캐시 TTL 산정
개요
캐시를 효율적으로 사용하려면 적절한 TTL(Time To Live)을 설정해야 합니다. 검색 로그를 분석 및 캐시의 hit-time을 집계하고 캐시 TTL에 따른 HIT율을 계산하는 방법에 대해서 소개합니다.
이 포스팅에서는 같은 uri가 검색되면 캐시에 hit 할 수 있다고 가정합니다. 같은 uri로 검색되었을 때 시간의 차를 계산합니다. 계산된 시간의 차를 집계하여 캐시 TTL에 따른 HIT율을 예상할 수 있습니다.
구성도
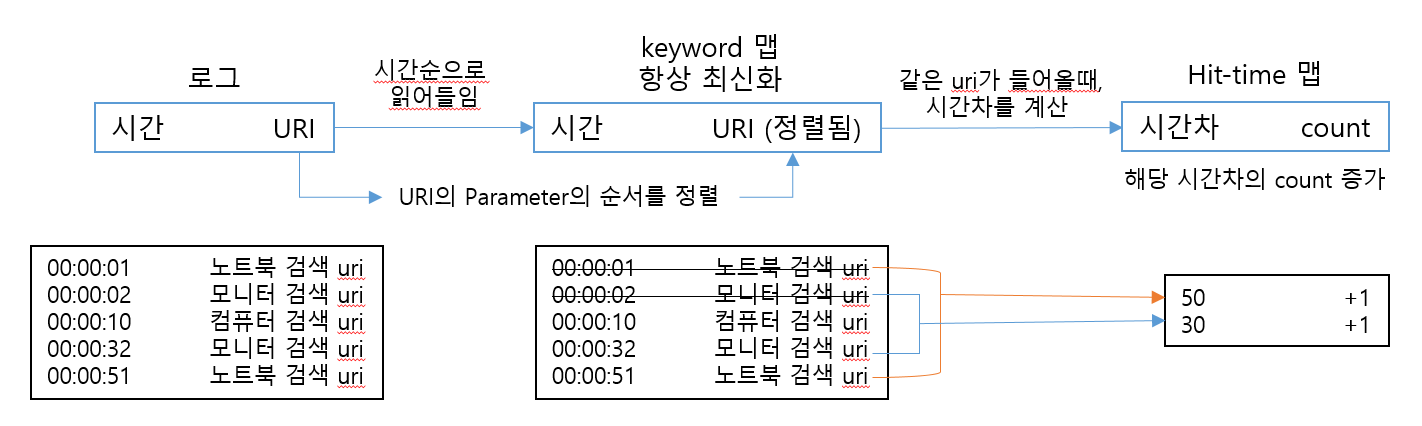
검색 로그 분석하기
로그 예시) 09:30:15 /product/search?keyword=apple&option=fruit&page=1&sort=popularity
- logString = “09:30:15 /product/search?keyword=apple&option=fruit&page=1&sort=popularity”
- url = /product/search
- parameter = {“keyword”:”apple”, “option”:”fruit”, “page”:”1”, “sort”:”popularity”}
parameter의 key-value 값이 일치하면 순서와 관계없이 같은 uri 로 요청됩니다. uri를 집계하는 키로 사용하기 위해 parameter의 순서를 정렬합니다. TreeMap은 이진트리를 기반으로 한 Map 컬렉션으로, 객체를 저장하면 자동으로 정렬됩니다.(sort-by-key)
String uriString = URLDecoder.decode(logString.split(" ")[1], "UTF-8");
String sortedUriString = "";
TreeMap<String, String> uriMap = new TreeMap<String, String>();
if (uriString.contains("?")) {
uriString = uriString.split("\\?")[1];
}
if (uriString.contains("&")) {
for (String parameter : uriString.split("&")) {
if (parameter.contains("=")) {
String parameterKey = parameter.split("=")[0];
String parametervalue = "";
if (parameter.split("=").length > 1) {
parametervalue = parameter.split("=")[1];
}
uriMap.put(parameterKey, parametervalue);
}
}
} else {
if (uriString.contains("=")) {
String parameterKey = uriString.split("=")[0];
String parametervalue = "";
if (uriString.split("=").length > 1) {
parametervalue = uriString.split("=")[1];
}
uriMap.put(parameterKey, parametervalue);
} else {
System.out.println("uri에 parameter 없음");
}
}
for (String key : uriMap.keySet()) {
sortedUriString += key + "=" + uriMap.get(key) + "&";
}
sortedUriString = sortedUriString.substring(0, sortedUriString.length() - 1);
sortedUriString에 정렬된 uri값을 저장하였습니다.
캐시 hit-hime 집계하기
같은 uri로 캐시에 hit되는 시간을 계산하고 집계하는 과정입니다. 초 단위를 기준으로 집계하였습니다.
String timeString = logString.split(" ")[0];
HashMap<String, String> keywordMap = new HashMap<String, String>();
TreeMap<Long, Integer> hitTimeBucket = new TreeMap<Long, Integer>();
if (keywordMap.containsKey(sortedUriString)) {
// 키워드맵에 keyword가 있는경우 = 같은 키워드가 다시 검색된 경우
SimpleDateFormat transFormat = new SimpleDateFormat("HH:mm:ss");
Date time1 = transFormat.parse(keywordMap.get(sortedUriString).toString());
Date time2 = transFormat.parse(timeString);
Long timeDiff = (time2.getTime() - time1.getTime()) / 1000;
if (hitTimeBucket.containsKey(timeDiff)) {
hitTimeBucket.replace(timeDiff, hitTimeBucket.get(timeDiff) + 1);
} else {
hitTimeBucket.put(timeDiff, 1);
}
keywordMap.replace(sortedUriString, timeString);
} else {
// 키워드맵에 keyword가 없는경우 = 처음 검색된 경우
keywordMap.put(sortedUriString, timeString);
}
hitTimeBucket에 시간별 hit-time count를 저장합니다.
캐시 TTL에 따른 HIT율 계산하기
집계된 결과를 바탕으로 캐시 TTL에 따른 HIT을 계산해보겠습니다. 저는 데이터를 분석하기 위해 집계된 결과를 csv파일로 만들고, 엑셀로 데이터를 가공하였습니다.
표에서 캐시에 hit되지 않은 키워드, 즉 처음 검색된 키워드는 고려되지 않았습니다. 데이터는 4월 6일 다나와 통합검색 로그 기준임을 알려 드리며 초 단위로 집계된 데이터를 분 단위로 가공하여 정리하였습니다.
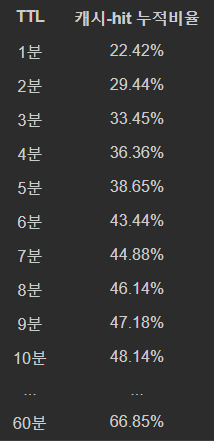
캐시-hit 누적비율 = (해당 시간 내에 캐시-hit된 횟수) / (전체 캐시-hit된 횟수) * 100
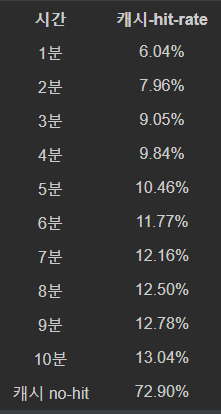
캐시-hit-rate = (해당 시간 내에 캐시-hit된 횟수) / (전체 검색 횟수) * 100
정리
이번에 검색 로그 분석 및 집계를 통해 캐시 TTL에 따른 HIT율을 계산해 보았습니다. 같은 키워드로 얼마나 검색되고 어느정도 시간 사이에 다시 검색되는지 알 수 있었습니다. 그리고 처음 검색된 경우도 집계에 포함하면 캐시의 Hit-Rate(캐시 적중률)도 계산할 수 있습니다.
캐시는 서비스의 응답시간을 줄이고 서버 트래픽 감소 효과를 제공하지만 캐시의 TTL을 길게 설정하면 서비스의 변경사항이 늦게 반영된다는 단점이 있습니다. 다나와에서는 실시간 가격비교 서비스도 제공하고 있기 때문에 캐시 TTL을 너무 길게 설정하는 것은 적당하지 않습니다. 서비스마다 성능상 이점과 데이터 보존 기간 사이의 균형을 찾아 캐시의 TTL을 설정하는 것이 캐시의 이점을 최대한 활용하는 방법입니다. 캐시 TTL을 산정하는 분들에게 도움이 되었으면 좋겠습니다. 감사합니다.
참고자료
https://docs.oracle.com/javase/8/docs/api/java/util/TreeMap.html