node exporter를 활용한 서버 시스템 모니터링
개요
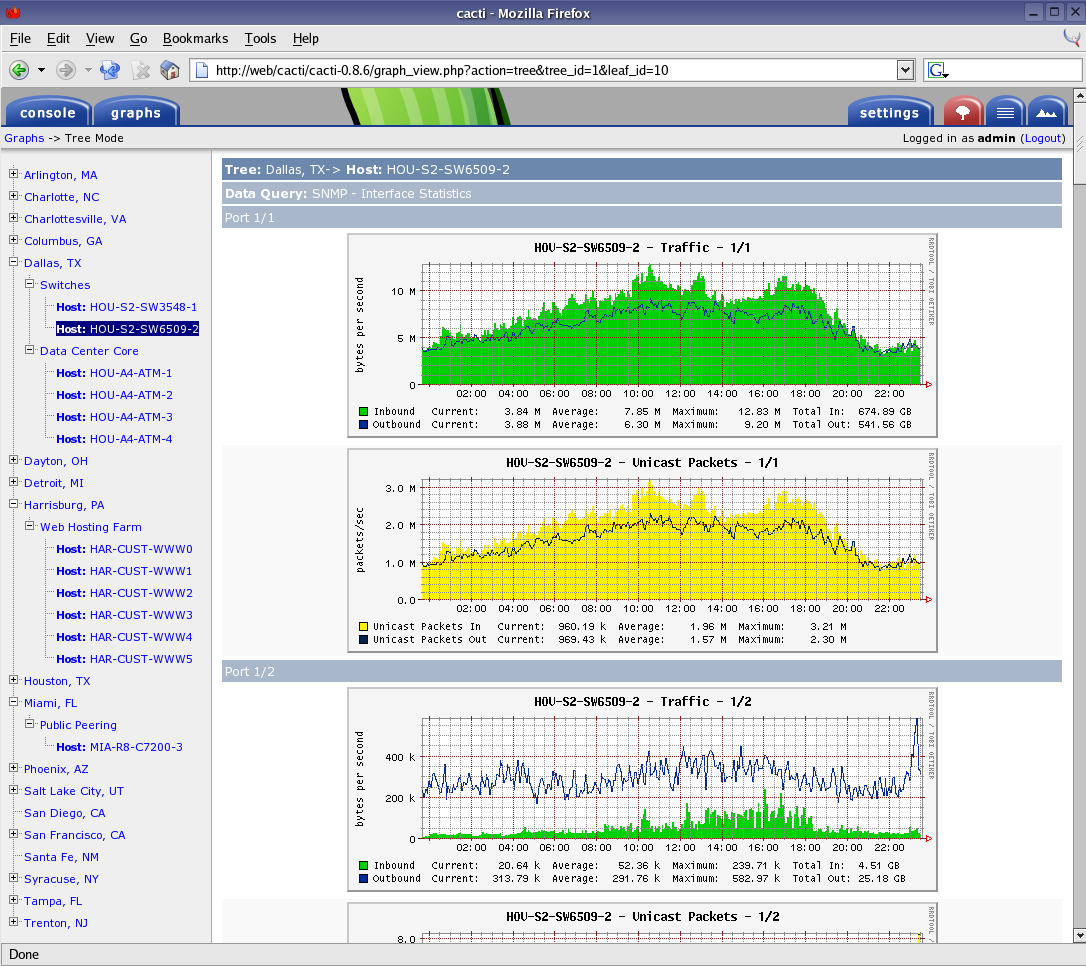
서버 시스템 및 네트워크를 모니터링 하기 위해서 기존에는 cacti를 사용중입니다. 검색API, 동적색인 모니터링을 그라파나(grafana)에 구축하여, 서버 사용량과 함께 보기 위해서는 그라파나 + cacti를 사용했습니다. 검색 서비스와 서버 사용량의 연관 관계 및 모니터링을 한번에 하고 싶었습니다. 그래서 node-exporter 를 활용하여 그라파나 대시보드에 추가하였습니다.
cacti 란?
Cacti는 오픈 소스, 업계 표준 데이터 로깅 도구 RRDtool의 프론트 엔드 애플리케이션으로 설계된 공개 소스 웹 기반 네트워크 모니터링 및 그래프 도구입니다.
Cacti는 사용자가 미리 결정된 간격으로 서비스를 폴링하고 결과 데이터를 그래프로 표시 할 수 있습니다.
node exporter 란?
서버 시스템(cpu, loadAvg, memory) 및 네트워크 정보를 수집하여 메트릭(metric) API로 제공합니다. 프로메테우스(prometheus)에서 노드 익스포터 매트릭 API(end point)를 target에 등록하여 스크랩할 수 있습니다.
node exporter 설치 : docker-compose.yml
- docker-compose.yml 파일
version: "2"
services:
node-exporter:
image: prom/node-exporter
ports:
- 9100:9100
environment:
- "TZ=Asia/Seoul"
restart: always
command:
- --collector.disable-defaults
- '--collector.cpu'
- '--collector.loadavg'
기본적으로 메트릭으로 제공되는 항목이 다양하지만, 필요한 정보만 수집하기 위해서 수집하지 않는것을 기본 설정으로 변경하고 collector.disable-defaults cpu, loadavg만 수집하도록 설정하였다.
- 정상 기동 확인
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9d863d35e5ff prom/node-exporter "/bin/node_exporter …" 8 days ago Up 8 days 0.0.0.0:9100->9100/tcp node-exporter_node-exporter_1
- 메트릭 API 확인
$ curl 127.0.0.1:9100/metrics
...
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 3.770487009e+07
node_cpu_seconds_total{cpu="0",mode="iowait"} 188253.94
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 18136.75
node_cpu_seconds_total{cpu="0",mode="softirq"} 61737.1
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 323109.26
node_cpu_seconds_total{cpu="0",mode="user"} 2.23835272e+06
node_cpu_seconds_total{cpu="1",mode="idle"} 3.825488709e+07
node_cpu_seconds_total{cpu="1",mode="iowait"} 73230.44
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 2.05
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 1.24
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5 1.45
...
프로메테우스 타켓 추가
scrape_configs:
- job_name: 'server'
metrics_path: '/metrics'
static_configs:
- targets: ['127.0.0.1:9100','127.0.0.2:9100',...]
그라파나에 대시보드 추가하기
- 모든 서버의 CPU 사용량(%) 및 1분 평균 load를 하나의 패널로 추가하기
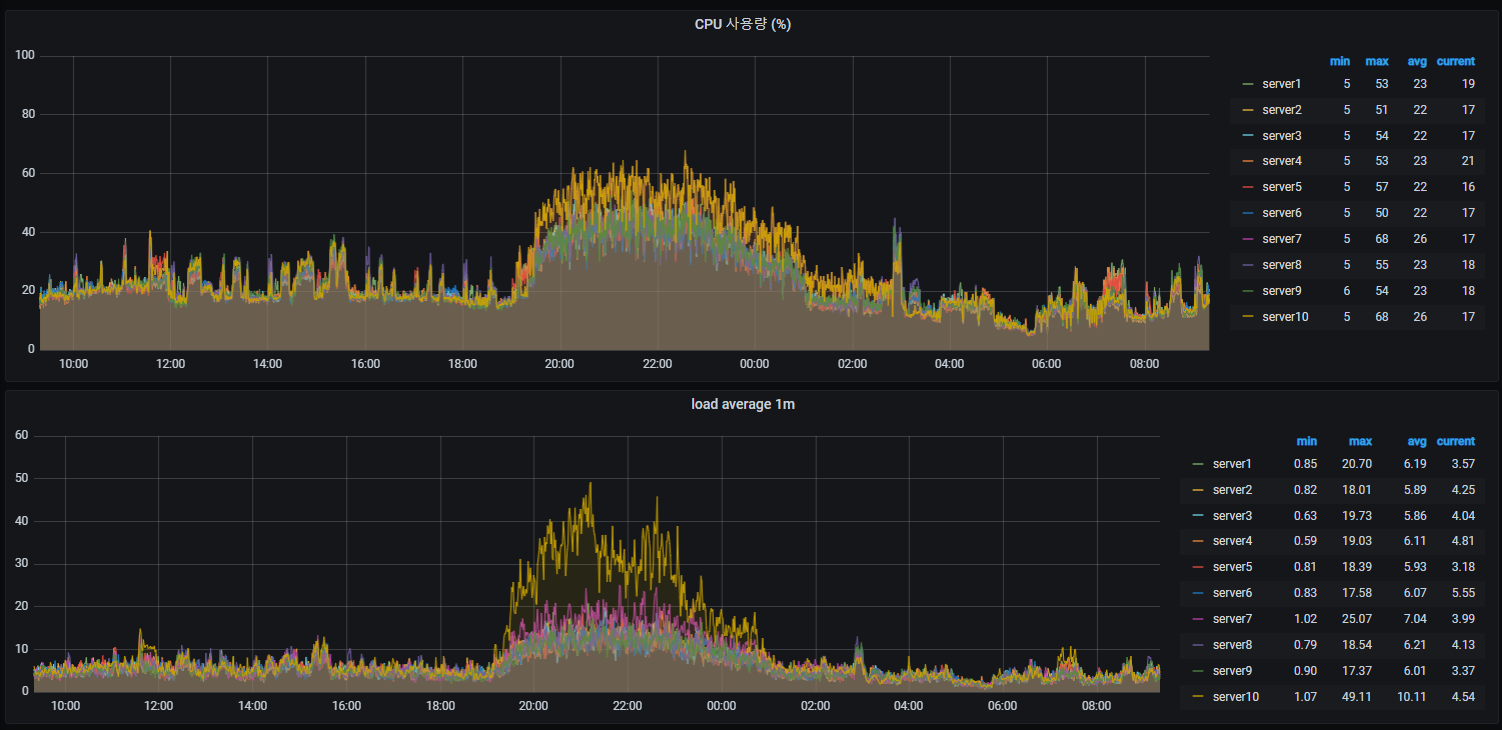
cpu
cpu 코어가 32개 이기 때문에 나누기 32를 하고 rate 를 사용하여 곱하기 100을 하였습니다.
1번과 2번 방안은 instance를 고정하였기 때문에 쿼리 10개를 직접 추가해야 하고
3번 방안은 instance 를 제거하고 by (instance) 를 사용하여 서버별로 구분되도록 할 수 있습니다.
1번 방안
sum(rate(node_cpu_seconds_total{instance="127.0.0.1:9100"}[1m])/32*100)
- sum(rate(node_cpu_seconds_total{instance="127.0.0.1:9100", mode="idle"}[1m])/32*100)
2번 방안
sum(rate(node_cpu_seconds_total{instance="127.0.0.1:9100",mode!="idle"}[1m])/32*100)
3번 방안
sum(rate(node_cpu_seconds_total{mode!="idle"}[1m])/32*100) by (instance)
1분 평균 load
load avg 수치는 그대로 사용하면 되기 떄문에 간단하며, 서버(instance)를 지정하고 사용하거나 지정하지 않고 사용하면 된다.
1번 방안은 쿼리 10개를 직접 추가해야한다.
1번 방안
node_load1{instance="127.0.0.1:9100"}
2번 방안
node_load1
- 특정 서버 cpu 및 평균 load 패널 추가하기
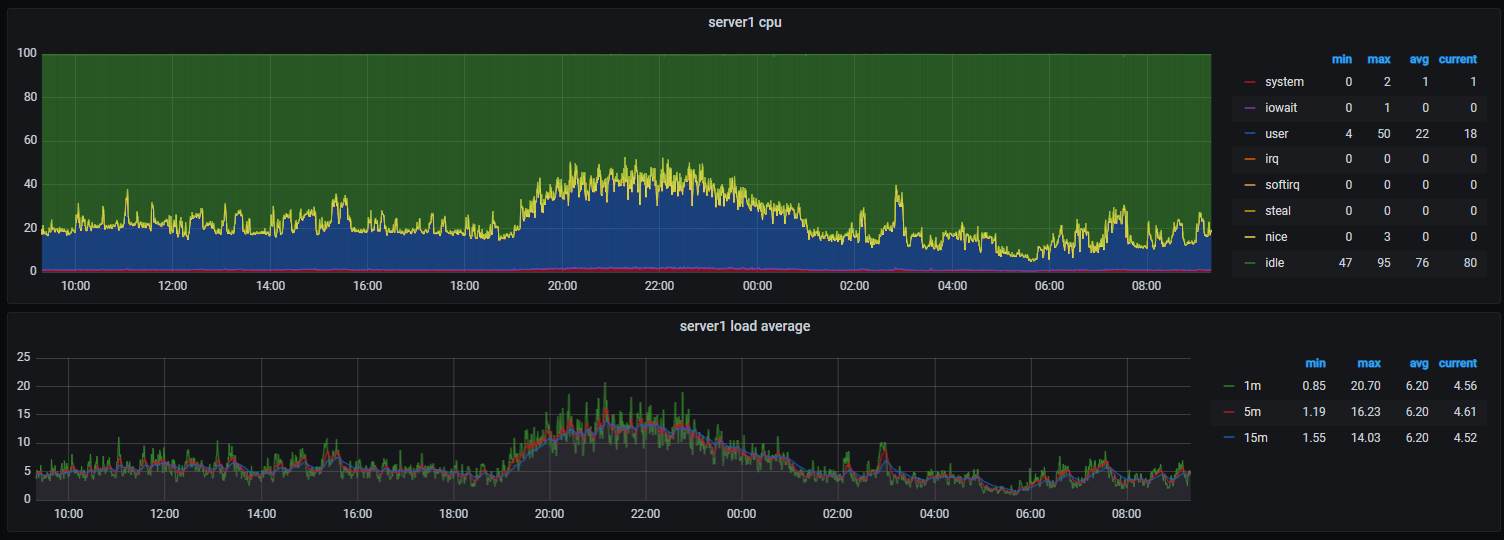
server1 cpu 패널
sum(rate(node_cpu_seconds_total{instance="127.0.0.1:9100"}[1m])/32*100) by (mode)
server1 load average 패널
node_load1{instance="127.0.0.1:9100"}
node_load5{instance="127.0.0.1:9100"}
node_load15{instance="127.0.0.1:9100"}
검색서비스 모니터링 대시보드
검색API 호출량, 평균 응답속도, CPU 사용량, 동적색인량을 한번에 파악 할 수 있도록 구성한 대시보드입니다.
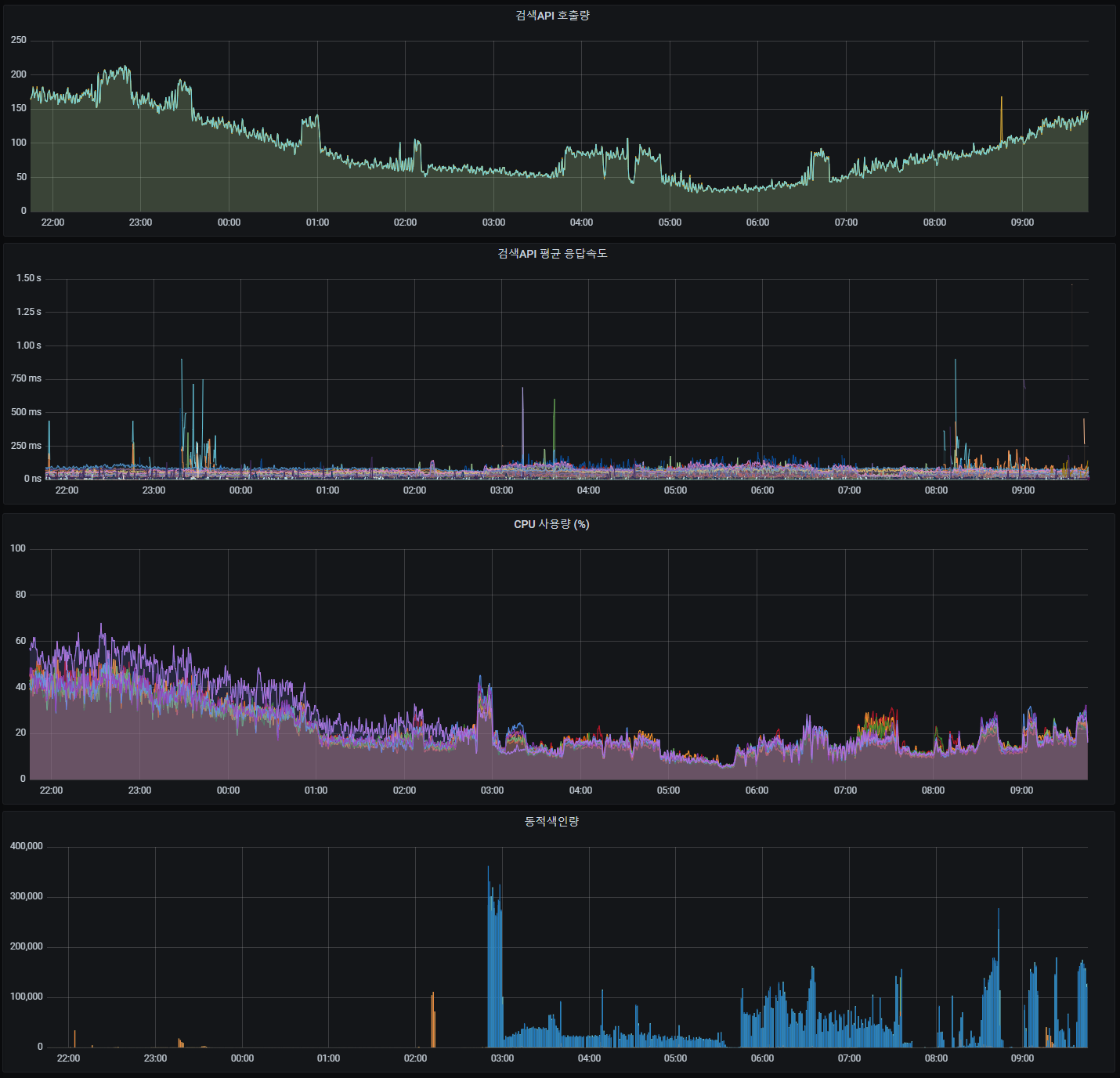
정리
node-exporter를 활용하여 그라파나에서 서버 시스템을 모니터링 할 수 있도록 추가했습니다. 그라파나에 검색API, 동적색인등 검색 운영에 관련된 서비스가 추가되어 있어서 모니터링을 활용하고 있습니다. 서버 사용량 관련해서도 함께 볼 수 있게 되어, 모니터링을 하는데 편리하게 사용할 수 있게 되었습니다. CPU가 증가한다면 원인을 찾을때 검색API, 동적색인의 영향도 파악을 편하게 할 수 있습니다. 그리고 cacti에서는 여러 서버의 cpu를 한번에 확인 하기 어려웠지만, 그라파나에서는 모든 서버의 CPU를 하나의 패널에서 확인 할 수 있다는 장점이 있습니다. ES stack monitoring 에서도 모든 노드의 CPU의 그래프를 보기는 어렵습니다. 추가적으로 서버 CPU 사용량이 임계치를 넘을때 텔레그램 알람 기능도 추가했습니다.
참고 자료
- https://en.wikipedia.org/wiki/Cacti_(software)
- https://github.com/prometheus/node_exporter