검색 모니터링 시스템 구축
개요
검색 운영을 하면서 다양한 정보를 한 페이지로 모니터링 할 수 있는 시스템을 구축하였습니다. 다양한 프로그램과 서비스를 운영하다 보면 현재 상태와 과거의 추이를 한번에 확인하고 모니터링 하기가 쉽지 않습니다. 검색API 또는 검색엔진, 동적색인의 현재 상태를 파악하기 위해서는 각 서비스에 특화된 모니터링 툴을 사용해서 확인해야 했습니다. 그리고 하루 하루 쌓이는 통계 데이터를 저장하고, 기간에 따른 추이를 보기 위해서 사람이 직접 데이터를 다루는 과정이 필요했습니다. 이러한 불편함을 개선하고자 다양한 로그를 시계열로 분석하여 한 곳으로 모으고 시각화 까지 하는 작업을 진행하였습니다. 검색 모니터링 시스템에는 색인된 상품 수, 동적색인 소요 시간, 동적색인 량, 동적색인 대기 메세지 수, 검색량, 검색속도 데이터를 분, 시간, 일 단위로 현재 상태와 추이를 모니터링을 할 수 있습니다.
-
로그 스크랩 (golang)
모니터링에 추가할 프로그램의 로그를 실시간으로 수집하여 지정한 시간 단위 데이터로 가공해서 api로 제공합니다. - 검색API, 동적색인 -
매트릭 스케줄러 (golang)
로그 스크랩 API, ElasticSearch API, rabbitmq API 를 설정한 시간 단위로 호출하여 influxDB에 저장합니다. -
influxDB : 저장
시계열 데이터베이스로 타임 스탬프 데이터 전용으로 작성된 맞춤형 고성능 데이터 저장소 입니다. 기존에 활용하던 prometheus 는 시계열의 그룹화에 한계가 있으므로 influxDB로 변경하게 되었습니다. -
grafana : 시각화
시각화는 기존에 사용하던 grafana를 사용했습니다. chronograf 보다는 다양하고 유연한 대시보드에 사용하기 좋습니다.
구성도
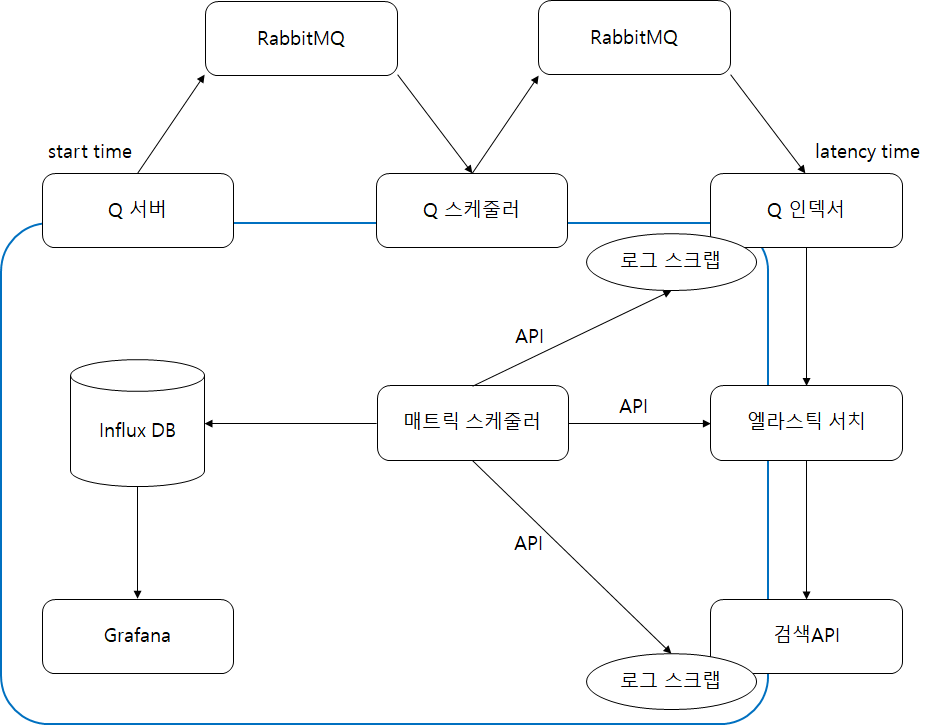
로그 스크랩
로그 스크랩은 다양한 로그를 실시간으로 수집하여 지정한 시간 단위로 데이터를 가공하여 API로 제공합니다.
다양한 로그를 동시에 수집할 수 있도록 고루틴(Goroutine)을 사용하고, 동기화 문제를 해결하기 위해서 sync.Map{} 을 사용하였습니다.
로그 수집에 대한 확장성을 고려하여 신규로 수집하고 싶은 로그에 대해서는 parser만 추가하면 되도록 구성했습니다.
설정 내용)
큐 인덱스의 로그와 검색API 로그를 수집하여 지정된 시간 단위로 가공하여 제공하는 API 설정 내용입니다.
logs[]는 수집할 로그의 단위입니다.
type은 로그의 parser를 구분하는 설정값 입니다.
path, file은 경로와 파일명이며, unit은 API로 가공하고 제공될 시간의 단위 데이터입니다.
{
"port": 9000,
"logs": [
{
"type": "indexer",
"path": "queue-index/logs",
"file": "application.log",
"unit": "Minutes"
},
{
"type": "searchapi",
"path": "searchapi_node1/logs",
"file": "access.log",
"unit": "Hours"
},
{
"type": "searchapi",
"path": "searchapi_node2/logs",
"file": "access.log",
"unit": "Hours"
}
]
}
SearchApiLogParser, IndexerLogParser는 LogParser를 상속받아서 Parsing 함수를 로그의 형식에 맞게 파싱 부분을 구현하였습니다.
// custom parser
var metric = model.Metric{}
if logType == "searchapi" {
p := parser.SearchApiLogParser{}
metric = p.Parsing(line.Text)
} else if logType == "indexer" {
p := parser.IndexerLogParser{}
metric = p.Parsing(line.Text)
} else {
p := parser.LogParser{}
metric = p.Parsing(line.Text)
}
수집한 로그 데이터와 API로 제공해야할 데이터가 동기화 문제가 발생하지 않도록 sync.Map을 사용하여 처리하였습니다.
var Registry = sync.Map{}
측정 방안
시계열 데이터를 수집하고 제공하기 위해서 API를 호출한 시간 이전의 측정 단위를 제공하도록 구성하였습니다.
예를 들어서 측정 단위가 1분 일 때
17시 40분 37초 에 API를 호출하게 되면, 17시 39분 00초 ~ 59초 가공하여 데이터 제공 합니다.
동적색인 소요시간 측정은 (구성도의 start time, latency time 참고)
동적색인 요청을 받고 rabbitmq에 push 할 때 property 에 현재 시간을 timestamp 에 넣고,
꺼내서 처리 할 때의 시간을 체크하여 동적색인이 처리 되기까지 소요시간(대기시간)을 측정 합니다.
매트릭 스케줄러
매트릭 스케줄러는 설정한 시간 주기로 정보 습득하여 influxDB에 저장을 합니다.
rabbitmq, 로그 스크랩, ElasticSearch 정보를 습득하기 위해서 API 호출하고 주기적으로 실행하기 위하여 크론 스케줄을 사용합니다.
추가 정보를 편리하게 습득하여 저장 할 수 있도록 확장성을 고려하여 cron job 설정만 추가하면 되도록 설계 하였습니다.
설정 내용)
addr 는 매트릭 스케줄을 조회, 시작, 중지, 수정 할 수 있도록 API를 제공합니다.
jobs[] 수집할 데이터의 작업 스케줄 단위 입니다.
name은 스케줄의 key로 사용됩니다.
url은 정보를 습득할 API url을 token 인증을 사용하는 경우 token을 넣어줍니다.
cron 에는 스케줄 주기를 기입합니다.
measurement 는 influxDB 에서 사용되는 개념으로 RDB의 table 과 유사합니다.
mappings 은 습득한 API 정보를 influxDB 컬럼에 맵핑을 세팅합니다.
api_field 는 api의 필드를 field 는 influxDB의 필드
ex. messages_ready(rabbitmq_api.api_field) -> count(influxDB.field)
datasource 는 influxdb 정보를 넣어줍니다.
{
"addr": "0.0.0.0:9010",
"jobs": [
{
"name": "rabbitmq",
"url": "rabbitmq.danawa.com/api/queues",
"token": "token",
"cron": "0 */1 * * * *",
"measurement": "rabbitmq",
"mappings": [
{"field": "name", "api_field": "name", "tag": true, "default_value": ""},
{"field": "count", "api_field": "messages_ready", "tag": false}
]
},
{
"name": "dynamic",
"url": "logscrap.danawa.com:9000/metrics",
"token": "",
"cron": "0 */1 * * * *",
"measurement": "dynamic",
"mappings": [
{"field": "name", "api_field": "name", "tag": true, "default_value": ""},
{"field": "count", "api_field": "count", "tag": false},
{"field": "latency", "api_field": "time", "tag": false}
]
},
{
"name": "elasticsearch",
"url": "es.danawa.com/_cat/indices/?format=json",
"token": "",
"cron": "0 0 */1 * * *",
"measurement": "elasticsearch",
"mappings": [
{"field": "name", "api_field": "index", "tag": true, "default_value": ""},
{"field": "count", "api_field": "docs.count", "tag": false}
]
}
],
"datasource": {
"url": "influxdb.danawa.com",
"username": "",
"password": "",
"database": "danawa"
}
}
go cron 은 github.com/robfig/cron 활용하고
influxDB 는 github.com/influxdata/influxdb-client-go 를 사용했습니다.
로그 스크랩, 매트릭 스케줄러, influxDB 모두 docker(도커)로 구성 되어있습니다.
그라파나로 구성한 대시보드
대시보드는 검색API를 모니터링 하던 prometheus를 사용하고 동적색인, ElasticSearch 는 influxDB를 사용하여 grafana 대시보드를 구성하였습니다.
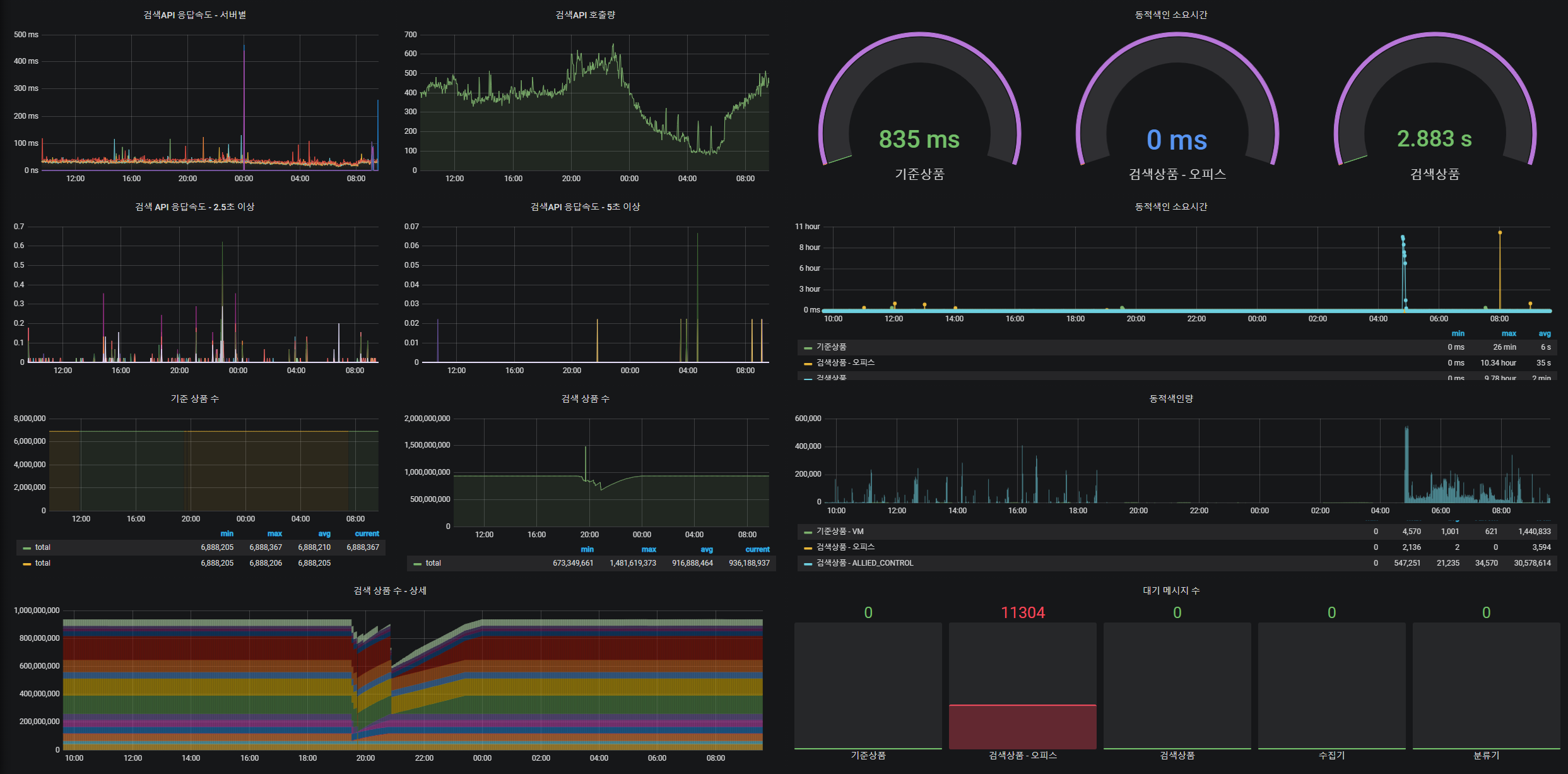
정리
검색을 운영하면서 한 눈에 전반적인 상황을 파악하기 좋도록 모니터링 시스템을 구축해 보았습니다. 이상 증후를 바로 파악하기도 쉽고, 상품 수가 1년 동안 얼마나 증가 했는지 추이를 파악하기도 편리해졌습니다. 제일 좋은 점은 데이터 분석할 때 대시보드에서 기간 및 시간 설정으로 다양한 데이터를 동시에 볼 수 있는 점 입니다. 예를 들면, 1년 동안 상품 수 증가와 검색 속도의 증가 추이의 연관성을 동시에 볼 수 있습니다. 그리고 신규 서비스 또는 항목을 모니터링 대상에 추가하고 싶다면 로그 기록과 간단한 설정 추가로 그라파나 대시보드에 시각화할 수 있습니다. 기본적인 내용만 대시보드에 추가했지만, 좀 더 자세히 보고 싶을 때는 그라파나 패널을 추가해서 상세하게 볼 수 있습니다. 검색 말고 다양한 서비스를 관리하고 담당하시는 개발자 분들에게도 모니터링 시스템을 구성할 때 도움이 되었으면 좋겠습니다. 외부에서 문의가 자주 오는 항목을 대시보드로 구성해 놓아도 좋겠다고 생각했습니다.