큐 라우터 (Q router) : Q to Q
소개 : Queue Router 란?
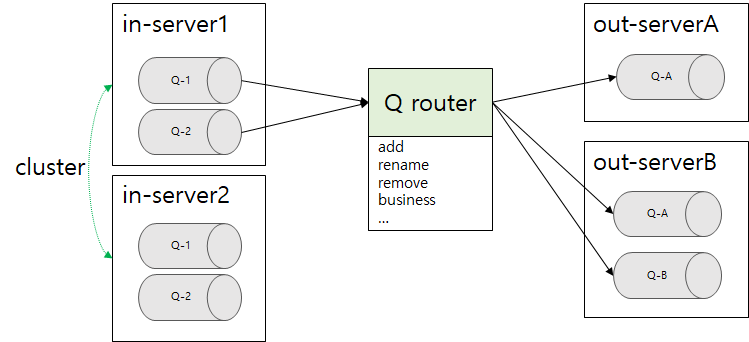
다른 서비스에서 발행한 메세지가 적재하는 큐를 읽어서 우리 서비스에서 사용하는 큐에 넣어주는 기능을 합니다.
데이터에 따라서 가공하는 방식과 보내야 하는 서버 및 큐가 다르기 때문에 라우터 내에서 파이프라인 이라고 정의한 곳을 통과시켜서 데이터를 가공합니다.
큐는 rabbitmq를 사용했습니다.
설정
input.queue 설정에는 메세지를 가져올 MQ 정보를 기입하고 큐 이름은 input.queue.큐이름 다음에 넣어줍니다.
output.queue 설정에는 메세지를 보낼 MQ 정보를 기재 합니다. 다중 서버에 동일한 큐 이름을 보낼 수 있습니다.
가져오는 MQ 서버와 큐, 보낼 MQ 서버와 큐가 각각 다중으로 가능하기 때문에 N : M 관계가 가능합니다.
사용하는 목적에 맞게 다양하게 설정 가능합니다.
ex) in-server1, 2 클러스터링된 Q서버의 Q-1, Q-2 큐에 있는 메세지를 가져와서 action에 따라서 out-serverA, B 서버의 Q-A, Q-B 에 넣어줍니다.
input.queue.Q-1.addresses=in-server1.danawa.com,in-server2.danawa.com
input.queue.Q-1.username=username
input.queue.Q-1.password=password
input.queue.Q-1.virtualhost=virtualhost
input.queue.Q-1.pipeline=preparePipeline,renamePipeline,removePipeline,businessPipeline,splitPipeline,addPipeline,bulkPipeline,routePipeline
input.queue.Q-2.addresses=in-server1.danawa.com,in-server2.danawa.com
input.queue.Q-2.username=username
input.queue.Q-2.password=password
input.queue.Q-2.virtualhost=virtualhost
input.queue.Q-2.pipeline=preparePipeline,addPipeline,bulkPipeline,routePipeline
output.queue.Q-A.addresses=out-server1.danawa.com,out-server2.danawa.com
output.queue.Q-A.username=username,username
output.queue.Q-A.password=password,password
output.queue.Q-A.virtualhost=virtualhost,virtualhost
output.queue.Q-B.addresses=out-server2.danawa.com
output.queue.Q-B.username=username
output.queue.Q-B.password=password
output.queue.Q-B.virtualhost=virtualhost
pipeline은 기능별로 수행할 수 있도록 만들어 두었습니다.
원하는 기능만 수행하도록 지정할 수 있습니다.
처음에는 preparePipeline 을 통과해야 하며 마지막에는 bulkPipeline, routePipeline 을 통과해야 하는 규칙이 있습니다.
메세지의 데이터가 map, collection, list인 경우가 있기 때문에 list로 통일하는 과정을 preparePipeline에서 수행됩니다.
데이터를 묶어서 한 번에 보내야 하는 경우가 있기 때문에 bulkPipeline은 마지막 바로 전에 수행합니다.
마지막으로 routePipeline 에서는 보낼 Q를 지정하게 됩니다.
큐에 서버가 설정되는 구조이기 때문에 보낼 큐만 설정하면 지정된 서버에 모두 보낼 수 있게 됩니다.
현재 pipeline 기능은 컬럼명(key) 변경, 컬럼 제거, 컬럼과 데이터(value) 추가, 데이터가 리스트로 들어 있는 경우 데이터 1개 단위로 분리, 특정 비지니스 로직 기능들이 있습니다.
# {action : C|U|D, ...}
variables.CudType={
"A.insert": "C",
"A.modify": "U",
"A.delete": "D",
"B.move": "U",
"B.insert": "C",
"B.modify": "U",
"B.delete": "D"
}
# {action : {before name:after name, ... }, ...}
variables.renames={
"A.insert": {"code": "seq"}
"A.modify": {"code": "seq"}
"B.move": {"code": "seq", "name": "title"}
"B.insert": {"code": "seq", "name": "title"}
"B.modify": {"code": "seq", "name": "title"}
}
# {action : {remove name, ... }, ...}
variables.removes={
"A.modify": {"aaa", "bbb", "ccc"},
"B.modify": {"ddd"}
}
# {business action name, ...}
variables.business={
"B.move"
}
# {action : split name, ...}
variables.splits={
"A.delete": "code",
"B.delete": "code"
}
# {action : bulk count, ...}
variables.bulks={
"A.delete": 5000,
"B.delete": 5000
# {action : {key:value, ... }, ...}
variables.adds={
"A.insert": {"time":"time"},
"B.insert": {"tag":"tag1"}
}
# {action : {output queue name, ...}, ...}
variables.routes={
"A.insert": {"Q-A","Q-B"},
"A.modify": {"Q-A"},
"A.delete": {"Q-A"},
"B.move": {"Q-B"},
"B.insert": {"Q-A","Q-B"},
"B.modify": {"Q-B"},
"B.delete": {"Q-B"}
}
개발 내용
input과 output 정보는 @ConfigurationProperties 어노테이션의 prefix를 사용하여 가져옵니다.
@Component
@ConfigurationProperties(prefix = "input.queue")
public class InputConfig<String, V> extends HashMap<String, V> {
// 설정 파일에서 prefix 값으로 시작하는 설정값을
// InputConfig 클래스의 객체를 HashMap 형식으로 제공
}
설정 파일의 큐에 설정한 파이프라인 리스트(pipelineList)를 가져와서 큐의 파이프 라인을 세팅합니다.
가져오는 큐 마다 파이프라인을 다르게 설정할 수 있습니다.
@Primary
@Bean("pipelineList")
public Map<String, List<PipeLine>> pipelineList() {
Map<String, List<PipeLine>> pipeline = new HashMap<>();
Iterator<String> iterator = inputConfig.keySet().iterator();
while (iterator.hasNext()) {
String queueName = iterator.next();
Map<String, Object> map = (HashMap<String, Object>) inputConfig.get(queueName);
String[] pipelines = map.get("pipeline").toString().split(",");
logger.info("pipeline:{} {}", queueName, pipelines);
pipeline.put(queueName, new ArrayList<>());
for (String name : pipelines) {
pipeline.get(queueName).add((PipeLine) context.getBean(name));
logger.info("added queue: {}, pipeline: {}", queueName, name);
}
}
return pipeline;
}
위에서 세팅한 큐의 파이프 라인 리스트가 아래 로직을 통해서 수행됩니다.
메세지가 파이프 라인을 통과하는 부분
// 파이프라인 통과
for (int i = 0; i < pipelineList.size(); i++) {
try {
deliveries = pipelineList.get(i).pipeline(deliveries);
} catch (Exception e) {
logger.error("[{}] pipeline index {} error", inputQueue, i);
logger.error("pipeline error ", e);
}
}
RemovePipeline의 로직
variables.removes 설정 값으로 처리하기 때문에 지워야 하는 컬럼이 변경되면 코드를 수정하지 않고 설정값만 변경해주면 됩니다.
private final Map<String, List<String>> removes;
public RemovePipeline(@Value("#{${variables.removes}}") Map<String, List<String>> removes) {
this.removes = removes;
}
@Override
public List<Delivery> pipeline(List<Delivery> deliveries) throws Exception {
List<Delivery> retDeliveries = new ArrayList<>();
for (Delivery delivery : deliveries) {
if (removes.get(delivery.getAction()) != null) {
Map<String, Object> message = new Gson().fromJson(
delivery.getJson(),
new TypeToken<Map<String, Object>>() {}.getType()
);
for (String key : removes.get(delivery.getAction())) {
if (message.get(key) != null) {
message.remove(key);
}
}
delivery.setJson(new Gson().toJson(message));
}
retDeliveries.add(delivery);
}
return retDeliveries;
}
정리
spring boot를 처음 사용해서 개발해봤습니다. 라이브러리, 설정 관련이 심플해서 편했습니다.
큐 라우터 개발을 시작하기 전, 회의하면서 팀장님과 팀원분이 제게 해주셨던 이야기가 기억에 남습니다.
database를 사용할 때, 사용자가 추가하려는 테이블 이름이 database 소스 안에 하드 코딩이 되어 있냐는 질문이었습니다.
당연히 테이블 이름은 사용자는 마음대로 정하고 테이블을 자유자재로 추가, 수정, 삭제하면서 사용합니다.
그래서 하드코딩은 없애고, 설정 파일로 모든 내용을 담을 수 있도록 목표를 정했습니다.
기능 단위로 파이프라인을 만들고, 원하는 파이프라인을 이어붙여서 사용하도록 구상했습니다.
비지니스 로직은 설정으로 옮기는 것에 어려움이 있어서 별도의 파이프라인을 만들었습니다.
예전에는 서버나 경로, URL, 아이디 같은 경우만 설정 파일에 담았습니다.
이제는 변수명이 변경되거나 라우팅 해야 하는 큐의 개수가 달라져도 코드 수정 없이 설정만 변경하여 재기동하면 됩니다.
개발하면서 새로운 경험과 다른 생각을 가질 수 있었습니다. 큐 라우터를 사용하거나 유지보수하는 개발자가 편리함을 느꼈으면 좋겠습니다.