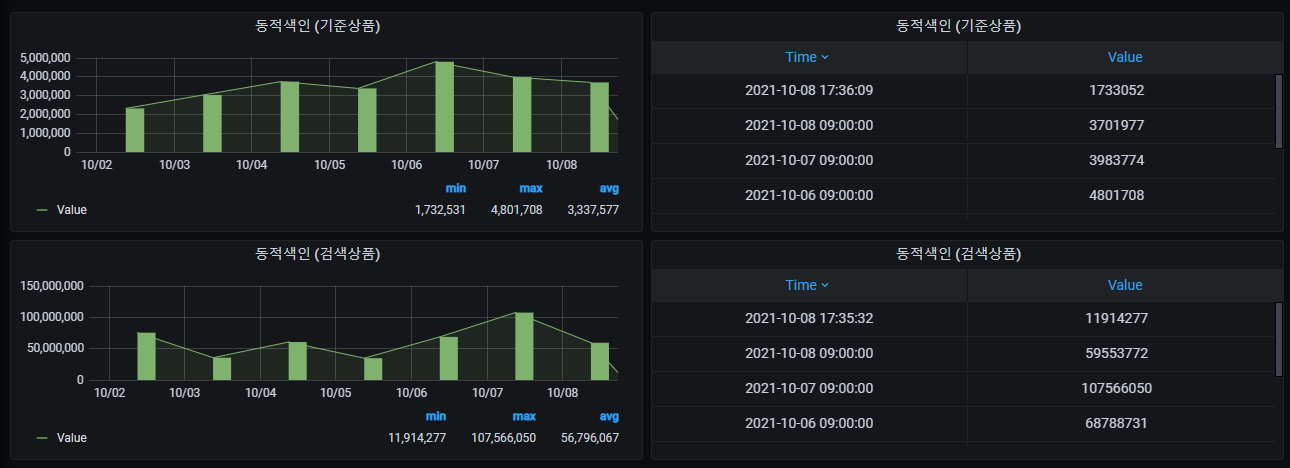
C. 주간, 월간, 연간 그래프 만들기
< query >
> 주간
- 상품수
|> aggregateWindow(every: 1w, fn: max)
- 검색량, 동적색인량
|> aggregateWindow(every: 1d, fn: sum)
|> aggregateWindow(every: 1w, fn: max)
> 월간
- 상품수
|> aggregateWindow(every: 1mo, fn: max)
- 검색량, 동적색인량
|> aggregateWindow(every: 1d, fn: sum)
|> aggregateWindow(every: 1mo, fn: max)
> 연간
- 상품수
|> aggregateWindow(every: 1y, fn: max)
- 검색량, 동적색인량
|> aggregateWindow(every: 1d, fn: sum)
|> aggregateWindow(every: 1y, fn: max)
< 설명 >
집계 함수만 수정하여 기간을 다르게 하여 구성하였습니다.
상품수는 합산이 필요 없으므로, 기간 중에서 max 데이터를 사용하였습니다.
검색량과, 동적색인량 같은 경우는 합산이 필요하기 때문에 일별 합산 집계함수를 먼저 사용하여 데이터를 구성한 뒤 기간 중에 max 함수를 사용하여 일 합산 데이터로 기간중 최대값을 구하였습니다.
기간 별 대시보드를 구분하여 구성하였습니다.
정리
기간별 통계 그래프를 수동으로 작성 했었습니다. 1년 동안 상품수, 검색량이 얼마나 증가하였는지 연간 증가률이 어떻게 되는지 확인하여 의사 결정을 할때 사용하고 있었습니다. 특정 기간(1일 데이터)을 그룹핑 하여 통계 데이터를 만드는 것은 prometheus 에서는 한계가 있었습니다. 그래서 influxDB 를 사용하게 되었습니다. flux query를 사용하여 일간, 주간, 월간, 연간 데이터를 grafana를 활용하여 시각화 하였습니다. 앞으로 기간 통계 데이터를 확인할 때 편리하게 사용할 수 있습니다. DB의 쿼리처럼 flux 쿼리도 순서에 따라서 성능이 변합니다. 그렇기 때문에 filter 순서에도 신경을 써서 작업하시는 것을 추천드립니다.
참고 자료
- https://ko.wikipedia.org/wiki/InfluxDB
- https://docs.influxdata.com/flux/v0.x/stdlib/